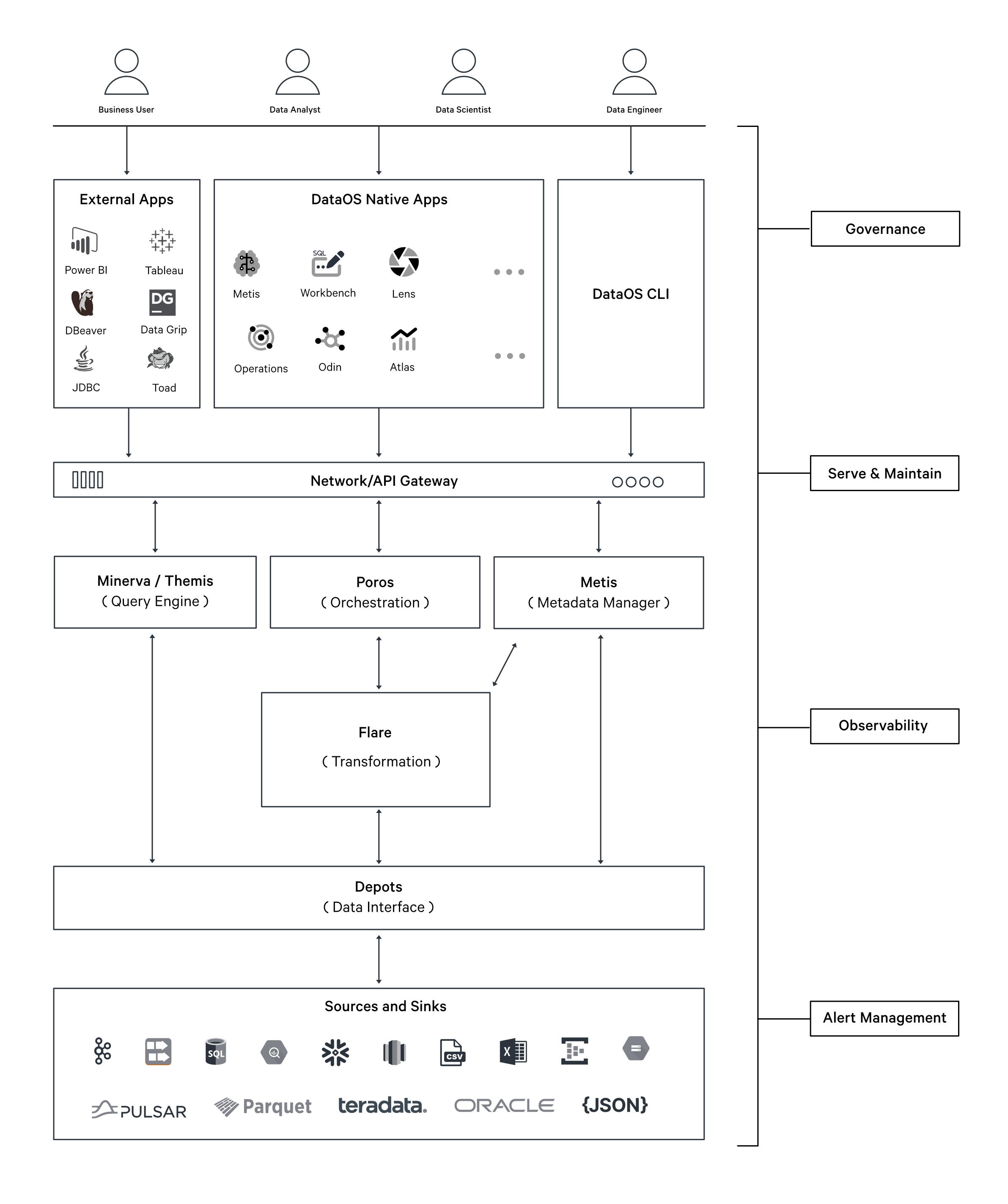
Flare Stack¶
Flare is a declarative Stack for large-scale data processing within DataOS. It leverages a manifest file–based declarative programming paradigm, built as an abstraction over Apache Spark, to provide a comprehensive solution for data ingestion, transformation, enrichment, profiling, quality assessment, and syndication across both batch and streaming data.
Flare Stack in the Data Product Lifecycle
The Flare Stack plays a central role in the Data Product Lifecycle within DataOS. Its declarative, manifest-driven design abstracts Apache Spark to streamline high-volume data processing.
Key Functions in the Lifecycle:
• Ingestion and Transformation: Enables seamless ingestion and transformation of data from diverse sources into the data lake.
• Batch and Streaming Processing: Accommodates both real-time data streams and historical datasets through flexible job configurations.
• Operational Optimization: Executes scheduled maintenance and performance tuning through action jobs.
Integrating the Flare Stack into the data lifecycle allows DataOS to deliver structured, high-quality data products aligned with organizational requirements. This enables efficient transformation of raw data into actionable assets for business decision-making.
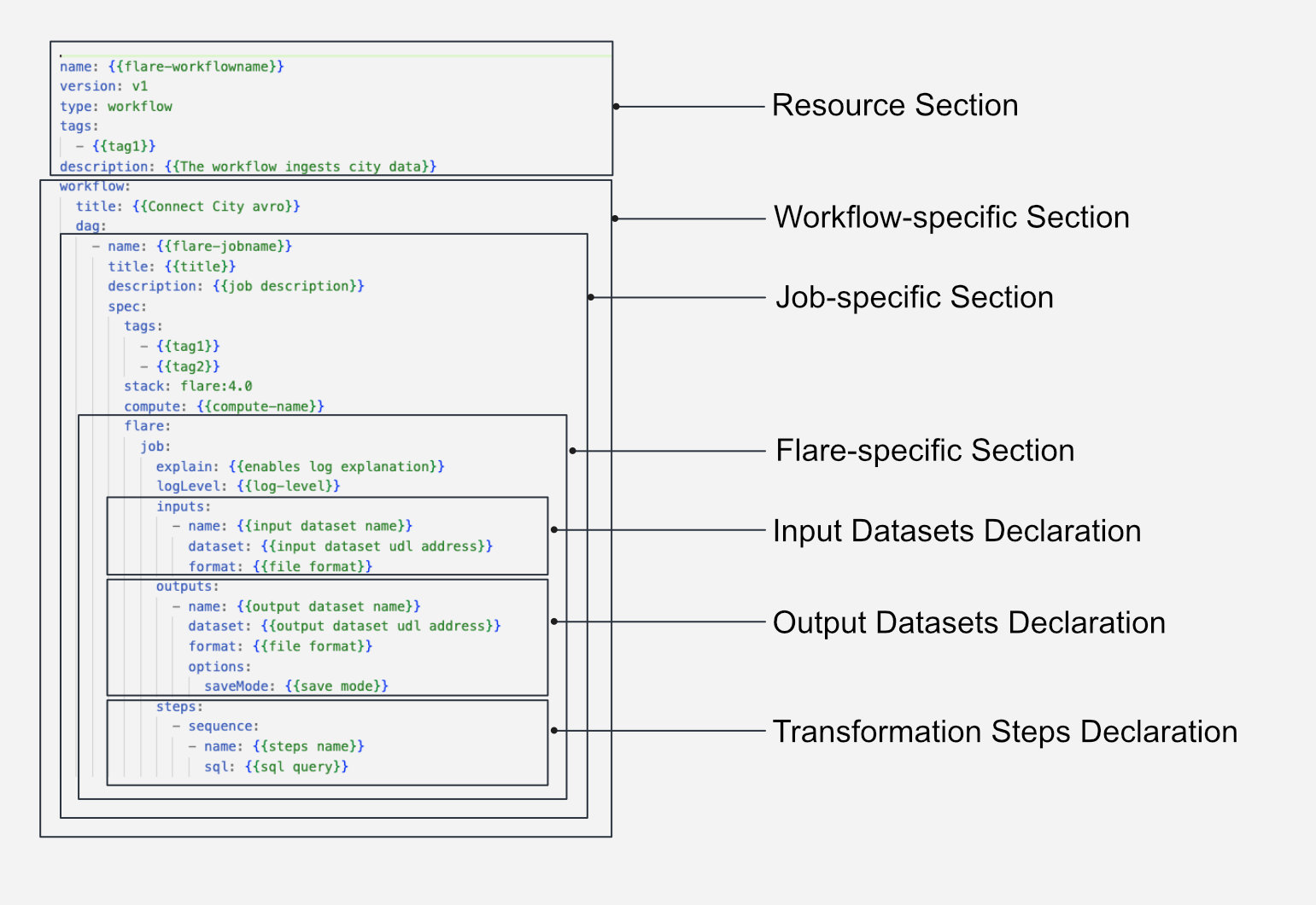
Flare Manifest File Syntax¶
How to create jobs using Flare Stack¶
Flare supports both batch and streaming data processing through distinct job types designed to meet varying operational requirements. Detailed instructions for creating Flare Jobs are available in the Create Flare Jobs documentation.
Types of Flare Jobs¶
Flare Stack offers varied configuration to execute different types of Jobs. The details of each job are provided in the table below:
| Job Type | Description | Best Use Case | Latency | Cost |
|---|---|---|---|---|
| Batch Job | Processes all data every run, ensuring consistent performance. High latency due to full reprocessing. | Small datasets or full reprocessing needed. | High | High (for large data) |
| Data Quality Job | Validates data using user-defined assertions to ensure accuracy and fitness for purpose. | Business validation, compliance checks. | Medium | Medium |
| Incremental Job | Processes only new or changed data since the last run, reducing computation. | Large, frequently changing datasets. | Low | Low (scales efficiently) |
| Stream Job | Continuously processes real-time data with very low latency requirements. | Real-time use cases requiring <1-minute latency. | Very Low | Very High |
| Action Job | Executes maintenance actions on Depots using Iceberg format (e.g., compaction, cleanup). | Data maintenance tasks in Lakehouse or similar Depots. | Depends on action | Depends on action type |
Attributes in Flare Stack manifest configuration¶
The Flare Stack manifest comprises a wide range of configuration parameters designed to support various use cases. These configurations control how data is read, written, and transformed across multiple source and destination systems. Refer to the Flare Stack Manifest Configurations for detailed documentation.
Flare functions¶
Flare provides a comprehensive set of built-in data manipulation functions that can be applied at various stages of job execution. These functions enable the implementation of complex data operations without requiring custom code. For a complete list of supported functions, refer to the Flare functions reference.
Job Optimization in Flare¶
To ensure optimal performance under different workloads, each job executed on the Flare Stack requires specific tuning and optimization. Refer to Flare Optimizations for detailed techniques.
Pre-defined Flare manifest file configuration templates¶
For a complete list of available Depot connectors in Flare, along with the associated configuration details, see Flare Configuration Templates.
Flare Job Use Cases¶
To review implementation examples that demonstrate the practical application of the Flare Stack in real-world data processing workflows, refer to the Case Scenario.