Cluster¶
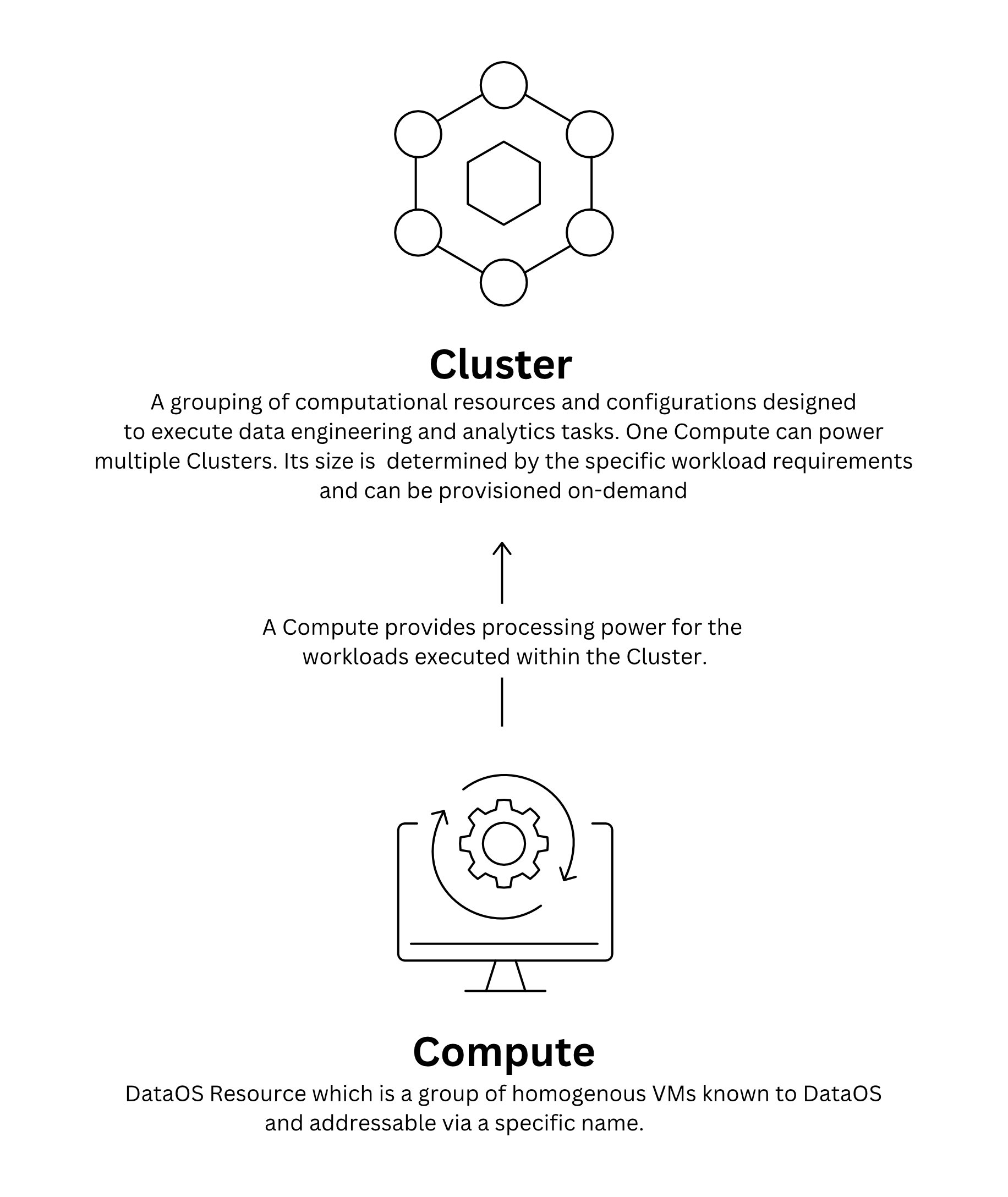
A Cluster in DataOS is a Resource that encompasses a set of computational resources and configurations necessary for executing data engineering and analytics tasks. It relies on the Compute Resource, which provides the required processing power for the workloads executed within the Cluster.
A Cluster Resource can be provisioned on-demand, allowing for efficient allocation of resources based on workload-specific requirements. This decoupling of computation and storage, facilitates flexibility, cost-efficiency, and scalability.
-
How to create a Cluster Resource in DataOS?
Learn how to create a Cluster Resource in DataOS.
-
How to configure the manifest file of Cluster?
Discover how to configure the manifest file of a Cluster by adjusting its attributes.
-
How to interact with a Cluster?
Understand how to interact with a Cluster in DataOS.
-
How to tune a Cluster's performance?
Explore how to tune a Cluster's performance in various scenarios.
Query Engines on Clusters¶
Within a Cluster, a group of provisioned machines collaborates to process queries submitted to a query engine. DataOS supports two types of query engines:
These Clusters can be created and connected to the desired Compute Resource. If a single Cluster is inadequate, multiple Clusters can be effortlessly created to accommodate the specific requirements of different workloads. Distributing workloads across clusters ensures optimal performance and resource utilization.
Minerva¶
Minerva is an interactive static query engine, meticulously crafted to efficiently execute analytical and exploratory workloads. It empowers data developers to effortlessly query diverse data sources using a unified, high-performance SQL interface. With Minerva, data analysis of substantial data volumes becomes simpler, eliminating the need to handle intricate underlying configurations and data formats.
To maximize performance, organizations can establish Minerva query engine clusters capable of effortlessly handling heavy workloads. These clusters enable the concurrent execution of memory-intensive, I/O-intensive, long-running, and CPU-intensive queries, ensuring efficient processing of diverse data scenarios.
Querying Diverse Data Sources
Minerva supports an extensive range of data sources, encompassing both traditional relational databases such as Oracle, PostgreSQL, MySQL, and Redshift, as well as Lakehouses built on object storages like Amazon S3, and Google Cloud Storage. This broad compatibility ensures seamless access to various data sources, enabling comprehensive and integrated analyses. To know more about the various data sources supported by Minerva, click on the following link: Connectors Configuration.
Tip
When configuring a Cluster for Snowflake Depot, the following environment variables must be set to ensure compatibility with the Snowflake JDBC driver:
coordinatorEnvs:
"JVM__opts": "--add-opens=java.base/java.nio=ALL-UNNAMED -Dnet.snowflake.jdbc.enableBouncyCastle=TRUE"
workerEnvs:
"JVM__opts": "--add-opens=java.base/java.nio=ALL-UNNAMED -Dnet.snowflake.jdbc.enableBouncyCastle=TRUE"
Sample Snowflake Minerva Cluster Configuration
# Resource metadata
name: snowflakecluster
version: v1
type: cluster
description: Snowflake Depot Cluster using Minerva.
tags:
- cluster
- minerva
# Cluster specification
cluster:
compute: query-default
type: minerva
# Minerva-specific configuration
minerva:
replicas: 1
# resources:
# limits:
# cpu: 2000m
# memory: 4Gi
# requests:
# cpu: 2000m
# memory: 4Gi
# debug:
# logLevel: INFO
# trinoLogLevel: ERROR
depots:
- address: dataos://snowflakedepot
coordinatorEnvs:
"JVM__opts": "--add-opens=java.base/java.nio=ALL-UNNAMED -Dnet.snowflake.jdbc.enableBouncyCastle=TRUE"
workerEnvs:
"JVM__opts": "--add-opens=java.base/java.nio=ALL-UNNAMED -Dnet.snowflake.jdbc.enableBouncyCastle=TRUE"
Query Execution Process
When initiating a SQL query from sources such as Workbench, Minerva-CLI, JDBC, or Lens App UI, the query is seamlessly directed to the Minerva Gateway Service. The Gateway Service conducts a thorough analysis of the query and the associated tables, forwarding it to the Minerva Clusters for execution. Furthermore, the Gateway Service facilitates data policy decisions, including Masking and Filtering policies. Once the analysis is completed, the query is seamlessly passed on to the Minerva Cluster for execution.
Themis¶
Themis is an elastic SQL query engine optimized for fast, distributed querying across DataOS Lakehouse. As a modern JDBC server, Themis offers a comprehensive interface specifically designed for DataOS Lakehouse, distinguishing itself through high performance, versatility, scalability, availability, and security measures, making it ideal for large-scale enterprise applications working with Lakehouse.
Key Characteristics of Themis
Themis excels in its domain with several notable features:
- Elasticity: In contrast to Minerva, which is a static query engine, Themis operates as an elastic query engine, adapting dynamically to varying workload demands.
- Data Source Compatibility: Themis is specifically optimized for and only compatible with DataOS Lakehouse. This focused compatibility ensures optimal performance when working with the Lakehouse data architecture.
- Concurrent Processing and Scalability: Designed with a multi-threaded architecture, Themis excels in demanding enterprise environments that require high concurrency and scalability. It is compatible with major big data frameworks, including Apache Hadoop, Spark, and Kubernetes.
- Enhanced Security: Themis incorporates Apache Hive's security features and supports advanced security protocols such as Kerberos, LDAP, and Active Directory, enabling straightforward integration with existing security infrastructures.
- Optimized Performance: Advanced caching and memory management techniques in Themis significantly enhance SQL query performance and efficiency.
- High Availability: With inherent load balancing and failover mechanisms, Themis ensures consistent availability and reliability.
- Efficient Memory Usage: Its design prioritizes efficiency, resulting in a smaller memory footprint.
Comparative Analysis: Minerva vs. Themis¶
Themis and Minerva, both SQL query engines, are designed for efficient, distributed querying in large datasets. The key differences are summarized in the table below:
| Feature | Minerva | Themis | Remarks |
|---|---|---|---|
| Query Engine Type | Static | Elastic | Minerva operates with a fixed allocation of resources, while Themis dynamically allocates resources based on workload demands. |
| SQL Dialect | TrinoSQL | SparkSQL | Different SQL dialects indicate compatibility with various data processing paradigms. |
| Scalability | Limited | High | Themis offers superior scalability compared to Minerva, accommodating fluctuating workloads efficiently. |
| Resource Utilization | Constant | Adaptive | Themis adjusts resource usage in real-time, unlike Minerva's consistent resource requirement. |
| Performance in Variable Workloads | Consistent | Optimal | Themis excels in environments with variable data queries, providing enhanced performance. |
| Data Source Compatibility | Extensive | Lakehouse Only | Minerva supports a wide range of data sources, while Themis is specifically optimized for and only compatible with DataOS Lakehouse. |
| Security Features | Standard | Advanced | Themis integrates more sophisticated security protocols, beneficial for environments with stringent security requirements. |
| Concurrency Handling | Moderate | High | Themis is designed to handle higher levels of concurrency, suitable for large-scale enterprise applications. |
| Flexibility in Deployment | Fixed | Flexible | Themis offers more flexibility in deployment, adapting to various big data platforms like Hadoop, Spark, and Kubernetes. |
| Use Case Suitability | Best for environments with predictable, consistent workloads. For example, predictable data processing needs, such as monthly financial reporting or static data analysis. | Ideal for dynamic, varying workloads and large-scale deployments. For example, dynamic environments such as e-commerce platforms, where real-time data analysis is crucial for customer behavior tracking, inventory management, and personalized recommendations. | Depending on the workload consistency and scale, the choice between Minerva and Themis can be determined. |
How to create a Cluster Resource?¶
Prerequisites¶
Get access permission¶
Before setting up a Cluster instance, ensure that you have the roles:id:operator tag assigned or the appropriate use case permissions granted by the DataOS Operator.
Query-type Compute¶
Ensure that a query-type Compute has been set up by the DataOS Operator before initiating the Cluster setup process. To learn more about Compute, click here.
Setting up a Cluster¶
To create a Cluster Resource within DataOS, you have two options:
-
Using the DataOS Command Line Interface (CLI): You can create a Cluster Resource by applying the Cluster manifest through the CLI.
-
Using the Operations App's Graphical User Interface (GUI): Alternatively, you can create a Cluster Resource by utilizing the GUI in the Operations App.
Create a Cluster manifest¶
In DataOS, users have the capability to instantiate Cluster Resources by creating manifest files (YAML configuration files) and applying them via the DataOS CLI. The code block below provides the sample Cluster manifests for the two different Cluster-types:
Themis Cluster manifest
# Resource meta section (1)
name: themiscluster
version: v1
type: cluster
description: Themis cluster for DataOS Lakehouse
tags:
- cluster
- themis
# Cluster-specific section (2)
cluster:
compute: query-default
type: themis
# Themis-specific section (3)
themis:
themisConf:
"kyuubi.frontend.thrift.binary.bind.host": "0.0.0.0"
"kyuubi.frontend.thrift.binary.bind.port": "10101"
driver:
memory: '4096M'
executor:
memory: '4096M'
depots:
- address: dataos://lakehouse # Note: Themis clusters only support DataOS Lakehouse
Minerva Cluster manifest
# Resource meta section
name: minervacluster
version: v1
type: cluster
description: We are using this cluster to check the monitor and pager stuff with the help of minerva cluster.
tags:
- cluster
- minerva
# Cluster-specific section
cluster:
compute: query-default
type: minerva
# Minerva-specific section
minerva:
replicas: 1
resources:
limits:
cpu: 2000m
memory: 4Gi
requests:
cpu: 2000m
memory: 4Gi
debug:
logLevel: INFO
trinoLogLevel: ERROR
depots:
- address: dataos://lakehouse
The structure of a Cluster Resource manifest encompasses the following sections:
Warning
To display sensitive information in Minerva cluster logs, configure the VERBOSE_CONFIG variable. This setting controls whether secrets are displayed or redacted in logs:
VERBOSE_CONFIG = falseor not set: Secrets are redacted and hashed in logs.VERBOSE_CONFIG = true: Secrets and sensitive information are printed in logs.
Sample Configuration:
Resource meta section¶
The Resource meta section is a standardized component across all DataOS Resource manifests, detailing essential metadata attributes necessary for Resource identification, classification, and management. This metadata is organized within the Poros Database. Below is the syntax for the Resource meta section:
name: ${{minervac}}
version: v1
type: cluster
tags:
- ${{dataos:type:cluster}}
- ${{dataos:type:workspace-resource}}
description: ${{this is a sample cluster configuration}}
owner: ${{iamgroot}}
cluster:
For further details on each attribute, refer to the documentation: Attributes of Resource-specific section.
Cluster-specific section¶
The Cluster-specific Section contains configurations specific to the Cluster Resource-type. The YAML syntax is provided below:
The basic configuration of a manifest snippet includes only the essential attributes required for establishing a Cluster.
cluster:
compute: query-default
type: themis
# Themis-specific section
themis:
# attributes specific to the Themis Cluster-type
| Field | Data Type | Default Value | Possible Value | Requirement |
|---|---|---|---|---|
cluster |
mapping | none | none | mandatory |
compute |
string | none | query-default or any other query type custom Compute Resource | mandatory |
type |
string | none | minerva/themis | mandatory |
The advanced configuration covers the full spectrum of attributes that can be specified within the Cluster-specific section a manifest for comprehensive customization.
cluster:
compute: ${{compute-name}}
type: ${{cluster-type}}
runAsUser: ${{run-as-user}}
maintenance:
restartCron: ${{restart-cron-expression}}
scalingCrons:
- cron: ${{scaling-cron-expression}}
replicas: ${{number-of-replicas}}
resources:
limits:
cpu: ${{cpu-limits}}
memory: ${{memory-limits}}
requests:
cpu: ${{cpu-requests}}
memory: ${{memory-requests}}
minerva/themis:
# attributes specific to the Cluster-type
cluster:
compute: query-default
type: themis
runAsUser: iamgroot
maintenance:
restartCron: '13 1 */2 * *'
scalingCrons:
- cron: '5/10 * * * *'
replicas: 3
resources:
limits:
cpu: 1000m
memory: 2Gi
requests:
cpu: 800m
memory: 1Gi
themis:
# attributes specific to the Themis Cluster-type
| Field | Data Type | Default Value | Possible Value | Requirement |
|---|---|---|---|---|
cluster |
mapping | none | none | mandatory |
compute |
string | none | query-default or any other query type custom Compute Resource | mandatory |
runAsUser |
string | none | userid of the use case assignee | optional |
maintenance |
mapping | none | none | optional |
restartCron |
string | none | any valid cron expression | optional |
scalingCrons |
mapping | none | none | optional |
cron |
string | none | any valid cron expression | optional |
replicas |
integer | 1 | positive integer | optional |
resources |
mapping | none | none | optional |
limits |
mapping | none | none | optional |
cpu |
string | requests: 100m, limits: 400m | number of cpu units in milliCPU(m) or cpu Core | optional |
memory |
string | requests: 100Mi, limits: 400Mi | memory in Mebibytes(Mi) or Gibibytes(Gi) | optional |
requests |
mapping | none | none | optional |
For additional information about attributes within the Cluster-specific section, refer to the link: Attributes of Cluster-specific section.
For the two different types of Cluster, the configuration varies, which are elucidated in the sections below:
The Minerva-specific Section contains configurations specific to the Minerva Cluster. The YAML syntax is provided below:
minerva:
replicas: ${{2}}
match: ''
priority: ${{'10'}}
runAsApiKey: ${{dataos api key}}
runAsUser: ${{iamgroot}}
resources:
limits:
cpu: ${{4000m}}
memory: ${{8Gi}}
requests:
cpu: ${{1200m}}
memory: ${{2Gi}}
debug:
logLevel: ${{INFO}}
trinoLogLevel: ${{ERROR}}
depots:
- address: ${{dataos://lakehouse:default}}
properties:
iceberg.file-format: ${{PARQUET}}
iceberg.compression-codec: ${{GZIP}}
hive.config.resources: ${{"/usr/trino/etc/catalog/core-site.xml"}}
- address: ${{dataos://yakdevbq:default}}
catalogs:
- name: ${{cache}}
type: ${{memory}}
properties:
memory.max-data-per-node: ${{"128MB"}}
Certainly, here's the table with only the attribute names and their corresponding data types, requirements, default values, and possible values:
| Field | Data Type | Default Value | Possible Value | Requirement |
|---|---|---|---|---|
minerva |
mapping | none | none | mandatory |
replicas |
integer | 1 | 1-4 | mandatory |
match |
string | none | any/all | mandatory |
priority |
integer | 10 | 1-5000 | mandatory |
runAsApiKey |
string | users dataos api key | any valid dataos api key | mandatory |
runAsUser |
string | none | userid of the use case assignee | optional |
resources |
mapping | none | none | optional |
limits |
mapping | none | none | optional |
cpu |
string | requests: 100m, limits: 400m | number of cpu units in milliCPU(m) or cpu Core | optional |
memory |
string | requests: 100Mi, limits: 400Mi | memory in Mebibytes(Mi) or Gibibytes(Gi) | optional |
requests |
mapping | none | none | optional |
debug |
mapping | none | none | mandatory |
logLevel |
mapping | INFO | INFO/DEBUG/ERROR | optional |
trinoLogLevel |
mapping | INFO | INFO/DEBUG/ERROR | optional |
depots |
list of mappings | none | none | optional |
address |
string | none | valid depot udl address | optional |
properties |
mapping | none | none | optional |
catalogs |
list of mappings | none | none | optional |
name |
string | none | any valid string | optional |
type |
string | none | oracle/memory/wrangler/redshift | mandatory |
properties |
mapping | none | valid connector properties | optional |
For additional information about attributes above attributes, refer to the Attributes of Minerva-specific section.
Attributes particular to the Themis Cluster are defined here. This includes configurations such as Pod Resources, Spark settings, Depot specifications, and Environment variables.
Example YAML syntax for the Themis-specific section:
themis:
resources: # Pod Resources specification
{}
envs: # Environment variables
{}
themisConf: # Themis configurations
{}
spark:
{} # Spark configuration
depots:
{} # Depots specification
Pod Resources
Specifies the requested and maximum CPU and memory limits for Pod Resources.
themis: # Themis mapping (mandatory)
resources: # Pod Resources (optional)
requests: # Requested CPU and memory resources (optional)
cpu: ${{1000m}} # (optional)
memory: ${{2Gi}} # (optional)
limits: # Maximum limit of CPU and memory resources (optional)
cpu: ${{2000m}} # (optional)
memory: ${{4Gi}} # (optional)
Spark environment configuration
Details the memory size, cores, and other configurations for Spark drivers and executors.
themis: # Themis mapping (mandatory)
spark:
driver: # Spark driver memory and core configuration (mandatory)
memory: ${{4096M}} # (mandatory)
cores: ${{1}} # (mandatory)
executor: # Spark executor memory, core, and instanceCount configuration (mandatory)
memory: ${{4096M}} # (mandatory)
cores: ${{1}} # (mandatory)
instanceCount: ${{1}} # (mandatory)
maxInstanceCount: ${{5}} # (mandatory)
sparkConf: # Spark configurations (optional)
${{spark.dynamicAllocation.enabled: true}}
The list of Spark configuration that can be configured within this section are specified in the toggle below.
For more information, refer to the following link.Spark Configurations
The Spark Configuration can be specified within the sparkConf attribute. The list of spark configurations is provided below:
spark.eventLog.dir = location of folder/directoryspark.ui.port = 4040spark.driver.memory=6gspark.driver.cores=2spark.driver.memoryOverhead=1gspark.executor.memory=4gspark.executor.cores=2
Depot specification
Defines the Depots targeted by the Themis Cluster.
themis: # Themis mapping (mandatory)
depots: # mandatory
- address: ${{dataos://lakehouse}} # Depot UDL address (mandatory)
properties: # Depot properties (optional)
${{properties attributes}}
Themis Configuration
Allows for additional key-value pair configurations specific to the Themis Cluster.
themis: # Themis mapping (mandatory)
themisConf: # Themis configuration specification (optional)
${{"kyuubi.frontend.thrift.binary.bind.host": "0.0.0.0"}} # (optional)
${{"kyuubi.frontend.thrift.binary.bind.port": "10101"}} # (optional)
The list of the available Themis Cluster configurations is provided in the toggle below.
For more information, refer to the following link.Themis Cluster configuration
The Themis configuration can be supplied using the themisConf attribute. The configurations are provided below:
kyuubi.operation.incremental.collect=true : To get paginated data.kyuubi.frontend.thrift.worker.keepalive.time=PT30S : TTL for spark engine, this indicated that after 30 seconds of idle time spark engine is terminated.kyuubi.engine.hive.java.options : The extra Java options for the Hive query enginekyuubi.frontend.thrift.worker.keepalive.time=PT1M : Keep-alive time (in milliseconds) for an idle worker threadkyuubi.frontend.thrift.login.timeout=PT10S : Timeout for Thrift clients during login to the thrift frontend service.kyuubi.metadata.cleaner.interval=PT30M : The interval to check and clean expired metadata.kyuubi.metadata.max.age=PT72H : The maximum age of metadata, the metadata exceeding the age will be cleaned.kyuubi.server.periodicGC.interval : How often to trigger a garbage collectionkyuubi.server.redaction.regex : Regex to decide which Kyuubi contain sensitive information. When this regex matches a property key or value, the value is redacted from the various logs.
Environment Variables
Configures the Themis Cluster for various environments through key-value pair environment variables.
Apply the Cluster manifest¶
To create a Cluster Resource, you need to use the apply command on the CLI. The apply command for Cluster is given below:
dataos-ctl resource apply -f ${{cluster-yaml-file-path}} -w ${{workspace name}}
# Sample
dataos-ctl resource apply -f dataproduct/themis-cluster.yaml -w curriculum
Verify Cluster creation¶
To ensure that your Cluster has been successfully created, you can verify it in two ways:
Check the name of the newly created Cluster in the list of clusters created by you in a particular Workspace:
dataos-ctl resource get -t cluster -w ${{workspace name}}
# Sample
dataos-ctl resource get -t cluster -w curriculum
Alternatively, retrieve the list of all Workers created in the Workspace by appending -a flag:
dataos-ctl resource get -t cluster -w ${{workspace name}} -a
# Sample
dataos-ctl resource get -t cluster -w curriculum -a
You can also access the details of any created Cluster through the DataOS GUI in the Resource tab of the Operations App.
Interacting with Clusters¶
Clusters offers multiple methods for interacting with its features and functionalities. The available options are provided below.
Using CLI client¶
The Trino client is a command-line-based interactive interface that enables users to connect to both the Minerva and Themis Clusters. To learn more, click on the link: How to setup CLI client.
Using Workbench¶
To interact with Clusters using the Workbench, execute the following steps:
-
Accessing the Cluster: Upon launching the Workbench application, the user is required to select the desired Cluster. In this instance, the cluster identified as
themisogis chosen.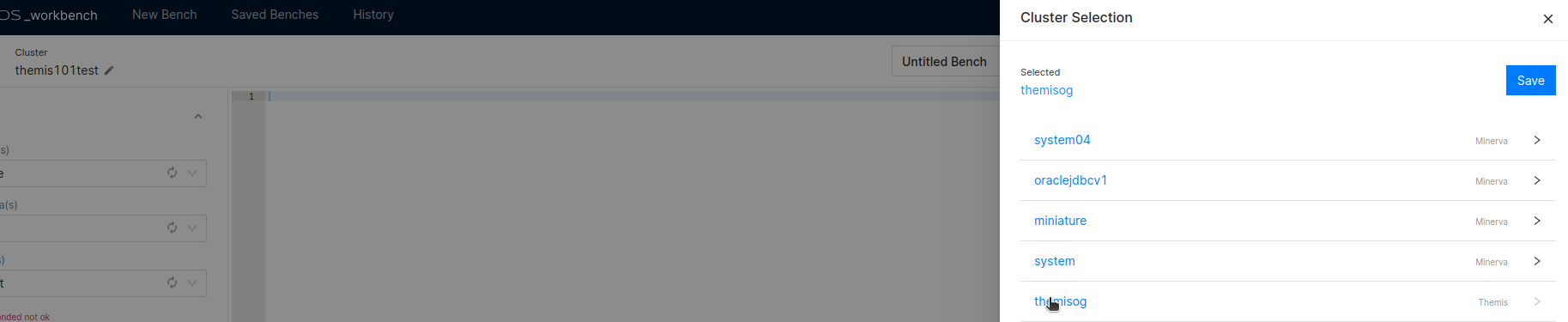
Selecting a Cluster from Workbench -
Execution of Queries:
- Catalog, Schema, and Table Selection: The user must select the appropriate catalog, schema, and tables within the Workbench interface.
- Query Execution: After formulating the query, the user executes it by clicking the 'Run' button.
- Result Retrieval: The outcomes of the executed query are displayed in the pane situated below the query input area.
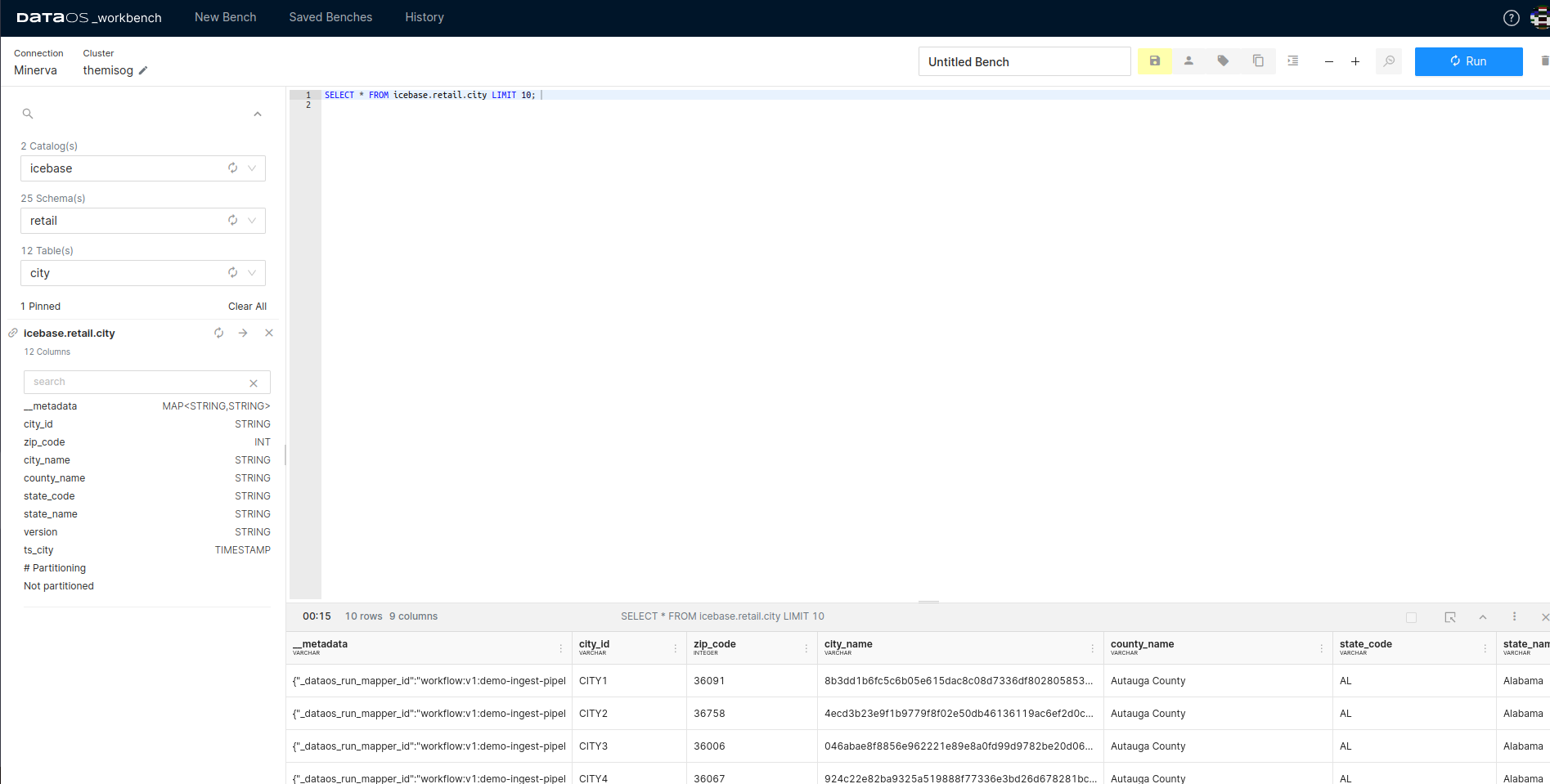
Query result set
For comprehensive details on the features and capabilities of Workbench, refer to the dedicated Workbench documentation.
Using Tableau, SPSS and Power BI¶
Users can leverage popular BI analytics platforms like Tableau, SPSS and Power BI to access data from DataOS via Cluster URL. To learn more, navigate to the link: How to connect Cluster with Tableau, SPSS, and Power BI.
Using Spark Integration (Themis only)¶
For more control over data and transformations, developers can utilize Spark sessions. This can be done in Scala, Python, or Java. Spark integration allows for complex data manipulation and analysis, leveraging Themis's capabilities within a Spark environment.
Query Execution Optimization¶
To achieve enhanced performance and cost efficiency when working with analytical workloads in DataOS, it is crucial to optimize your query execution on Minerva Clusters. The following considerations can assist you in accelerating your queries. For detailed information and guidance, please refer to the provided link: How to optimize query execution.
Performance Tuning¶
The Performance Tuning section is dedicated to enhancing the execution efficiency of queries within Minerva Clusters. It provides data developers with the means to attain optimal performance for analytical and exploratory workloads. By employing proven techniques for performance tuning, developers can streamline query execution, minimize resource consumption, and expedite data analysis. For more information, consult our Performance Tuning page.
The Recommend Cluster Configuration contains recommendations specifically curated to maximize the efficiency and effectiveness of Minerva Cluster for specific scenarios.
Connectors Configuration¶
The Minerva query engine supports a wide range of connectors, including MySQL, PostgreSQL, Oracle, and Redshift. These connectors are configured in a YAML file, where they are mounted as catalogs. The catalogs store schemas and enable referencing of data sources through the respective connectors.
By utilizing these connectors, you can perform data analyses directly on the data sources without the need to transfer the data to DataOS. This approach allows for efficient querying and exploration of data, minimizing data movement. To know more, click on the link: Connectors Configuration.
Cluster Usage Examples¶
Refer to the Cluster Resource Usage Examples documentation for a comprehensive understanding of how Cluster can be utilized. It provides detailed examples and practical implementations to help data developers leverage the Cluster Resource efficiently.