Soda Stack¶
Soda is a declarative Stack for data quality testing within and beyond data pipelines, extending its capabilities, enhancing data observability and reliability across one or more datasets. It enables you to use the Soda Checks Language (SodaCL) to turn user-defined inputs into aggregated SQL queries.
How to run Soda checks?¶
Create a Workflow/Worker manifest¶
Soda operates as a Stack that can be orchestrated through various Resources, such as a Workflow, or a Worker Resource. The choice of orchestrator-type is contingent upon the specific use case being addressed.
- When dealing with batch workloads for executing quality checks and profiling, opt for the Workflow Resource.
- For long-running, continuous workloads, the recommended choice is the Worker Resource.
For detailed insights into the selection and utilization of the appropriate Resource, please refer to the dedicated documentation for Workflow and Worker Resources.
Code Snippet for Workflow and Worker manifest
Code Snippet for Workflow
# Configuration for Resource meta section
name: soda-workflow # Resource name (mandatory, default: none, possible: any string confirming the regex [a-z0-9]([-a-z0-9]*[a-z0-9]) and length less than or equal to 48 characters)
version: v1 # Manifest version (mandatory, default: none, possible: v1)
type: workflow # Resource-type (mandatory, default: none, possible: workflow)
tags: # Tags (optional, default: none, possible: list of strings)
- workflow
- soda-checks
description: Soda workflow # Resource description (optional, default: none, possible: any string)
workspace: public # Workspace name (optional, default: public, possible: any DataOS Workspace name)
# Configuration for Workflow-specific section
workflow:
dag:
- name: soda-job-v1 # Job name (mandatory, default: none, possible: any string confirming the regex [a-z0-9]([-a-z0-9]*[a-z0-9]) and length less than or equal to 48 characters)
title: Soda checks job # Job title (optional, default: none, possible: any string)
description: Soda job # Job description (optional, default: none, possible: any string)
spec: # Job spec (mandatory)
stack: soda+python:1.0 # Stack name, flavor, and version (mandatory, default: none, value: for soda use soda+python:1.0. Here soda is the stack, python is flavor, and 1.0 is version)
compute: runnable-default # Compute name (mandatory, default: none, possible: runnable-default or any other runnable-type Compute Resource name)
resources: # CPU and memory resources (optional)
requests: # Requested resources (optional)
cpu: 1000m # Requested CPU resources (optional, default: 100m, possible: cpu units in milliCPU(m) or cpu core)
memory: 100Mi # Requested memory resources (optional, default: 100Mi, possible: memory in Mebibytes(Mi) or Gibibytes(Gi))
limits: # Resource limits (optional)
cpu: 400m # CPU resource limits (optional, default: 400m, possible: cpu units in milliCPU(m) or cpu core)
memory: 400Mi # Memory resource limits (optional, default: 400Mi, possible: cpu units in milliCPU(m) or cpu core)
logLevel: INFO # Logging level (optional, default: INFO, possible: INFO / WARNING / ERROR / DEBUG)
# Configuration for Soda Stack-specific section
stackSpec:
# ... attributes specific to Soda Stack are specified here.
To learn more about the attributes of Workflow Resource, refer to the link: Attributes of Workflow YAML.
Code Snippet for Worker
# Configuration for Resource meta section
name: soda-worker # Resource name (mandatory, default: none, possible: any string confirming the regex [a-z0-9]([-a-z0-9]*[a-z0-9]) and length less than or equal to 48 characters)
version: v1beta # Manifest version (mandatory, default: none, possible: v1beta)
type: worker # Resource-type (mandatory, default: none, possible: worker)
tags: # Tags (optional, default: none, possible: list of strings)
- worker
- soda-checks
description: Soda worker # Resource description (optional, default: none, possible: any string)
workspace: public # Workspace name (optional, default: public, possible: any DataOS Workspace name)
# Configuration for Worker-specific section
worker:
replicas: 1 # Number of worker replicas (optional, default: 1, possible: any positive integer)
tags: # Tags (optional, default: none, possible: list of strings)
- sodaworker
stack: soda+python:1.0 # Stack name, flavor, and version (mandatory, default: none, value: for soda use sodaworker+python:1.0. Here sodaworker is the stack, python is flavor, and 1.0 is version)
logLevel: INFO # Logging level (optional, default: INFO, possible: INFO / WARNING / ERROR / DEBUG)
compute: runnable-default # Compute name (mandatory, default: none, possible: runnable-default or any other runnable-type Compute Resource name)
resources: # CPU and memory resources (optional)
requests: # Requested resources (optional)
cpu: 1000m # Requested CPU resources (optional, default: 100m, possible: cpu units in milliCPU(m) or cpu core)
memory: 100Mi # Requested memory resources (optional, default: 100Mi, possible: memory in Mebibytes(Mi) or Gibibytes(Gi))
limits: # Resource limits (optional)
cpu: 400m # CPU resource limits (optional, default: 400m, possible: cpu units in milliCPU(m) or cpu core)
memory: 400Mi # Memory resource limits (optional, default: 400Mi, possible: cpu units in milliCPU(m) or cpu core)
# Configuration for Soda Stack-specific section
stackSpec:
# ... attributes specific to Soda Stack are specified here.
To learn more about the attributes of Worker Resource, refer to the link: Attributes of Worker YAML.
Declare the configuration for Soda stackSpec section¶
The Workflow and Worker Resource comprise of a stackSpec section (or a mapping) that comprises the attributes of the Stack to be orchestrated. In the context of Soda Stack, the StackSpec defines diverse datasets and their associated Soda checks.
The YAML snippet below shows a sample structure of the Soda stackSpec section:
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
options:
engine: minerva
clusterName: miniature
branchName: test
filter:
name: filter_on_age
where: age > 50
checks:
- missing_count(snapshot_id) = 0:
name: Completeness of the Snapshot ID Column #add the name
attributes:
title: Completeness of the Snapshot ID Column
category: Completeness
profile:
columns:
- "*"
This involves the declaration of following parts:
- Declare Input Dataset Address
- Define filters
- Define Soda Checks
- Define columns to be profiled (optional)
- Define Optional configuration
Declaring input dataset address¶
The dataset attribute allows data developer to specify the data source or dataset that requires data quality evaluations. It is declared in the form of a Uniform Data Link [UDL], in the following format: dataos://[depot]:[collection]/[dataset].
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
# ...other input attributes
- dataset: dataos://postgresdb:state/city
# ...other input attributes
Info
When using the Trino engine (Minerva) for compute, ensure that table and schema names in your dataset address are provided in lowercase format. For example:
Trino stores and resolves schema and table identifiers in lowercase. Using uppercase characters (e.g., dataos://sstdepot:LTV/VISIT_COPY) may result in query failures.
When using a data source that provides its own native processing engine (such as Snowflake, BigQuery, etc.) remove the following snippet from your YAML and specify the dataset address as needed:
Define Filters¶
The filter attribute or section works as a global filter for all checks specified within a dataset.
Info
This global filter functionality differs from the filter applied within the checks section.
The following YAML sample demonstrates how the filter section can be employed to apply a global filter on all checks specified within the checks section.
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
filter:
name: filter_on_age
where: age > 50
Defining Soda checks¶
Soda Stack utilizes SodaCL, a YAML-based, low-code, human-readable, domain-specific language for data reliability and data quality management. SodaCL enables data developers to write checks for data quality, then run a scan of the data in the data source to execute those checks.
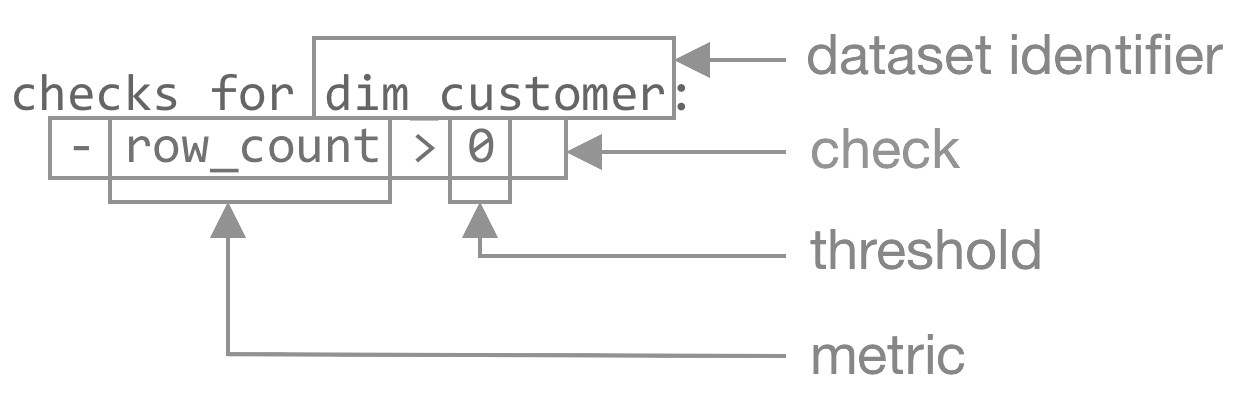
The checks section allows users to specify a list of specific data quality checks or tests that will be performed on the designated dataset. These checks can be tailored to suit the unique requirements of the dataset and the data quality objectives.
Sample Checks Declaration
# Checks for basic validations would be named in `Validity` category
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
checks:
- row_count between 1 and 170:
attributes:
title: Row Count Between 1 and 170
category: Accuracy
- missing_count(customer_no) = 0:
attributes:
category: Completeness
- invalid_percent(customer_name) < 1%:
valid max length: 27
filter: site_number > 0
attributes:
category: Validity
# - invalid_percent(phone) < 1 %:
# valid format: phone number
- invalid_count(number_cars_owned) = 0:
valid min: 1
valid max: 6
attributes:
category: Validity
- duplicate_count(phone) = 0:
attributes:
category: Uniqueness
- invalid_count(site_number) < 0:
valid min: 5
valid max: 98
attributes:
category: Validity
# ...other inputs attributes
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
checks:
- avg(safety_stock_level) > 50:
attributes:
category: Accuracy
# ...other inputs attributes
---
# Check for Freshness would be categorised in `Freshness` category
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
checks:
- freshness(test) < 551d:
name: Freshness01
attributes:
category: Freshness
# ...other inputs attributes
---
# Check for Accuracy Category
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
checks:
- values in (city_name) must exist in city (city_name):
samples limit: 20
attributes:
category: Accuracy
# ...other inputs attributes
Complete Soda Manifest Example
name: soda-customer-checks
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Empowering sales360 dp.
workspace: public
workflow:
dag:
- name: soda-job-v1
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO # WARNING, ERROR, DEBUG
stackSpec:
inputs:
- dataset: dataos://lakehouse:sales_360/account
options:
engine: minerva
clusterName: system
profile:
columns:
- site_number
- customer_no
- city
checks:
- schema:
name: Confirm that required columns are present
warn:
when required column missing: [customer_name,premise_code]
fail:
when required column missing:
- city
when wrong column type:
site_number: integer
- invalid_count(customer_name) = 0 :
valid min length: 5
name: First name has 5 or more characters
warn: when between 5 and 27
fail: when > 27
- invalid_percent(customer_name) < 1%:
valid max length: 27
filter: site_number > 0
- invalid_count(site_number) < 0:
valid min: 5
valid max: 98
- missing_percent("phone_number") = 0
- duplicate_percent(customer_no) < 1%
- row_count between 1 and 170
- avg_length(address) > 16
- min(customer_no) > 0:
filter: site_number = 3
# ...other inputs attributes
Defining columns to be profiled (optional)¶
The profile section enables you to specify a list of columns that require profiling. Profiling involves analysing and collecting information about the characteristics and data distribution in these columns. The profile section is especially beneficial for gaining insights into the data and comprehending it’s patterns.
Columns specification
The columns attribute under the profile section is where you specify the list of columns you want to profile. Each column is represented as a string item in the list.
You can provide the exact column name, or you can use special patterns to match multiple columns. The column matching patterns are provided in the list below:
| Column Patterns | Description | Example |
|---|---|---|
| Exact Column Matching | If you provide an exact column name, the profiling will focus only on that specific column. | - customer_index |
| Wildcard Matching | If you want to profile multiple columns that share a common pattern, you can use the "*" wildcard character. This wildcard matches any sequence of characters within a column name. |
- include d* |
| Wildcard for all Columns | To profile all columns in the dataset, you can use the "*" wildcard without any prefix. |
- "*" |
| Excluding Columns | To exclude specific columns from the profiling process, you can use the "exclude" keyword followed by the column names. |
- "*" - exclude email_id |
| Combining Patterns | You can combine different patterns to create more refined selections. | - customer_index - exclude email_id - include d* - e* |
Define optional configuration¶
The options section provides users with the flexibility to configure various attributes for connecting to data sources or data source options. These options encompass:
Engine
The engine attribute can assume two values: minerva and default.
- The
defaultvalue executes queries on the data source. - The
minervaoption utilizes the DataOS query engine (Minerva) to execute queries on the depot connected to the cluster. When opting forminerva, specifying theclusterNamebecomes mandatory.
Info
For sources like Lakehouse, engine must be minerva. For more information, refer to the list of sources and supported engines provided below.
List of Sources and Supported Engine
| Source Name / Engine | Default | Minerva |
|---|---|---|
| Snowflake | Yes | Yes |
| Oracle | Yes | Yes |
| Trino | Yes | Yes |
| Minerva | No | Yes |
| BigQuery | Yes | Yes |
| Postgres | Yes | Yes |
| MySQL | Yes | Yes |
| MSSQL | Yes | Yes |
| Redshift | Yes | Yes |
| Elastic Search | No | Yes |
| MongoDB | No | Yes |
| Kafka | No | Yes |
| Azure File System | No | No |
| Eventhub | No | No |
| GCS | No | No |
| OpenSearch | No | No |
| S3 | No | No |
Cluster name
If applicable, users can provide the clusterName on which queries will run. This is a mandatory field in the case of the Minerva engine. You can check the cluster on which your depot is mounted in Workbench or check the cluster definition in the Operations App.
Info
You can use all source-supported properties that the Soda Core library supports as well.
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
options:
engine: minerva
clusterName: miniature
The following table provides a comprehensive overview of the various attributes within the Soda-specific Section:
| Attribute | Data Type | Default Value | Possible Values | Requirement |
|---|---|---|---|---|
stackSpec |
mapping | none | none | mandatory |
inputs |
list of mappings | none | any valid iceberg dataset UDL address |
mandatory |
dataset |
string | none | none | mandatory |
options |
mapping | none | set_version | optional |
engine |
string | none | default / minerva | optional |
clusterName |
string | none | valid cluster name | optional |
branchName |
string | main | valid branch name in string format | optional |
filter |
mapping | none | none | optional |
name |
string | none | valid filter name | optional |
where |
string | none | valid filter condition | optional |
profile |
mapping | none | none | optional |
columns |
list of strings | none | dataset column names | optional |
checks |
list of mappings | none | valid SodaCL checks | mandatory |
For further details regarding the Soda Stack-specific attributes, you can refer to the link: Attributes of Soda Stack YAML.
Branch name for Lakehouse
In DataOS, Soda facilitates the execution of checks on different branches within a Lakehouse storage or Lakehouse-type Depot. By default, if no branch name is specified, Soda automatically targets the main branch. However, users have the option to direct the checks towards a specific branch by providing the branch name.
Info
To specify a branch name when running a check in a Depot that supports the Iceberg table format, follow the sample configuration below. This capability ensures checks are performed on the desired branch, enhancing the flexibility and accuracy of data management.
stackSpec:
inputs:
- dataset: dataos://lakehouse:retail/customer
options:
engine: minerva
clusterName: miniature
branchName: test
This configuration illustrates how to set the branchName to "test". Adjust the branchName parameter to match the branch you intend to assess.
Soda Samples Manifest¶
Sample manifest for Soda Stack using Workflow
name: soda-workflow-v01
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Random User Console
workspace: public
workflow:
dag:
- name: soda-job-v1
title: soda Sample Test Job
description: This is sample job for soda dataos sdk
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO # WARNING, ERROR, DEBUG
stackSpec:
inputs:
# Redshift
- dataset: dataos://sanityredshift:public/redshift_write_12
checks:
- row_count between 10 and 1000:
attributes:
category: Accuracy
# Oracle
- dataset: dataos://sanityoracle:dev/oracle_write_12
checks:
- row_count between 10 and 1000:
attributes:
category: Accuracy
# MySql
- dataset: dataos://sanitymysql:tmdc/mysql_write_csv_12
checks:
- row_count between 10 and 1000:
attributes:
category: Accuracy
# MSSQL
- dataset: dataos://sanitymssql:tmdc/mssql_write_csv_12
checks:
- row_count between 10 and 1000:
attributes:
category: Accuracy
# Minerva
- dataset: dataos://lakehouse:retail/customer
options:
engine: minerva
clusterName: miniature
profile:
columns:
- customer_index
- exclude email_id
- include d*
- e*
checks:
- row_count between 10 and 1000:
attributes:
category: Accuracy
- row_count between (10 and 55):
attributes:
category: Accuracy
- missing_count(birthdate) = 0:
attributes:
category: Completeness
- invalid_percent(phone_number) < 1 %:
valid format: phone number
- invalid_count(number_of_children) < 0:
valid min: 0
valid max: 6
attributes:
category: Validity
- min(age) > 30:
filter: marital_status = 'Married'
attributes:
category: Accuracy
- duplicate_count(phone_number) = 0:
attributes:
category: Uniqueness
- row_count same as city:
name: Cross check customer datasets
attributes:
category: Accuracy
- duplicate_count(customer_index) > 10:
attributes:
category: Uniqueness
- duplicate_percent(customer_index) < 0.10:
attributes:
category: Uniqueness
- failed rows:
samples limit: 70
fail condition: age < 18 and age >= 50
- failed rows:
fail query: |
SELECT DISTINCT customer_index
FROM customer as customer
- freshness(ts_customer) < 1d:
name: Freshness01
attributes:
category: Freshness
- freshness(ts_customer) < 5d:
name: Freshness02
attributes:
category: Freshness
- max(age) <= 100:
attributes:
category: Accuracy
- max_length(first_name) = 8:
attributes:
category: Accuracy
- values in (occupation) must exist in city (city_name):
samples limit: 20
attributes:
category: Accuracy
- schema:
name: Confirm that required columns are present
warn:
when required column missing: [first_name, last_name]
fail:
when required column missing:
- age
- no_phone
attributes:
category: Schema
- schema:
warn:
when forbidden column present: [Voldemort]
when wrong column type:
first_name: int
fail:
when forbidden column present: [Pii*]
when wrong column type:
number_of_children: DOUBLE
attributes:
category: Schema
# Postgres
- dataset: dataos://metisdb:public/classification
checks:
- row_count between 0 and 1000:
attributes:
category: Accuracy
# Big Query
- dataset: dataos://distribution:distribution/dc_info
checks:
- row_count between 0 and 1000:
# Snowflake
- dataset: dataos://sodasnowflake:TPCH_SF10/CUSTOMER
options: # this option is default no need to set, added for example.
engine: default
checks:
- row_count between 10 and 1000:
attributes:
category: Accuracy
Sample manifest for Soda Stack orchestrated using a Worker
name: soda-worker-sample-v01
version: v1beta
type: worker
tags:
- worker
- soda-checks
description: Soda Sample Worker
workspace: public
worker:
replicas: 1
tags:
- worker
- soda-checks
stack: sodaworker+python:1.0
logLevel: INFO
compute: runnable-default
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 1000m
memory: 1024Mi
stackSpec:
inputs:
# Minerva
- dataset: dataos://lakehouse:retail/customer
options:
engine: minerva
clusterName: miniature
profile:
columns:
- customer_index
- exclude email_id
- include d*
- e*
checks:
- row_count between 10 and 1000:
attributes:
category: Accuracy
- row_count between (10 and 55):
attributes:
category: Accuracy
- missing_count(birthdate) = 0:
attributes:
category: Completeness
# - invalid_percent(phone_number) < 1 %:
# valid format: phone number
- invalid_count(number_of_children) < 0:
valid min: 0
valid max: 6
attributes:
category: Validity
- min(age) > 30:
filter: marital_status = 'Married'
attributes:
category: Accuracy
- duplicate_count(phone_number) = 0:
attributes:
category: Uniqueness
- row_count same as city:
name: Cross check customer datasets
attributes:
category: Accuracy
- duplicate_count(customer_index) > 10:
attributes:
category: Uniqueness
- duplicate_percent(customer_index) < 0.10:
attributes:
category: Uniqueness
# - failed rows:
# samples limit: 70
# fail condition: age < 18 and age >= 50
# - failed rows:
# fail query: |
# SELECT DISTINCT customer_index
# FROM customer as customer
- freshness(ts_customer) < 1d:
name: Freshness01
attributes:
category: Freshness
- freshness(ts_customer) < 5d:
name: Freshness02
attributes:
category: Freshness
- max(age) <= 100:
attributes:
category: Accuracy
# - max_length(first_name) = 8:
# attributes:
# category: Accuracy
- values in (occupation) must exist in city (city_name):
samples limit: 20
attributes:
category: Accuracy
- schema:
name: Confirm that required columns are present
warn:
when required column missing: [first_name, last_name]
fail:
when required column missing:
- age
- no_phone
attributes:
category: Schema
- schema:
warn:
when forbidden column present: [Voldemort]
when wrong column type:
first_name: int
attributes:
category: Schema
Apply the manifest using CLI¶
Configure the Check as per the use-cases and apply the orkflow using the following command:
Soda Quality Check references¶
| Quality Category | What It Checks | Key Capabilities | Business Value |
|---|---|---|---|
| Accuracy | Data correctness and statistical measures | • Row count validation • Min/max value verification • Average calculations • Sum and percentile checks |
Ensures data reflects real-world values and meets expected statistical ranges |
| Completeness | Missing or incomplete data | • Null value detection • Missing count/percentage • Custom missing value patterns • Failed rows identification |
Guarantees essential data fields are populated for reliable analysis |
| Freshness | Data recency and timeliness | • Time-based thresholds (hours/days) • Alert configurations • Filtered freshness checks • Timestamp validation |
Ensures data is current and updated according to business requirements |
| Schema Validation | Data structure and format consistency | • Required/forbidden columns • Data type validation • Column order verification • Pattern-based column checks • Schema change detection |
Maintains structural integrity and prevents downstream processing errors |
| Uniqueness | Duplicate detection and prevention | • Single column uniqueness • Multi-column combinations • Tolerance thresholds • Custom sampling limits • Filtered duplicate checks |
Prevents data redundancy and ensures entity integrity |
| Validity | Data format and rule compliance | • Predefined value sets • Regex pattern matching • Length constraints • Numerical ranges • Format validation (email, phone, etc.) |
Confirms data adheres to business rules and expected formats |
Tip
By specifying a category, checks are better organized and easily searchable, ensuring that users can quickly understand the type of validation being applied. Therefore, it is recommended to add the category of the checks, as this allows the category to be populated in the Data Product Hub.
Data Product Hub consolidates the status of all your data quality checks under the Quality tab, giving a comprehensive view of the health of your data assets. There are two ways for a check and its latest result to appear on the dashboard:
-
Manual scans with Scanner: When you define checks in a YAML file and run a scanner using the Soda Library, the checks and their results are displayed in the Checks dashboard.
-
Scheduled scans by Soda Workflow: When Soda runs a scheduled workflow, the checks and their latest results automatically appear on the Checks dashboard.
Each check result on the dashboard indicates whether it has passed or failed based on the specific quality dimension it is assessing. For Instance, in the below provided image, we can see the status of various data quality checks:
- Accuracy: Passed, as indicated by the green checkmark.
- Completeness: Passed, with a green checkmark.
- Freshness: Flagged with a warning (⚠️), suggesting the data might not be up-to-date.
- Schema: Also flagged (⚠️), which could mean there are schema mismatches or other issues with the data structure.
- Uniqueness: Passed successfully.
- Validity: Passed, indicating the data adheres to the expected validation rules.

When you click on any of the check, a detailed trend chart appears, displaying the specific times the check was executed along with the percentage of SLO compliance over time. The chart includes a graphical representation of how the data met the predefined quality standards, with 100% indicating full compliance. Any dips in the line graph highlight potential issues during specific check runs. Additionally, the dashboard may show more information like dataset details and error messages, offering a comprehensive view of the data quality trends over time. For instance, here you can see that the Trend Chart of the Validity check which indicates the time checks were ran against the percentage of SLOs.
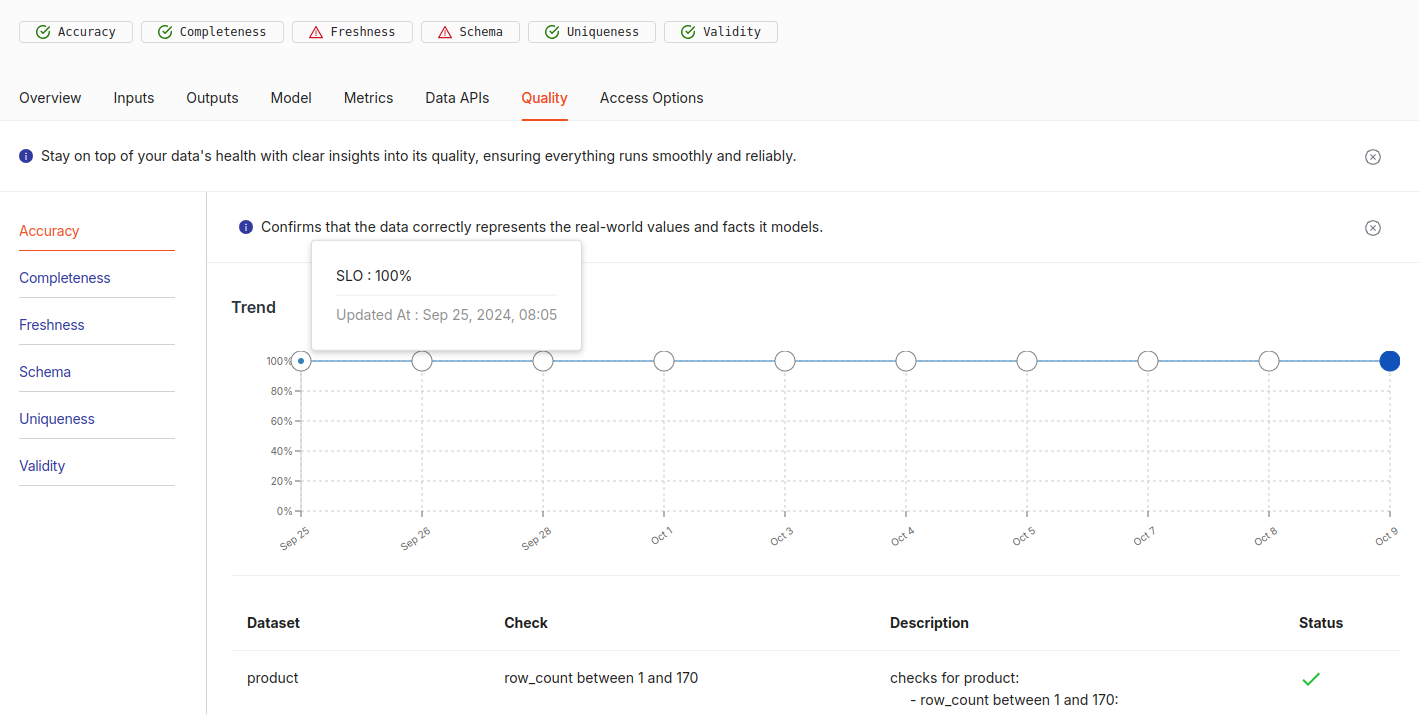
The detailed trend chart shows that the data quality check was consistently run at 8:05 AM on several specific dates, including September 25, 26, 28, and daily from October 1 to 9. This regular cadence indicates the check was scheduled to run at the same time on these dates, ensuring continuous monitoring. The trend line remains at 100%, meaning the data met all SLO criteria during each check. For more details on the Quality tab refer this link and scroll to Quality tab.
Querying profiling and checks data¶
Soda check results and profiling information are stored in Iceberg tables, and querying this information can be accomplished through Workbench App.
To do so, Workflows can be executed to sink the information related to Checks and Profiles into the Lakehouse depot. The YAML for both Workflows is provided below.
Workflow for sinking Soda Check information
name: soda-check-metrics-data
version: v1
type: workflow
workflow:
dag:
- name: soda-cm-data
spec:
stack: flare:7.0
compute: runnable-default
stackSpec:
job:
explain: true
inputs:
- name: soda
dataset: dataos://systemstreams:soda/quality_profile_results_01
isStream: false
options:
startingOffsets: earliest
logLevel: INFO
outputs:
- name: joined_checks_metrics
dataset: dataos://lakehouse:soda/soda_check_metrics_01?acl=rw
format: Iceberg
options:
saveMode: append
checkpointLocation: dataos://lakehouse:sys01/checkpoints/soda-checks-data/v001?acl=rw
sort:
mode: partition
columns:
- name: depot
order: desc
- name: collection
order: desc
- name: dataset
order: desc
iceberg:
partitionSpec:
- type: identity
column: depot
- type: identity
column: collection
- type: identity
column: dataset
steps:
- sequence:
- name: dropped_columns
sql: SELECT * from soda
functions:
- name: drop
columns:
- __eventTime
- __key
- __producer_name
- __messageProperties
- __publishTime
- __topic
- automatedMonitoringChecks
- clusterName
- dataosResourceId
- defaultDataSource
- definitionName
- engine
- hasFailures
- hasErrors
- hasWarnings
- logs
- metadata
- profiling
- queries
- runId
- name: cleanse_column_names
- name: checks_extracted
sql: select * from dropped_columns
functions:
- name: unfurl
expression: explode(checks) as checks_
- name: drop
columns:
- checks
- name: rename_all
columns:
metrics: metrics_value
- name: unfurl
expression: checks_.*
- name: drop
columns:
- checks_
- name: unfurl
expression: explode(metrics) as metrics_
- name: drop
columns:
- metrics
- name: metrics_extracted
sql: select dataos_run_id, metrics_value from checks_extracted
functions:
- name: unfurl
expression: explode(metrics_value) as metrics_value_
- name: drop
columns:
- metrics_value
- name: unfurl
expression: metrics_value_.*
- name: drop
columns:
- metrics_value_
- name: joined_checks_metrics
sql: select
ce.dataos_run_id, ce.job_name, ce.scan_start_timestamp as timestamp, ce.user_name, ce.depot, ce.collection, ce.dataset, ce.column, ce.name as check_definition, me.metric_name, me.value as metric_value, ce.outcome as check_outcome
from checks_extracted ce
left join metrics_extracted me on ce.dataos_run_id = me.dataos_run_id and ce.metrics_ = me.identity
Workflow for sinking Soda Profiling information
version: v1
name: soda-profile-data
type: workflow
workflow:
dag:
- name: soda-prf-data
spec:
stack: flare:7.0
compute: runnable-default
stackSpec:
job:
explain: true
inputs:
- name: soda
dataset: dataos://systemstreams:soda/quality_profile_results_01
isStream: false
options:
startingOffsets: earliest
logLevel: INFO
outputs:
- name: changed_datatype
dataset: dataos://lakehouse:soda/soda_profiles_01?acl=rw
format: Iceberg
options:
saveMode: append
checkpointLocation: dataos://lakehouse:sys01/checkpoints/soda-profiles-data/v001?acl=rw
sort:
mode: partition
columns:
- name: depot
order: desc
- name: collection
order: desc
- name: dataset
order: desc
iceberg:
partitionSpec:
- type: identity
column: depot
- type: identity
column: collection
- type: identity
column: dataset
steps:
- sequence:
- name: dropped_columns
sql: SELECT * from soda
functions:
- name: drop
columns:
- __eventTime
- __key
- __producer_name
- __messageProperties
- __publishTime
- __topic
- automatedMonitoringChecks
- clusterName
- dataosResourceId
- defaultDataSource
- definitionName
- engine
- hasFailures
- hasErrors
- hasWarnings
- logs
- metadata
- checks
- queries
- metrics
- name: cleanse_column_names
- name: unfurl
expression: explode(profiling) as profiling_
- name: unfurl
expression: profiling_.*
- name: drop
columns:
- profiling
- profiling_
- name: unfurl
expression: explode(column_profiles) as column_profiles_
- name: unfurl
expression: column_profiles_.*
- name: unfurl
expression: profile.*
- name: drop
columns:
- column_profiles
- column_profiles_
- profile
- name: cleanse_column_names
- name: changed_datatype
sql: |
SELECT
collection,
dataset,
depot,
job_name,
user_name,
scan_end_timestamp as created_at,
row_count,
table,
column_name,
run_id,
cast(avg AS STRING) AS avg,
cast(avg_length AS STRING) AS avg_length,
cast(distinct AS STRING) AS distinct,
cast(frequent_values AS STRING) AS frequent_values,
cast(histogram AS STRING) AS histogram,
cast(max AS STRING) AS max,
cast(max_length AS STRING) AS max_length,
cast(maxs AS STRING) maxs,
cast(min AS STRING) AS min,
cast(min_length AS STRING) AS min_length,
cast(mins AS STRING) AS mins,
cast(missing_count AS STRING) AS missing_count,
cast(stddev AS STRING) AS stddev,
cast(sum AS STRING) AS sum,
cast(variance AS STRING) AS variance
FROM
dropped_columns
functions:
- name: unpivot
columns:
- avg
- avg_length
- distinct
- frequent_values
- histogram
- max
- max_length
- maxs
- min
- min_length
- mins
- missing_count
- stddev
- sum
- variance
pivotColumns:
- run_id
- created_at
- depot
- collection
- dataset
- user_name
- job_name
- row_count
- table
- column_name
keyColumnName: analyzer_name
valueColumnName: result
Once executed, the information can be queried from the Lakehouse tables using the Workbench App.
- For checks information, query the
dataos://lakehouse:soda/soda_check_metrics_01table. - For profiling information, query the
dataos://lakehouse:soda/soda_profiles_01table.
Sample query