Depot¶
Depot in DataOS is a Resource used to connect different data sources to DataOS by abstracting the complexities associated with the underlying source system (including protocols, credentials, and connection schemas). It enables users to establish connections and retrieve data from various data sources, such as file systems (e.g., AWS S3, Google GCS, Azure Blob Storage), data lake systems, database systems (e.g., Redshift, SnowflakeDB, Bigquery, Postgres), and event systems (e.g., Kafka, Pulsar) without moving the data.
Depot in the Data Product lifecycle
In the Data Product Lifecycle, a Depot in DataOS serves as a foundational Resource for integrating, accessing, and managing data from various sources without physically moving it. It abstracts the complexities of different storage and database systems, ensuring seamless and secure data access for building and operating Data Products.
Key roles of a Depot in the lifecycle include:
-
Data Integration and accessibility: A Depot enables seamless access to diverse data sources such as file systems (AWS S3, Google GCS), databases (PostgreSQL, Snowflake), and event streams (Kafka, Pulsar) through Uniform Data Links (UDLs). This allows Data Products to retrieve and utilize data efficiently without duplication.
-
Standardization and abstraction: By registering data locations within DataOS, a Depot standardizes access mechanisms, eliminating inconsistencies in connection protocols, schemas, and credentials across different systems. This simplifies Data Product development and ensures interoperability.
-
Security and governance: Depots enforce security policies, ensuring only authorized users and services can access specific datasets. Role-based access control (RBAC) and data policies (such as column masking) help maintain compliance with organizational and regulatory requirements.
-
Data transformation and querying: Depots facilitate operations like data ingestion, transformation, and query acceleration using DataOS Stacks (Flare, Bento, etc.). This enhances data readiness for consumption in analytical and operational use cases.
-
Metadata management and observability: A Depot provides deep introspection into registered data sources, enabling visibility into constraints, partitions, and indexing. It also supports monitoring and tracking changes via Metis UI for enhanced observability.
-
Foundation for Data Products: Depots are essential for creating Data Products, as they enable teams to query and transform source data.
By leveraging Depots, organizations can build scalable, secure, and efficient data ecosystems within DataOS, ensuring Data Products have reliable access to well-governed and high-quality data.
Within DataOS, the hierarchical structure of a data source is represented as follows:
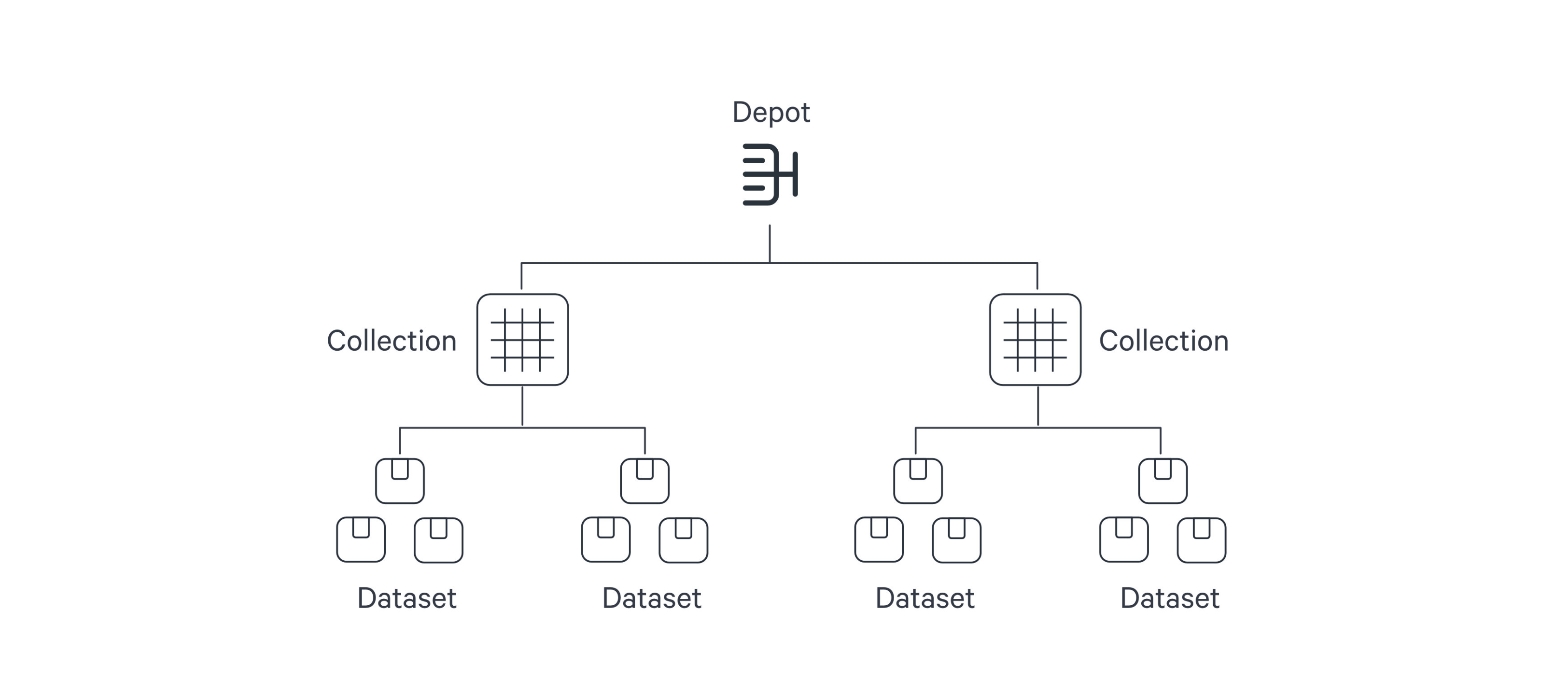
The Depot serves as the registration of data locations to be made accessible to DataOS. Through the Depot Service, each source system is assigned a unique address, referred to as a Uniform Data Link (UDL). The UDL grants convenient access and manipulation of data within the source system, eliminating the need for repetitive credential entry. The UDL follows this format:
dataos://[depot]:[collection]/[dataset]Leveraging the UDL enables access to datasets and seamless execution of various operations, including data transformation using various Clusters and Policy assignments.
Once this mapping is established, Depot Service automatically generates the Uniform Data Link (UDL) that can be used throughout DataOS to access the data. As a reminder, the UDL has the format: dataos://[depot]:[collection]/[dataset].
For a simple file storage system, "Collection" can be analogous to "Folder," and "Dataset" can be equated to "File." The Depot's strength lies in its capacity to establish uniformity, eliminating concerns about varying source system terminologies.
Once a Depot is created, all members of an organization gain secure access to datasets within the associated source system. The Depot not only facilitates data access but also assigns default Access Policies to ensure data security. Moreover, users have the flexibility to define and utilize custom Access Policies for the Depot and Data Policies for specific datasets within the Depot.
Structure of a Depot manifest¶

To know more about the attributes of Depot manifest Configuration, refer to the link: Attributes of Depot manifest.
How to create a Depot?¶
This section involves steps for creating a Depot for different data sources supported by DataOS.
- ABFSS
- Amazon Redshift
- Amazon S3
- Apache Pulsar
- Azure WASBS
- Elasticsearch
- EventHub
- Google Bigquery
- GCS
- JDBC
- Kafka
- MongoDB
- Microsoft SQL Server
- MYSQL
- Opensearch
- Oracle
- PostgreSQL
- Snowflake
How to utilize Depots?¶
Once a Depot is created, you can leverage its Uniform Data Links (UDLs) to access data without physically moving it. The UDLs play a crucial role in various scenarios within DataOS.
Best Practices¶
This section involves do's and don'ts for managing a Depot.
-
As an operator, always assign a use-case to a user instead of directly assigning a tag, as assigning a use-case gives only specific permissions. You can find more information on assigning a use-case here.
-
Give your Depot a meaningful name that represents its purpose.
Example: This makes it easier to manage and identify Depots.
-
✅
s3depotinstead of ❌s3-1, as bys3depotit is easily interpretable that this depot is establishing the connection with Amazon S3 source. -
✅
dbmysqlinstead of ❌db1, bydbmysqlit is clear that the depot is establishing the connection with MySQL database making it clear.
-
-
Avoid creating a Depot with inline credentials, always create an Instance Secret.
-
Do not delete a Depot if other Resources are dependent on it.
Data integration - Supported connectors in DataOS¶
The catalogue of data sources accessible by one or more components within DataOS is provided on the following page: Supported Connectors in DataOS.
FAQs¶
1. How do I know which data sources are supported in DataOS?
You can refer to the Supported Connectors in DataOS document to view all supported data sources.
2. What are Uniform Data Links (UDLs), and how do they work?
UDLs are standardized links that let you access and reference data across the environment without moving it. They provide consistent data access regardless of where the data resides within DataOS.
3. How can I use the data in a Depot without moving it?
DataOS allows compute-on-read and virtual access, so you can query and analyze data in-place without physically moving it.
4. Can I restrict access to specific columns or rows in a Depot?
Yes, you can define row- and column-level access policies to control who sees what data within a Depot.
5. Can you get metadata directly from source data?
Yes, DataOS automatically extracts metadata during ingestion and allows further enrichment.
6. Can users see everyone’s Depots or only their own?
Access to Depots is controlled by permissions. Users can only see Depots they have access to.