Sales 360 Data Product Example: StrideRight Shoes¶
Overview¶
Company Background
StrideRight Shoes is a leading manufacturer and retailer specializing in high-quality footwear for various demographics, from children to adults. With a commitment to comfort, style, and durability, StrideRight Shoes aims to provide exceptional customer experiences both online and in-store.
Challenges Faced
StrideRight Shoes experienced significant operational challenges, including quality issues, late deliveries, and sampling delays. These issues impacted sales effectiveness and customer satisfaction, highlighting the need for streamlined operations and improved customer engagement strategies.
Vision
To revolutionize the footwear industry by leveraging advanced data analytics enhancing operational efficiency, and delivering personalized customer experiences that drive engagement, loyalty, and sustainable growth.
Goals and Objectives
-
Increase Customer engagement and lower churn rate: Understand customer preferences and provide personalized recommendations and targeted marketing campaigns.
-
Operational Excellence: Streamline operations to ensure timely deliveries, maintain high-quality standards, and optimize inventory management.
-
Maximize revenue from high-value customers. Integrate and analyze customer interaction and transaction data to derive actionable insights and stay ahead of market trends.
Use-cases
-
Personalized Marketing Campaigns: Tailor marketing efforts using customer data to create personalized recommendations and targeted campaigns.
-
Customer Churn Prediction: Identify at-risk customers with predictive models and implement retention strategies to reduce churn.
-
Sales Performance Analysis: Monitor and analyze sales data through interactive dashboards to identify trends and optimize marketing strategies.
Solution
Sales 360 Data Product: The Sales 360 data product is a structured dataset that contains comprehensive information about various entities within the organization. It serves as a central repository for product data, facilitating efficient management, analysis, and decision-making processes related to product operations, logistics, and customer engagement.
Source Aligned Data Product¶
Pre-requisites
To create the Data Product within DataOS, make sure you have:
-
Necessary permissions to create and manage Data Products.
-
Basic understanding of Data Product principles and lifecycle management.
Design Phase¶
The individual responsible for designing the Sales 360 data product is the Data Product Owner.
Define entities and schema¶
For our use case, we define the following entities: Customer, Product, Transaction, Order and Channel.
Data Understanding and Exploration¶
To plan things in the design phase, we need to first look up at the various data that is going to be integrated and will be making Sales360 data product.
For this project, we aim to create a Sales 360 data product that will integrate various tables from BigQuery sources. These sources must be connected to DataOS using Depot.
Create a Depot
Creating a bigquery depot with json file of the credentials of the client's warehouse.
bigquery depot manifest file
version: v1
name: "bigquery"
type: depot
tags:
- dropzone
- bigquery
layer: user
depot:
type: BIGQUERY
description: "Google Cloud BigQuery"
spec:
project: dataos-ck-res-yak-dev
external: true
connectionSecret:
- acl: rw
type: key-value-properties
files:
json_keyfile: ./secrets/gcs-bq.json
Extract the Metadata
To explore the metadata of the tables you can run a scanner. You can then access the metadata on Metis UI. The Scanner manifest file is shown below:
scanner manifest file
version: v1
name: scan-depot
type: workflow
tags:
- Scanner
title: Scan snowflake-depot
description: |
The purpose of this workflow is to scan S3 Depot.
workflow:
dag:
- name: scan-snowflake-db
title: Scan snowflake db
description: |
The purpose of this job is to scan gateway db and see if the scanner works fine with an S3 type of depot.
tags:
- Scanner
spec:
stack: scanner:2.0
compute: runnable-default
stackSpec:
depot: bigquery # depot name
Explore the Data
Now for data exploration, you can query the data using the workbench. To query the data on the workbench without moving the data you first need to create a Minerva or a Themis cluster that will target the bigquery Depot. By applying the below manifest file, you can create the cluster.
cluster manifest file
To interact with the newly created bqcluster Cluster in Workbench:
- Access the Cluster: Open Workbench and select the
bqclustercluster. - Execute Queries: Choose the catalog, schema, and tables, then run your query using the 'Run' button.
- Retrieve Results: View the query results in the pane below the input area.
For more details, refer to the Workbench documentation.
Data Product Architectural Design¶
Once you've explored the data, the next step is to plan the architectural design. For example, In our case, the Data Sources is Bigquery and to connect with this source we will need to create Depots. The flare job will then use this depot and will facilitate easy ingestion and transformation from source to lakehouse. After ingestion, the data will must go through profiling and pass all the defined quality checks we will discuss this in detail in Build Phase. Then our data product will be ready to be used in a Analytical Platform.
Data Product Prototype¶
Here we will define our Input, Output, Transformations and SLOs.
-
Input acts as an intermediary connecting diverse data sources. You can define as many input ports as you would like for each database. Here our input is
bigquerydepot. -
Transformation is where you enrich the data to make it more usable accurate and reliable. The stack we used for transformation is
flare. The transformation stops involved were:-
Read Input from BigQuery: Ingest raw data as is from Bigquery, with the only transformation being the conversion of cases to lower case.
-
Joined Customer and Transaction Tables: Integrated data from the Customer and Transaction tables to identify customer-churn.
-
Orders enriched table Integrated data from Customer, Product, Transaction and Orders table to create a Orders-enriched table.
-
-
Output is defined as our complete data product which is our order enriched table ready to be consumed and can also be delivered to different platforms for different purpose like streamlit for creating data applications and superset for data visualization, and lens for data modeling.
-
Streamlit App: for customer churn details.
-
Sales 360 Lens: Data model for StrideRight Shoes sales intelligence and sales analysis.
-
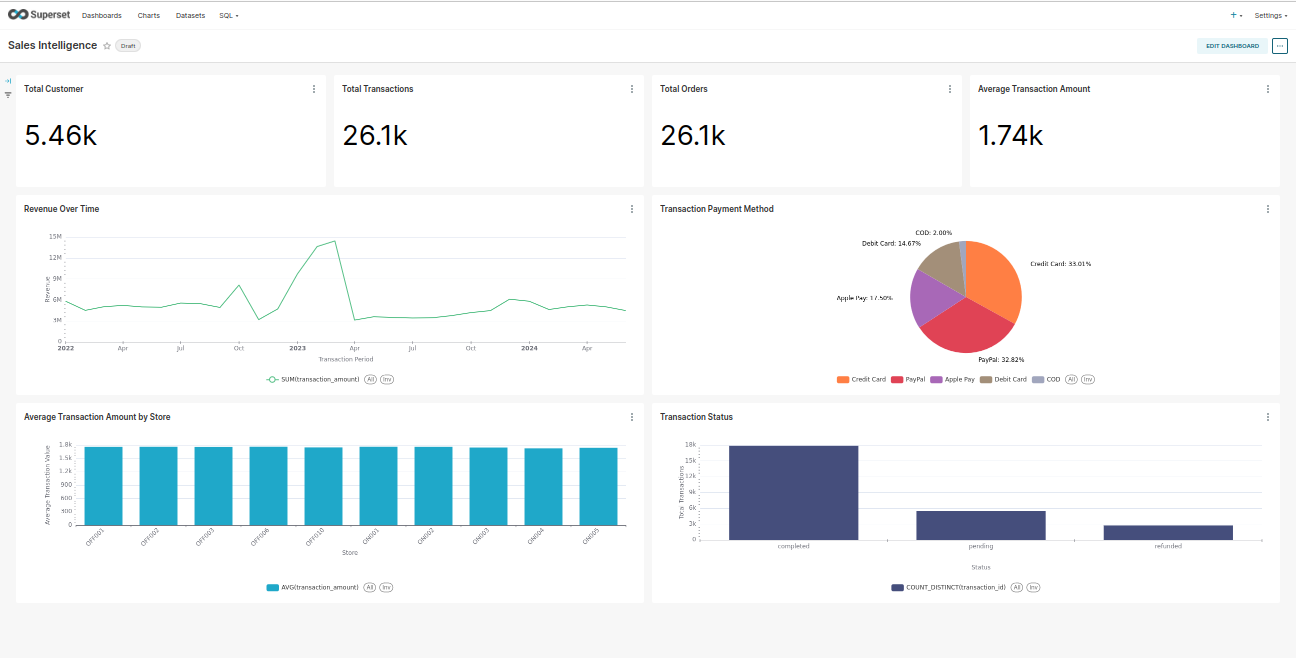
Superset Dashboard Sales intelligence dashboard.
-
-
SLOs: Defining quality and profiling expectations and access related conditions are defined here.
name: sales360-dp
version: v1alpha
type: data
tags:
- dataos:type:sales_analytics
- Readiness.Ready to use
- Type.Internal Data Product
- Tier.Gold
- aeo-pov
- "Domain.Sales"
description: The products dataset is essential for managing and analyzing a wide range of organizational products efficiently. It acts as a centralized hub, providing comprehensive details crucial for operations, logistics, and customer interactions. This structured repository supports informed decision-making by offering insights into product performance, inventory management, and customer preferences. Businesses can utilize this data to streamline operations, optimize supply chains, and enhance customer satisfaction through targeted strategies. By leveraging these insights, organizations can effectively align their product offerings with market demands, driving growth and maintaining competitive advantage in the marketplace.
purpose: The products data product is a structured dataset that contains comprehensive information about various products within the organization. It serves as a central repository for products data, facilitating efficient management, analysis, and decision-making processes related to products operations, logistics, and customer engagement.
owner: iamgroot
collaborators:
- iamgroot
- loki
refs:
- title: sales_intelligence_lens
href: https://liberal-donkey.dataos.app/lens/app/schema/sales_intelligence
- title: sales_intelligence_dashboard
href: https://liberal-donkey-superset.dataos.app/superset/dashboard/204
- title: sales_intelligence_app
href: https://liberal-donkey.dataos.app/sales-analysis/
entity: product
v1alpha:
data:
useCases:
- Sales Intelligence
resources:
- description: products Dataset Ingestion Piplines
purpose: build the data product's data set
type: workflow
version: v1
refType: dataos
name: wf-order-enriched-data
workspace: public
inputs:
- description: A data product for customer that optimizes customer management using real-time data and advanced analytics for accurate demand forecasting.
purpose: source
refType: dataos
ref: dataos://lakehouse:sales_analytics/customer
- description: A data product for customer that optimizes customer management using real-time data and advanced analytics for accurate demand forecasting.
purpose: source
refType: dataos
ref: dataos://bigquery:sales_360/transaction_data
- description: orders
purpose: source
refType: dataos
ref: dataos://bigquery:sales_360/orders
- description: A data product for products that optimizes products management using real-time data and advanced analytics for accurate demand forecasting.
purpose: source
refType: dataos
ref: dataos://bigquery:sales_360/product
outputs:
- description: A data product for products that optimizes products management using real-time data and advanced analytics for accurate demand forecasting.
purpose: source
refType: dataos
ref: dataos://lakehouse:sales_analytics/order_enriched
Data Product Scanner¶
data-product scanner
version: v1
name: wf-data-product-scanner
type: workflow
tags:
- dataproduct
description: The task involves scanning the schema from the data product and registering the data into Metis.
workflow:
dag:
- name: data-product-scanner
description: The task involves scanning the schema from the data product and registering the data into Metis.
spec:
tags:
- dataproduct
stack: scanner:2.0
compute: runnable-default
stackSpec:
type: data-product
sourceConfig:
config:
type: DataProduct
markDeletedDataProducts: true
dataProductFilterPattern:
includes:
- customer-sales-dp
- products-sales-dp
- transactions-sales-dp
- churn-customer-dp
- sales360-dp
Now, you can see your newly created data product in DPH
Performance target¶
-
Response Time Goals: Achieve 95% of queries processed within 500 milliseconds.
-
Throughput Targets: Sustain 1000 tasks per minute during peak periods.
-
Resource Utilization Limits: Ensure CPU usage remains below 80%.
-
Quality Metrics: Maintain data accuracy at 99%.
-
Scalability Objectives: Accommodate a 50% increase in data volume without additional infrastructure.
Availability Standards: Achieve 99.99% uptime monthly.
These targets guide system design and optimization efforts, ensuring technical capabilities meet business requirements for consistent performance and reliability.
Validation and Iteration¶
After finalizing the design of the Data Product, it undergoes review sessions with key stakeholders and team members to verify compliance with defined requirements and goals. All modifications made during this phase are recorded to facilitate ongoing enhancements to the design.
Once the design aligns with requirements, the subsequent phase focuses on developing the Data Product.
Build Phase¶
This section involves the building and creating resources and stacks and all other capabilities of DataOS to fulfill the design phase requirements.
From the design phase and Data Product Architectural Design, it is clear which DataOS resources we require to build the Data Product, and these are Depot, Cluster, Scanner, Flare, Monitor, Pager, SODA. Let’s see how to create each one step by step. As we already explored the data we’ll directly jump into the data transformation step using Flare.
Data Ingestion and Transformation¶
Ingesting and transforming following tables:
- Transaction
- Customer
- Product
using super dag where the only transformation is to change the case to lower case of all.
version: v1
name: wf-sales-analysis-ingestion-pipeline
type: workflow
tags:
- Tier.Gold
- company.company
description: The ' wf-manufacturing-analysis-ingestion-pipeline' is a data pipeline focused on managing and analyzing company data, particularly contact information. It involves stages such as data ingestion, cleaning, transformation, and quality assurance to derive insights for enhancing manufacturing efficiency and supporting various business processes.
workflow:
title: Company Detail Ingestion Pipeline
dag:
- name: customer-data-ingestion
file: data_product_template/sales_360/transformation/config-customer-flare.yaml
retry:
count: 2
strategy: "OnFailure"
- name: product-data-ingestion
file: data_product_template/sales_360/transformation/config-products-flare.yaml
retry:
count: 2
strategy: "OnFailure"
dependencies:
- customer-data-ingestion
- name: transaction-data-ingestion
file: data_product_template/sales_360/transformation/config-transactions-flare.yaml
retry:
count: 2
strategy: "OnFailure"
dependencies:
- product-data-ingestion
- name: customer-churn-data-ingestion
file: data_product_template/sales_360/transformation/config-transactions-flare.yaml
retry:
count: 2
strategy: "OnFailure"
dependencies:
- transaction-data-ingestion
Here are the all mentioned ingested manifest files:
All ingested manifest files
version: v1
name: wf-customer-ingestion
type: workflow
tags:
- demo.customer
- Tier.Gold
- Domain.Sales
description: This workflow is responsible for ingesting customer for analysis and insights from poss3 into Lakehouse.
workflow:
title: customer Ingestion Workflow
dag:
- name: customer-ingestion
description: This workflow is responsible for ingesting customer for analysis and insights from poss3 into Lakehouse.
title: customer Ingestion Workflow
spec:
tags:
- demo.customer
stack: flare:4.0
compute: runnable-default
stackSpec:
driver:
coreLimit: 1200m
cores: 1
memory: 1024m
executor:
coreLimit: 1200m
cores: 1
instances: 1
memory: 1024m
job:
explain: true
inputs:
- name: customer_input
dataset: dataos://crmbq:sales_360/customer_data?acl=rw
format: Iceberg
logLevel: INFO
outputs:
- name: customer_final_dataset
dataset: dataos://lakehouse:sales_analytics/customer_data?acl=rw
format: Iceberg
description: The customer table is a structured dataset that contains comprehensive information about various customer within the organization. It serves as a central repository for customer data, facilitating efficient management, analysis, and decision-making processes related to customer operations, logistics, and customer engagement.
tags:
- demo.customer
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
title: customer set Ingestion
steps:
- sequence:
- name: customer_final_dataset
sql: |
select * from customer_input
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
transactions manifest file
version: v1
name: wf-transaction-ingestion
type: workflows
tags:
- demo.transaxtion
- Tier.Gold
- Domain.Sales
description: This workflow is responsible for ingesting transaxtion for analysis and insights from poss3 into Lakehouse.
workflow:
title: transaxtion Ingestion Workflow
dag:
- name: transaxtion-ingestion
description: This workflow is responsible for ingesting transaxtion for analysis and insights from poss3 into Lakehouse.
title: transaxtion Ingestion Workflow
spec:
tags:
- demo.transaxtion
stack: flare:4.0
compute: runnable-default
stackSpec:
driver:
coreLimit: 1200m
cores: 1
memory: 1024m
executor:
coreLimit: 1200m
cores: 1
instances: 1
memory: 1024m
job:
explain: true
inputs:
- name: transaction_input
dataset: dataos://crmbq:sales_360/transaction_data?acl=rw
format: Bigquery
logLevel: INFO
outputs:
- name: transaction_final_dataset
dataset: dataos://lakehouse:sales_analytics/transaction_data?acl=rw
format: Iceberg
description: The transaxtion table is a structured dataset that contains comprehensive information about various transaxtion within the organization. It serves as a central repository for transaxtion data, facilitating efficient management, analysis, and decision-making processes related to transaxtion operations, logistics, and transaxtion engagement.
tags:
- demo.transaction
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
title: transaxtion set Ingestion
steps:
- sequence:
- name: transaction_final_dataset
sql: |
select * from transaction_input
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
products manifest file
version: v1
name: wf-products-ingestion
type: workflow
tags:
- demo.products
- Tier.Gold
- Domain.Sales
description: This workflow is responsible for ingesting products for analysis and insights from poss3 into Lakehouse.
workflow:
title: products Ingestion Workflow
dag:
- name: products-ingestion
description: This workflow is responsible for ingesting products for analysis and insights from poss3 into Lakehouse.
title: products Ingestion Workflow
spec:
tags:
- demo.products
stack: flare:4.0
compute: runnable-default
stackSpec:
driver:
coreLimit: 1200m
cores: 1
memory: 1024m
executor:
coreLimit: 1200m
cores: 1
instances: 1
memory: 1024m
job:
explain: true
inputs:
- name: product_data
dataset: dataos://snowflake:public/product
format: snowflake
options:
sfWarehouse: "compute_wh"
logLevel: INFO
outputs:
- name: products_final_dataset
dataset: dataos://lakehouse:sales_analytics/products?acl=rw
format: Iceberg
description: The products table is a structured dataset that contains comprehensive information about various products within the organization. It serves as a central repository for products data, facilitating efficient management, analysis, and decision-making processes related to products operations, logistics, and customer engagement.
tags:
- demo.products
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
title: products set Ingestion
steps:
- sequence:
- name: products_final_dataset
sql: |
SELECT
*
FROM
products_input
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
customer-churn manifest file
version: v1
name: wf-customer-churn-ingestion
type: workflow
tags:
- demo.customer
- Tier.Gold
- Domain.Sales
description: This workflow is responsible for ingesting customer for analysis and insights from Bigquery into Lakehouse.
workflow:
title: customer Ingestion Workflow
dag:
- name: customer-ingestion
description: This workflow is responsible for ingesting customer for analysis and insights from Bigquery into Lakehouse.
title: customer Ingestion Workflow
spec:
tags:
- demo.customer
stack: flare:4.0
compute: runnable-default
stackSpec:
driver:
coreLimit: 1200m
cores: 1
memory: 1024m
executor:
coreLimit: 1200m
cores: 1
instances: 1
memory: 1024m
job:
explain: true
inputs:
- name: transactions_input
dataset: dataos://bigquery:sales_360/transaction_data?acl=rw
- name: customer_input
dataset: dataos://lakehouse:sales_360/customer?acl=rw
format: Iceberg
logLevel: INFO
outputs:
- name: customer_final_dataset
dataset: dataos://lakehouse:sales_360/customer_churn?acl=rw
format: Iceberg
description: The customer table is a structured dataset that contains comprehensive information about various customer within the organization. It serves as a central repository for customer data, facilitating efficient management, analysis, and decision-making processes related to customer operations, logistics, and customer engagement.
tags:
- demo.customer
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
title: customer set Ingestion
steps:
- sequence:
- name: customer_final_dataset
sql: |
WITH customer_activity AS (
SELECT
c.customer_id,
MAX(t.transaction_date) AS last_transaction_date
FROM
customer_input c
LEFT JOIN
transactions_input t ON cast(c.customer_id as string) = t.customer_id
GROUP BY
c.customer_id
)
SELECT
CASE
WHEN last_transaction_date < DATE_SUB(CURRENT_DATE, 90) THEN 'Churned'
ELSE 'Not Churned'
END AS churn_status,
COUNT(*) AS customer_count
FROM
customer_activity
GROUP BY
CASE
WHEN last_transaction_date < DATE_SUB(CURRENT_DATE, 90) THEN 'Churned'
ELSE 'Not Churned'
END
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
orders-enriched manifest file
version: v1
name: wf-order-enriched-data
type: workflow
tags:
- company.order_enriched
- Tier.Gold
- Domain.Finance
description: The job is to ingest order enriched data for company StrideRight Shoes from Bigquery Source to Lakehouse.
workflow:
dag:
- name: order-enriched-data
description: The job is to ingest order enriched data for company StrideRight Shoes from Bigquery Source to Lakehouse.
spec:
tags:
- company.order_enriched
stack: flare:4.0
compute: runnable-default
stackSpec:
driver:
coreLimit: 2200m
cores: 2
memory: 2824m
executor:
coreLimit: 3200m
cores: 2
instances: 2
memory: 4024m
job:
explain: true
inputs:
- name: transactions
dataset: dataos://bigquery:sales_360/transaction?acl=rw
options:
driver: org.postgresql.Driver
- name: order_data
dataset: dataos://bigquery:sales_360/order_data?acl=rw
options:
driver: org.postgresql.Driver
- name: order_line_item
dataset: dataos://bigquery:sales_360/order_line_item?acl=rw
options:
driver: org.postgresql.Driver
- name: product
dataset: dataos://bigquery:sales_360/product?acl=rw
options:
driver: org.postgresql.Driver
- name: customer
dataset: dataos://bigquery:sales_360/customers?acl=rw
logLevel: INFO
outputs:
- name: final
dataset: dataos://lakehouse:sales_analytics/order_enriched?acl=rw
format: Iceberg
description: The "order_enriched" table contains a dataset that has been augmented with additional information to provide deeper insights or to support more comprehensive analyses. This enrichment process involves integrating supplementary data from various sources or applying data transformation and enhancement techniques to the original dataset. Here are some common characteristics of an enriched table.
tags:
- company.order_enriched
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
title: order enriched data
steps:
- sequence:
- name: transaction
sql: |
SELECT
transaction_id,
customer_id,
transaction_date,
order_id,
transaction_amount,
payment_method
FROM
transactions
WHERE
transaction_date <= CURRENT_TIMESTAMP
AND year(transaction_date) = 2024
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
- name: orders
sql: |
SELECT
o.order_id,
customer_id,
o.order_date,
olt.productsku,
order_delivery_date,
order_total_amount,
shipping_method,
order_status
FROM
order_data o
LEFT JOIN order_line_item olt ON o.order_id = olt.order_id
WHERE
o.order_date <= CURRENT_TIMESTAMP
AND year(o.order_date) = 2024
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
- name: order_trans
sql: |
SELECT
o.order_id,
o.customer_id,
o.productsku ,
o.order_date,
order_delivery_date,
order_total_amount,
shipping_method,
order_status,
transaction_id,
transaction_date,
transaction_amount,
payment_method,
product_category,
model_name,
brand_name,
product_name,
product_size
FROM
orders o
LEFT JOIN transaction t ON o.order_id = t.order_id
LEFT JOIN product p ON o.productsku = p.sku_id
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
- name: final
sql: |
SELECT
order_id,
ot.customer_id,
productsku ,
cast(order_date as timestamp) as order_date,
cast(order_delivery_date as timestamp) as order_delivery_date,
cast(order_total_amount as double) as order_total_amount,
shipping_method,
order_status,
transaction_id,
cast(transaction_date as timestamp) as transaction_date,
cast(transaction_amount as timestamp) as transaction_amount,
payment_method,
product_category,
model_name,
brand_name,
product_name,
product_size,
first_name,
last_name,
gender,
phone_number,
email_id,
cast(age as int) as age,
city,
state,
country,
zip_code
FROM
order_trans ot
LEFT JOIN customer c ON ot.customer_id = c.customer_id
functions:
- name: cleanse_column_names
- name: change_column_case
case: lower
Data Profiling¶
After Ingestion and transformation, it's necessary that we perform profiling and quality checks on our data as designed in the design phase.
version: v1
name: wf-operational-analysis-profile-v1-pipeline
type: workflow
tags:
- Tier.Gold
- company.company
description: The ' wf-operational-analysis-profile-pipeline' is a data pipeline focused on managing and analyzing company data, particularly contact information. It involves stages such as data profile, cleaning, transformation, and quality assurance to derive insights for enhancing operational efficiency and supporting various business processes.
workflow:
schedule:
cron: '*/60 * * * *'
concurrencyPolicy: Forbid
title: Company Detail profile Pipeline
dag:
- name: customer-data-profile
file: data_product_template/sales_360/profiling/config-customer-profile.yaml
retry:
count: 2
strategy: "OnFailure"
- name: product-data-profile
file: data_product_template/sales_360/profiling/products-profile.yamll
retry:
count: 2
strategy: "OnFailure"
dependencies:
- customer-data-profile
- name: transaction-data-profile
file: data_product_template/sales_360/profiling/config-transactions-profile.yaml
retry:
count: 2
strategy: "OnFailure"
dependencies:
- product-data-profile
All profiling manifest files
name: profile-checks-alerts
version: v1alpha
type: monitor
tags:
- dataos:type:resource
- dataos:layer:user
description: Alerts ..! we have detected null values in your data please verify
layer: user
monitor:
schedule: '*/1 * * * *'
type: equation_monitor
equation:
leftExpression:
queryCoefficient: 1
queryConstant: 0
query:
type: trino
cluster: system
ql:
with cte as (
SELECT
created_at,
field,
analyzer_name,
round(result,2) * 100 as missing_percentage,
concat(depot,':',collection,':',dataset) as dataset
FROM
lakehouse.sys01.profiles
WHERE
analyzer_name = 'Missing'
and result > 0 and created_at >= CAST(((SELECT CURRENT_TIMESTAMP()) AS TIMESTAMP) - INTERVAL '5' MINUTE)
select missing_percentage from cte
rightExpression:
queryCoefficient: 1
queryConstant: 0
operator: greater_than
incident:
name: profile-check-fail
severity: high
incident_type: profile-quality
transactions-profile manifest file
version: v1
name: wf-transactions-profile
type: workflow
tags:
- demo.transactions
description: The job involves performing a thorough and detailed statistical analysis, including data profiling, of extensive raw transactions data using the advanced features of the DataOS platform.
workflow:
dag:
- name: transactions-profile
spec:
stack: flare:4.0
compute: runnable-default
persistentVolume:
name: persistent-v
directory: fides
stackSpec:
driver:
coreLimit: 2100m
cores: 2
memory: 2448m
executor:
coreLimit: 2200m
cores: 2
instances: 2
memory: 3000Mi
job:
explain: true
inputs:
- name: transactions
dataset: dataos://lakehouse:sales_360/transactions?acl=rw
format: iceberg
incremental:
context: transactions_profile
sql: >
SELECT
*
FROM
transactions_profile
WHERE
transaction_type = 'purchase' AND 1 = $|start|
keys:
- name: start
sql: select 1
logLevel: INFO
profile:
level: basic
sparkConf:
- spark.sql.adaptive.autoBroadcastJoinThreshold: 40m
- spark.executor.heartbeatInterval: 110000ms
- spark.sql.shuffle.partitions: 800
- spark.sql.shuffle.partitions: 600
- spark.dynamicAllocation.shuffleTracking.enabled: true
products-profile manifest file
Data Quality Checks¶
version: v1
name: wf-sales-analytics-quality-pipeline
type: workflow
tags:
- Tier.Gold
- company.company
description: The 'wf-sales-analytics-quality-pipeline' is a data pipeline focused on managing and analyzing company data, particularly contact information. It involves stages such as data quality, cleaning, transformation, and quality assurance to derive insights for enhancing manufacturing efficiency and supporting various business processes.
workflow:
schedule:
cron: '*/5 * * * *'
concurrencyPolicy: Forbid
title: Company Detail quality Pipeline
dag:
- name: customer-data-quality
file: data_product_template/sales_360/quality/customer-quality.yaml
retry:
count: 2
strategy: "OnFailure"
- name: product-data-quality
file: data_product_template/sales_360/quality/product-quality.yaml
retry:
count: 2
strategy: "OnFailure"
dependencies:
- customer-data-quality
- name: transaction-data-quality
file: data_product_template/sales_360/quality/transactions-quality.yaml
retry:
count: 2
strategy: "OnFailure"
dependencies:
- product-data-quality
Here are all the mentioned quality checks manifest files:
All quality-checks manifest file
name: wf-customer-quality
version: v1
type: workflow
tags:
- demo.customer
- Tier.Gold
- Domain.Finance
description: The role involves conducting thorough and detailed quality analysis, including data assertion, of extensive raw customer data using the advanced features of the DataOS platform.
workspace: public
workflow:
dag:
- name: customer-quality
description: The role involves conducting thorough and detailed quality analysis, including data assertion, of extensive raw customer data using the advanced features of the DataOS platform.
spec:
stack: soda+python:1.0
logLevel: INFO
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
stackSpec:
inputs:
- dataset: dataos://lakehouse:sales_360/customer?acl=rw
options:
engine: minerva
clusterName: system
checks:
# - invalid_count(customer_id) = 0:
# valid regex: ^[A-Za-z0-9]{5}$
- invalid_count(gender) <= 0:
valid regex: \b(?:MALE|FEMALE|OTHER)\b
- invalid_percent(email_id) < 10%:
valid regex: ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
- invalid_count(social_class) <= 0:
valid regex: \b(?:Lower Class|Middle Class|Upper Class)\b
- schema:
name: Confirm that required columns are present
warn:
when required column missing: [customer_id, gender, email_id, phone_number]
fail:
when required column missing:
- customer_id
- gender
- email_id
transactions-quality-checks manifest file
name: wf-transactions-quality
version: v1
type: workflow
tags:
- demo.transactions
- Tier.Gold
- Domain.Finance
description: The role involves conducting thorough and detailed quality analysis, including data assertion, of extensive raw transactions data using the advanced features of the DataOS platform.
workspace: public
workflow:
dag:
- name: transactions-quality
description: The role involves conducting thorough and detailed quality analysis, including data assertion, of extensive raw transactions data using the advanced features of the DataOS platform.
title: transactions Quality Assertion
spec:
stack: soda+python:1.0
logLevel: INFO
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
stackSpec:
inputs:
- dataset: dataos://lakehouse:sales_360/transactions?acl=rw
options:
engine: minerva
clusterName: system
checks:
- missing_count(transaction_id) = 0
- missing_count(order_id) = 0
- invalid_count(payment_method) <= 0:
valid regex: \b(?:Credit Card|PayPal|COD|Debit Card|Apple Pay)\b
- invalid_count(transaction_status) <= 0:
valid regex: \b(?:pending|refunded|completed)\b
- invalid_count(shipping_method) <= 0:
valid regex: \b(?:USPS|UPS|FedEx)\b
- schema:
name: Confirm that required columns are present
warn:
when required column missing: [transaction_id, customer_id, order_id]
fail:
when required column missing:
- transaction_amount
- payment_method
- skuid
products-quality-checks manifest file
name: wf-product-quality
version: v1
type: workflow
tags:
- demo.product
- Tier.Gold
- "Domain.Supply Chain"
description: The role involves conducting thorough and detailed quality analysis, including data assertion, of extensive raw product data using the advanced features of the DataOS platform.
workspace: public
workflow:
dag:
- name: product-quality
description: The role involves conducting thorough and detailed quality analysis, including data assertion, of extensive raw product data using the advanced features of the DataOS platform.
title: product Quality Assertion
spec:
stack: soda+python:1.0
logLevel: INFO
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
stackSpec:
inputs:
- dataset: dataos://lakehouse:sales_360/products?acl=rw
options:
engine: minerva
clusterName: system
checks:
- missing_count(skuid) = 0
- duplicate_count(skuid) = 0
- invalid_count(gender) <= 0:
valid regex: \b(?:Male|Female|Unisex)\b
- invalid_count(color) <= 0:
valid regex: \b(?:Gray|Red|White|Black|Blue)\b
- invalid_count(size) <= 0:
valid regex: \b(?:S|XXL|XL|M|L)\b
- invalid_count(productcategory) <= 0:
valid regex: \b(?:Apparel|Footwear)\b
Data Observability¶
Ingestion monitor manifest file
name: workflow-failed-monitor
version: v1alpha
type: monitor
tags:
- dataos:type:resource
- workflow-failed-monitor
description: Attention! The workflow in the Public Workspace has experienced a failure.Please be rest assured,We are currently investigating the cause of the failure.Your patience is appreciated as we work to resolve this issue.Please refer to the logs for additional information.
layer: user
monitor:
schedule: '*/1 * * * *'
type: report_monitor
report:
source:
dataOsInstance:
path: /collated/api/v1/reports/resources/runtime?id=workflow:v1:%25:public
conditions:
- valueComparison:
observationType: workflow-runs
valueJqFilter: '.value[] | {completed: .completed, phase: .phase} | select (.completed | fromdateiso8601 > (now-600)) | .phase'
operator: equals
value: failed
incident:
name: workflowfailed
severity: high
incident_type: workflowruntimefailure
Ingestion pager manifest file
name: workflow-failed-pager
version: v1alpha
type: pager
tags:
- dataos:type:resource
- workflow-failed-pager
description: This is for sending Alerts on Microsoft Teams Maggot Channel.
workspace: public
pager:
conditions:
- valueJqFilter: .properties.name
operator: equals
value: workflowfailed
- valueJqFilter: .properties.incident_type
operator: equals
value: workflowruntimefailure
- valueJqFilter: .properties.severity
operator: equals
value: high
output:
# msTeams:
# webHookUrl: https://rubikdatasolutions.webhook.office.com/webhookb2/fbf5aa12-0d9b-43c9-8e86-ab4afc1fbacf@2e22bdde-3ec2-43f5-bf92-78e9f35a44fb/IncomingWebhook/780096b780594dc6ae39f5ecf1b8bd90/46089f07-1904-4a1b-aa40-665ca6618696
webHook:
url: https://rubikdatasolutions.webhook.office.com/webhookb2/23d5940d-c519-40db-8e75-875f3802e790@2e22bdde-3ec2-43f5-bf92-78e9f35a44fb/IncomingWebhook/433adc9d033e4e8f8ac1b36367f4450f/5d420a71-7170-4d0c-af28-680a98583e58
verb: post
headers:
'content-type': 'application/json'
bodyTemplate: |
{
"@type": "MessageCard",
"summary": "Workflow has Failed",
"themeColor": "0076D7",
"sections": [
{
"activityTitle": "Dear Team,",
"activitySubtitle": "⚠️ Our system detected an issue with the workflow and was unable to complete the process as expected.",
"facts": [
{
"name": " The following workflow has failed:",
"value": "{{ index (splitn ":" 4 .ReportContext.ResourceId) "_2" }}"
},
{
"name": " Failure Time:",
"value": "{{ .CreateTime }}"
},
{
"name": " Severity:",
"value": "{{ .Properties.severity }}"
},
{
"name": " Run Details:",
"value": "<a href=\"https://cheerful-maggot.dataos.app/operations/user-space/resources/resource-runtime?name={{ index (splitn ":" 4 .ReportContext.ResourceId) "_2" }}&type=workflow&workspace=public\">Operation</a>"
},
{
"name": " Logs:",
"value": "<a href=\"https://cheerful-maggot.dataos.app/metis/resources/workflow/dataos.public.{{ index (splitn ":" 4 .ReportContext.ResourceId) "_2" }}/run_history\">Metis</a>"
}
]
},
{
"text": "Schema Change detected !!! \n\n We understand the importance of timely and accurate data processing, and our team is actively working to resolve the issue and get the pipeline back up and running as soon as possible. In the meantime, please be aware that the data processing for the affected workflow may be delayed or incomplete."
},
{
"text": "\n\n"
}
]
}
profiling-monitor manifest file
name: profile-checks-alerts
version: v1alpha
type: monitor
tags:
- dataos:type:resource
- dataos:layer:user
description: Alerts ..! we have detected null values in your data please verify
layer: user
monitor:
schedule: '*/1 * * * *'
type: equation_monitor
equation:
leftExpression:
queryCoefficient: 1
queryConstant: 0
query:
type: trino
cluster: system
ql:
with cte as (
SELECT
created_at,
field,
analyzer_name,
round(result,2) * 100 as missing_percentage,
concat(depot,':',collection,':',dataset) as dataset
FROM
lakehouse.sys01.profiles
WHERE
analyzer_name = 'Missing'
and result > 0 and created_at >= CAST(((SELECT CURRENT_TIMESTAMP()) AS TIMESTAMP) - INTERVAL '5' MINUTE)
select missing_percentage from cte
rightExpression:
queryCoefficient: 1
queryConstant: 0
operator: greater_than
incident:
name: profile-check-fail
severity: high
incident_type: profile-quality
profiling-monitor manifest file
name: profile-failed-pager
version: v1alpha
type: pager
tags:
- dataos:type:resource
- soda-failed-pager
description: This is for sending Alerts on Microsoft Teams Maggot channel
workspace: public
pager:
conditions:
- valueJqFilter: .properties.name
operator: equals
value: profile-check-fail
- valueJqFilter: .properties.incident_type
operator: equals
value: profile-quality
- valueJqFilter: .properties.severity
operator: equals
value: high
output:
email:
emailTargets:
- iamgroot@tmdc.io
- loki@tmdc.io
webHook:
url: https://rubikdatasolutions.webhook.office.com/webhookb2/23d5940d-c519-40db-8e75-875f3802e790@2e22bdde-3ec2-43f5-bf92-78e9f35a44fb/IncomingWebhook/433adc9d033e4e8f8ac1b36367f4450f/5d420a71-7170-4d0c-af28-680a98583e58
verb: post
headers:
'content-type': 'application/json'
bodyTemplate: |
{
"@type": "MessageCard",
"summary": "Alert on profiling Job",
"themeColor": "0076D7",
"sections": [
{
"activityTitle": "Dear Team,",
"activitySubtitle": "⚠️ Our system detected an issue with the data our profiler has detected please check",
"activityImage": "https://adaptivecards.io/content/cats/3.png",
"facts": [
{
"name": "Failure Time:",
"value": "{{ .CreateTime }}"
},
{
"name": "Severity:",
"value": "{{ .Properties.severity }}"
}
]
},
{
"title": "Disclaimer",
"text": "{{ .Monitor.Description }}"
},
{
"text": "Best regards,\n\nThe Modern Data Company"
}
]
}
quality-monitor manifest file
name: soda-checks-alerts
version: v1alpha
type: monitor
tags:
- dataos:type:resource
- dataos:layer:user
description: Alerts ..! recent quality check has resulted in a failure due to ambiguities found in the data. It appears there are inconsistencies or inaccuracies that require your immediate attention. To ensure the integrity and reliability of the data,Your prompt action in addressing these discrepancies will greatly assist us in maintaining the highest standards of quality.
layer: user
monitor:
schedule: '*/30 * * * *'
type: equation_monitor
equation:
leftExpression:
queryCoefficient: 1
queryConstant: 0
query:
type: trino
cluster: system
ql:
WITH cte AS (
SELECT
CASE
WHEN check_outcome = 'fail' THEN 0
ELSE NULL
END AS result,
timestamp
FROM
lakehouse.sys01.soda_quality_checks
WHERE
collection = 'financial_data_companies'
AND dataset IN (
'company_enriched_data_01',
'company_details_master'
)
and check_definition = 'duplicate_count(d_u_n_s) = 0'
AND from_iso8601_timestamp(timestamp) >= (CURRENT_TIMESTAMP - INTERVAL '30' MINUTE)
)
SELECT
DISTINCT result
FROM
cte
WHERE
result IS NOT NULL
rightExpression:
queryCoefficient: 1
queryConstant: 0
operator: equals
incident:
name: soda-check-fail
severity: high
incident_type: soda-quality
quality-pager manifest file
name: quality-failed-pager
version: v1alpha
type: pager
tags:
- dataos:type:resource
description: This is for sending Alerts on Microsoft Teams Maggot channel
workspace: public
pager:
conditions:
- valueJqFilter: .properties.name
operator: equals
value: soda-check-fail
- valueJqFilter: .properties.incident_type
operator: equals
value: soda-quality
- valueJqFilter: .properties.severity
operator: equals
value: high
output:
email:
emailTargets:
- kishan.mahajan@tmdc.io
- deenkar@tmdc.io
- yogesh.khangode@tmdc.io
# msTeams:
# webHookUrl: https://rubikdatasolutions.webhook.office.com/webhookb2/23d5940d-c519-40db-8e75-875f3802e790@2e22bdde-3ec2-43f5-bf92-78e9f35a44fb/IncomingWebhook/433adc9d033e4e8f8ac1b36367f4450f/5d420a71-7170-4d0c-af28-680a98583e58
webHook:
url: https://rubikdatasolutions.webhook.office.com/webhookb2/23d5940d-c519-40db-8e75-875f3802e790@2e22bdde-3ec2-43f5-bf92-78e9f35a44fb/IncomingWebhook/7d2bbe6253494c8a8e216c22b5c9eb49/5d420a71-7170-4d0c-af28-680a98583e58
verb: post
headers:
'content-type': 'application/json'
bodyTemplate: |
{
"@type": "MessageCard",
"summary": "Alert Average temp of sensor has decreased by 1.5x",
"themeColor": "0076D7",
"sections": [
{
"activityTitle": "Dear Team,",
"activitySubtitle": "⚠️ Our system detected an issue with the data quality please check",
"activityImage": "https://adaptivecards.io/content/cats/3.png",
"facts": [
{
"name": " Record Time:",
"value": "{{ .CreateTime }}"
},
{
"name": " Severity:",
"value": "{{ .Properties.severity }}"
}
]
},
{
"title": "Message",
"text": "Quality Check Failure detected !!!\n\n Recent quality check has resulted in a failure due to ambiguities found in the data. It appears there are inconsistencies or inaccuracies that require your immediate attention. To ensure the integrity and reliability of the data,Your prompt action in addressing these discrepancies will greatly assist us in maintaining the highest standards of quality."
},
{
"text": "\n\n"
}
]
}
Deploy Phase¶
Once you've created your data product with all its functionalities and insights, the next step is to ensure it reaches its intended audience through platforms like Metis and the Data Product Hub. To achieve this, running the Scanner becomes crucial.
Monitoring and Iteration Phase¶
After deployment, monitor the Data Product's performance and continue to collect feedback. Iterate the process as needed to achieve the desired results. The improvements can include:
- Enhancing the level of data quality.
- Enriching the schema.
By following these steps, you can continuously improve your Data Product to better meet user needs and business objectives.
Data Products Consumption¶
All the Data Visulaisationa tools such as Superset, PowerBI and Data Modeling tools such as Lens serve as a tool to consume the data products to derive the required actionable insights for which the data product was built.
Building Data Model¶
Create the Lens
Developing a Conceptual Data Model
| Entity | Fields and Dimensions | Derived Dimensions | Measure | Related To | Relationship |
|---|---|---|---|---|---|
| Channel | store_id, store_name, store_address, store_contact_email, store_contact_phone, platform_name, platform_url, country, currency, channel_type, nearest_offline_store | total_stores | |||
| Customer | customer_id, first_name, last_name, gender, phone_number, email_id, birth_date, age, education_level, marital_status, number_of_children, register_date, occupation, annual_income, hobbies, degree_of_loyalty, social_class, mailing_street, city, state, country, zip_code | full_name, age_group | total_customers, average_age | Transaction | 1:N |
| Products | productid, skuid, productname, productcategory, subcategory, gender, price, cost, launchdate, designername, color, size, model | total_products, average_price, total_cost, average_margin | |||
| Transaction | transaction_id, customer_id, transaction_date, order_id, transaction_amount, payment_method, transaction_type, transaction_status, order_delivery_date, discounted_amount, shipping_amount, order_total_amount, discount_percentage, shipping_address, billing_address, promo_code, shipping_method, order_status, skuid, store_id | full_address, transaction_year, transaction_month, transaction_day, order_delivery_duration, discount_applied, shipping_cost_category | total_transactions, total_revenue, average_transaction_amount, total_discounted_amount, total_shipping_amount, total_order_amount, transaction_percentage_with_discount, ups_delivered_percentage, canceled_order_percentage, monthly_revenue_curr, monthly_revenue_prev | Products, Channel | N:1, N:1 |
lens
name: sales_intelligence
contract: sales_intelligence
description: Data Model for New Balance sales intelligence and sales analysis
owner: iamgroot
tags:
- product
- sales
- analysis
entities:
- name: customer
sql:
query: |
SELECT
cast(customer_id as varchar) as customer_id,
first_name,
last_name,
gender,
phone_number,
email_id,
birth_date,
age,
education_level,
marital_status,
number_of_children,
register_date,
occupation,
annual_income,
hobbies,
degree_of_loyalty,
social_class,
mailing_street,
city,
state,
country,
zip_code
FROM
"lakehouse"."sales_analytics".customer
columns:
- name: customer_id
- name: first_name
- name: last_name
- name: gender
- name: phone_number
- name: email_id
- name: birth_date
- name: age
- name: education_level
- name: marital_status
- name: number_of_children
- name: register_date
- name: occupation
- name: annual_income
- name: hobbies
- name: degree_of_loyalty
- name: social_class
- name: mailing_street
- name: city
- name: state
- name: country
- name: zip_code
verified: true
tables:
- schema.customer
fields:
- name: customer_id
description: Unique identifier for the customer
type: string
column: customer_id
primary: true
- name: firstname
description: First name of the customer
type: string
column: first_name
- name: lastname
description: Last name of the customer
type: string
column: last_name
- name: gender
description: Gender of the customer
type: string
column: gender
- name: phonenumber
description: Phone number of the customer
type: string
column: phone_number
- name: emailid
description: Email ID of the customer
type: string
column: email_id
- name: birthdate
description: Birth date of the customer
type: date
column: birth_date
- name: age
description: Age of the customer
type: number
column: age
- name: educationlevel
description: Education level of the customer
type: string
column: education_level
- name: maritalstatus
description: Marital status of the customer
type: string
column: marital_status
- name: numberofchildren
description: Number of children the customer has
type: number
column: number_of_children
- name: registerdate
description: Date when the customer registered
type: string
column: register_date
- name: occupation
description: Occupation of the customer
type: string
column: occupation
- name: annualincome
description: Annual income of the customer
type: string
column: annual_income
- name: hobbies
description: Hobbies of the customer
type: string
column: hobbies
- name: degreeofloyalty
description: Degree of loyalty of the customer
type: string
column: degree_of_loyalty
- name: socialclass
description: Social class of the customer
type: string
column: social_class
- name: mailingstreet
description: Mailing street address of the customer
type: string
column: mailing_street
- name: city
description: City where the customer resides
type: string
column: city
- name: state
description: State where the customer resides
type: string
column: state
- name: country
description: Country where the customer resides
type: string
column: country
- name: zipcode
description: Zip code where the customer resides
type: string
column: zip_code
dimensions:
- name: age_group
type: string
sql_snippet: CASE
WHEN ${customer.age} < 18 THEN 'Under 18'
WHEN ${customer.age} BETWEEN 18 AND 35 THEN '18-35'
WHEN ${customer.age} BETWEEN 36 AND 50 THEN '36-50'
ELSE 'Above 50'
END
description: "Age group of the customer"
- name: full_name
type: string
sql_snippet: CONCAT(${customer.firstname}, ' ', ${customer.lastname})
description: "Full name of the customer"
measures:
- name: total_customers
sql_snippet: ${customer.customer_id}
type: count_distinct
description: Total number of customers
- name: average_age
sql_snippet: AVG(${customer.age})
type: number
description: Average age of the customers
relationships:
- type: 1:N
field: customer_id
target:
name: transaction
field: customer_id
verified: true
- name: product
sql:
query: |
SELECT
productid,
skuid,
productname,
productcategory,
subcategory,
gender,
cast(price as double) as price,
cast(cost as double) as cost,
cast(launchdate as timestamp) as launchdate,
designername,
color,
size,
model
FROM
"lakehouse"."sales_analytics".products
columns:
- name: productid
- name: skuid
- name: productname
- name: productcategory
- name: subcategory
- name: gender
- name: price
- name: cost
- name: launchdate
- name: designername
- name: color
- name: size
- name: model
verified: true
tables:
- schema.product
fields:
- name: productid
description: Unique identifier for the product
type: number
column: productid
primary: true
- name: skuid
description: SKU identifier for the product
type: string
column: skuid
- name: productname
description: Name of the product
type: string
column: productname
- name: productcategory
description: Category of the product
type: string
column: productcategory
- name: subcategory
description: Subcategory of the product
type: string
column: subcategory
- name: gender
description: Gender for which the product is designed
type: string
column: gender
- name: price
description: Price of the product
type: number
column: price
- name: cost
description: Cost of the product
type: number
column: cost
- name: launchdate
description: Launch date of the product
type: date
column: launchdate
- name: designername
description: Name of the designer of the product
type: string
column: designername
- name: color
description: Color of the product
type: string
column: color
- name: size
description: Size of the product
type: string
column: size
- name: model
description: Model of the product
type: string
column: model
measures:
- name: total_products
sql_snippet: ${product.productid}
type: count_distinct
description: Total number of products
- name: average_price
sql_snippet: AVG(${product.price})
type: number
description: Average price of the products
- name: total_cost
sql_snippet: SUM(${product.cost})
type: number
description: Total cost of all products
- name: average_margin
sql_snippet: AVG(${product.price} - ${product.cost})
type: number
description: "Average profit margin per product"
- name: transaction
sql:
query: |
SELECT
transaction_id,
cast(customer_id as varchar) as customer_id,
cast(transaction_date AS timestamp) AS transaction_date,
order_id,
transaction_amount,
payment_method,
transaction_type,
transaction_status,
cast(order_date AS timestamp) AS order_date,
cast(order_delivery_date AS timestamp) AS order_delivery_date,
discounted_amount,
shipping_amount,
order_total_amount,
discount_percentage,
shipping_address,
billing_address,
promo_code,
shipping_method,
order_status,
skuid,
store_id
FROM
"lakehouse"."sales_analytics".transactions
columns:
- name: transaction_id
- name: customer_id
- name: transaction_date
- name: order_id
- name: transaction_amount
- name: payment_method
- name: transaction_type
- name: transaction_status
- name: order_delivery_date
- name: discounted_amount
- name: shipping_amount
- name: order_total_amount
- name: discount_percentage
- name: shipping_address
- name: billing_address
- name: promo_code
- name: shipping_method
- name: order_status
- name: skuid
- name: store_id
verified: true
tables:
- schema.transaction
fields:
- name: transaction_id
description: Unique identifier for the transaction
type: string
column: transaction_id
primary: true
- name: customer_id
description: Unique identifier for the customer
type: string
column: customer_id
- name: transaction_date
description: Date of the transaction
type: date
column: transaction_date
- name: order_id
description: Unique identifier for the order
type: string
column: order_id
- name: transaction_amount
description: Amount of the transaction
type: number
column: transaction_amount
- name: payment_method
description: Method of payment for the transaction
type: string
column: payment_method
- name: transaction_type
description: Type of the transaction
type: string
column: transaction_type
- name: transaction_status
description: Status of the transaction
type: string
column: transaction_status
- name: order_delivery_date
description: Date when the order was delivered
type: date
column: order_delivery_date
- name: discounted_amount
description: Discounted amount on the transaction
type: number
column: discounted_amount
- name: shipping_amount
description: Shipping amount for the transaction
type: number
column: shipping_amount
- name: order_total_amount
description: Total amount for the order
type: number
column: order_total_amount
- name: discount_percentage
description: Percentage of discount on the order
type: string
column: discount_percentage
- name: shipping_address
description: Shipping address for the order
type: string
column: shipping_address
- name: billing_address
description: Billing address for the order
type: string
column: billing_address
- name: promo_code
description: Promo code applied to the order
type: string
column: promo_code
- name: shipping_method
description: Method of shipping for the order
type: string
column: shipping_method
- name: order_status
description: Status of the order
type: string
column: order_status
- name: skuid
description: Unique identifier for the product
type: string
column: skuid
- name: store_id
description: store id
type: string
column: store_id
dimensions:
- name: full_address
type: string
sql_snippet: CONCAT(${transaction.shipping_address}, ' ', ${transaction.billing_address})
description: Concatenation of the shipping and billing address
- name: transaction_year
type: number
sql_snippet: YEAR(${transaction.transaction_date})
description: Year of the transaction
- name: transaction_month
type: number
sql_snippet: MONTH(${transaction.transaction_date})
description: Month of the transaction
- name: transaction_day
type: number
sql_snippet: DAY(${transaction.transaction_date})
description: Day of the transaction
- name: order_delivery_duration
type: number
sql_snippet: date_diff('day',${transaction.transaction_date}, ${transaction.order_delivery_date})
description: Number of days between order date aorder_delivery_datend delivery date
- name: discount_applied
type: bool
sql_snippet: ${transaction.discounted_amount} > 0
description: Indicates if a discount was applied to the transaction
- name: shipping_cost_category
type: string
sql_snippet: CASE
WHEN ${transaction.shipping_amount} = 0 THEN 'Free Shipping'
WHEN ${transaction.shipping_amount} < 10 THEN 'Low Cost Shipping'
ELSE 'High Cost Shipping'
END
description: Category of shipping cost based on the amount
measures:
- name: total_transactions
sql_snippet: ${transaction.transaction_id}
type: count_distinct
description: Total number of transactions
- name: total_revenue
sql_snippet: SUM(${transaction.transaction_amount})
type: number
description: Total revenue from transactions
- name: average_transaction_amount
sql_snippet: AVG(${transaction.transaction_amount})
type: number
description: Average amount per transaction
- name: total_discounted_amount
sql_snippet: SUM(${transaction.discounted_amount})
type: number
description: Total discounted amount on transactions
- name: total_shipping_amount
sql_snippet: SUM(${transaction.shipping_amount})
type: number
description: Total shipping amount for transactions
- name: total_order_amount
sql_snippet: SUM(${transaction.order_total_amount})
type: number
description: Total amount for orders
- name: transaction_percentage_with_discount
sql_snippet: COUNT(CASE WHEN ${transaction.discounted_amount} > 0 THEN 1 END) * 100.0 / (COUNT( ${transaction.transaction_id}))
type: number
description: Percentage of transsaction with discounts
- name: ups_delivered_percentage
sql_snippet: (COUNT(CASE WHEN ${transaction.shipping_method} = 'UPS' AND ${transaction.order_status} = 'Delivered' THEN 1 END) * 100.0 / COUNT( ${transaction.order_id}))
type: number
description: The percentage the orders shipped by fedex and the order status is delivered
- name: canceled_order_percentage
sql_snippet: (COUNT(CASE WHEN ${transaction.order_status} = 'Canceled' THEN 1 END) * 100.0 / COUNT( ${transaction.order_id}))
type: number
description: The percentage of the orders cancelled
relationships:
- type: N:1
field: skuid
target:
name: product
field: skuid
verified: true
- type: N:1
field: store_id
target:
name: channel
field: store_id
verified: true
- name: channel
sql:
query: |
SELECT
*
FROM
"bigquery"."sales_360".channel
columns:
- name: store_id
- name: store_name
- name: store_address
- name: store_contact_email
- name: store_contact_phone
- name: platform_name
- name: platform_url
- name: country
- name: currency
- name: channel_type
- name: nearest_offline_store
tables:
- bigquery.sales_360.channel
fields:
- name: store_id
type: string
description: Unique identifier for each store.
column: store_id
primary : true
- name: store_name
type: string
description: The name of the store.
column: store_name
- name: store_address
type: string
description: The address of the store.
column: store_address
- name: store_contact_email
type: string
description: The contact email for the store.
column: store_contact_email
- name: store_contact_phone
type: string
description: The contact phone number for the store.
column: store_contact_phone
- name: platform_name
type: string
description: The name of the platform.
column: platform_name
- name: platform_url
type: string
description: The URL of the platform.
column: platform_url
- name: country
type: string
description: The country where the store is located.
column: country
- name: currency
type: string
description: The currency used by the store.
column: currency
- name: channel_type
type: string
description: The type of channel (e.g., online, offline).
column: channel_type
- name: nearest_offline_store
type: string
description: The nearest offline store to the current store.
column: nearest_offline_store
measures:
- name: total_stores
sql_snippet: ${channel.store_id}
type: count_distinct
description: Total number of stores available
Building Data Application¶
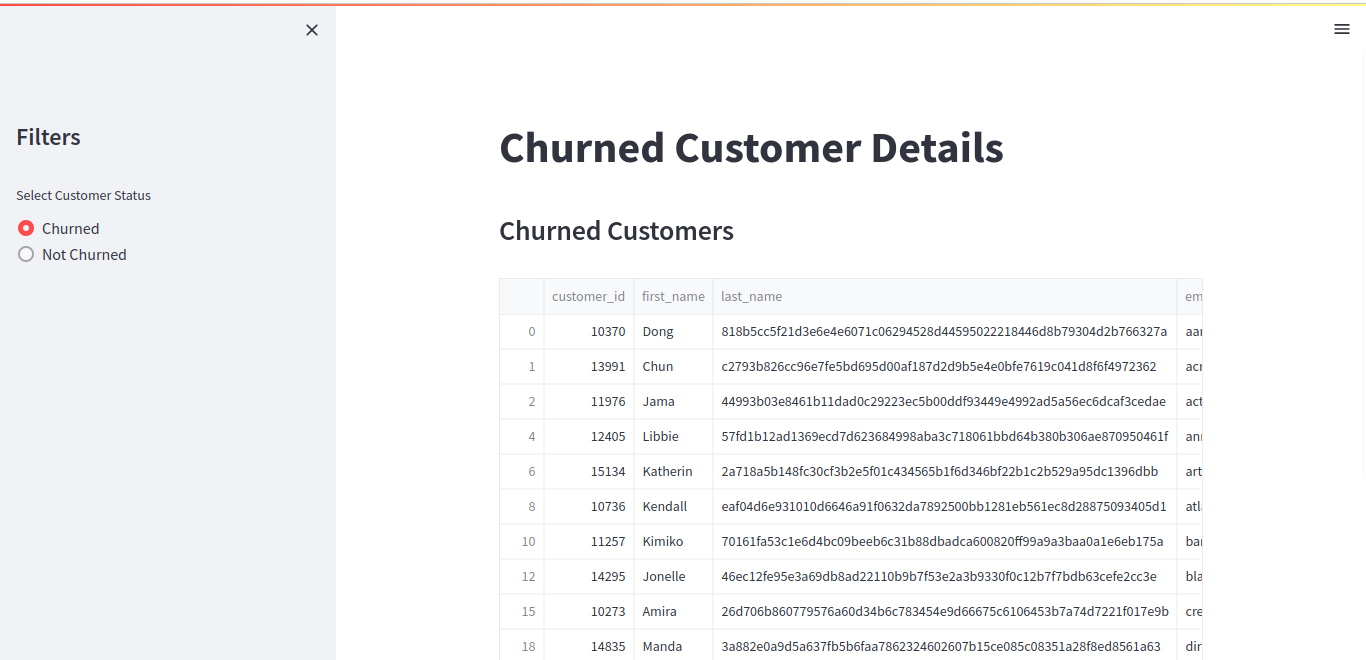
This streamlit app will give you the details of churned and not churned customers so that all the customers who are going to churned can be retained bby contacting them and giving them special discounts.
streamlit-app manifest file
import streamlit as st
import pandas as pd
from trino.dbapi import connect
from trino.auth import BasicAuthentication
from datetime import datetime, timedelta
# Function to fetch data from Trino database based on query
@st.cache(allow_output_mutation=True)
def fetch_data(query):
conn = connect(
host="tcp.liberal-donkey.dataos.app",
port=7432,
auth=BasicAuthentication("aayushisolanki", "dG9rZW5fdXN1YWxseV9wcmV2aW91c2x5X2RpdmluZV9tb25ncmVsLmU4M2EwOWJiLTRmZTMtNGZjMS1iMTY5LWY0NTI2MDgyZDUwZg=="),
http_scheme="https",
http_headers={"cluster-name": "system"}
)
data = pd.read_sql(query, conn)
conn.close()
return data
# Query to fetch churned customers with contact details
churned_customers_query = """
WITH customer_activity AS (
SELECT
c.customer_id,
c.first_name,
c.last_name,
c.email_id,
c.phone_number,
MAX(t.transaction_date) AS last_transaction_date
FROM
lakehouse.sales_360.customer c
LEFT JOIN
lakehouse.sales_360.transactions t ON CAST(c.customer_id AS VARCHAR) = t.customer_id
GROUP BY
c.customer_id, c.first_name, c.last_name, c.email_id, c.phone_number
)
SELECT
c.customer_id,
c.first_name,
c.last_name,
c.email_id,
c.phone_number,
CASE
WHEN ca.last_transaction_date < DATE_FORMAT(CURRENT_DATE - INTERVAL '90' DAY, '%Y-%m-%d') THEN 'Churned'
ELSE 'Not Churned'
END AS churn_status
FROM
lakehouse.sales_360.customer c
LEFT JOIN
customer_activity ca ON c.customer_id = ca.customer_id
"""
# Function to filter churned and not churned customers
def filter_customers(df, churn_status):
filtered_df = df[df['churn_status'] == churn_status]
return filtered_df
# Streamlit UI
def main():
st.title('Churned Customer Details')
# Fetch churned customers data
churned_customers = fetch_data(churned_customers_query)
# Sidebar filter for churn status
st.sidebar.title('Filters')
selected_status = st.sidebar.radio('Select Customer Status', ['Churned', 'Not Churned'])
# Display filtered customer data
st.subheader(f'{selected_status} Customers')
filtered_customers = filter_customers(churned_customers, selected_status)
st.dataframe(filtered_customers)
if __name__ == "__main__":
main()
The Output:
Building Dashboards¶