Financial Services Accelerator Data Product¶
Financial Services Accelerator is a Data Product designed to provide a unified and persistent set of identifiers and attributes that describe customers within the financial services domain. This Data Product aims to seamlessly connect customer data, product data, and transaction data across various organizational silos and business units. It is a master dataset continuously updated in real-time, ensuring accuracy and reliability. The steps required to develop this Data Product are given below.
Pre-requisites¶
To create the Data Product within DataOS, following requirements were needed:
-
DataOS initialization.
-
Necessary permissions to create and manage Data Products.
-
Basic understanding of Data Product principles and lifecycle management.
Define Usecase¶
FS Accelerator involves providing a unified and persistent set of customer identifiers and attributes across organizational silos in the financial services domain. This example involves cross selling credit cards, based on the customer's transaction history.
Discover and Explore¶
Upon defining the use case, it has been discovered that no existing Data Product addresses the requirements associated with this use case. Consequently, we will proceed with the development of a new Data Product tailored to meet the FS Accelerator use case.
Design¶
Steps required to design the Data Product are given below:
Define entities and schema¶
After deciding the business use case, we have to define the entities. We require the Product entity to get the details of the product (credit card), the customer entity to get the details of the customer, an Account information entity, and a transaction entity for transaction details. Each entities will have specified schema.
Identify Data Source¶
In the design phase of this Data Product, mock data is generated using a Python script. During this step, careful consideration is given to determining the necessary fields for the dataset and defining the desired structure of our data. Below are the steps to create the mock data for customer entity:
- Add cutsomer fields.
Python script
import pandas as pd
import os
import datetime
from azure.storage.blob import BlobServiceClient, BlobClient, ContentSettings
from dotenv import load_dotenv
import io
from trino.dbapi import connect
from trino.auth import BasicAuthentication
from customer_attribute_helper import *
load_dotenv()
BLOB_ACCOUNT_URL = os.getenv('BLOB_ACCOUNT_URL')
SAS_TOKEN = os.getenv('SAS_TOKEN')
CONTAINER_NAME = os.getenv('CONTAINER_NAME')
BLOB_NAME = os.getenv('BLOB_NAME')
HISTORY_CONTAINER_NAME = os.getenv('HISTORY_CONTAINER_NAME')
USER_NAME = os.getenv('USERNAME')
AUTH_KEY = os.getenv('AUTH_KEY')
HOST = os.getenv('HOST')
# Create a BlobServiceClient with the SAS token
blob_service_client = BlobServiceClient(account_url=BLOB_ACCOUNT_URL, credential=SAS_TOKEN)
# Create a BlobServiceClient with the SAS token
blob_service_client = BlobServiceClient(account_url=BLOB_ACCOUNT_URL, credential=SAS_TOKEN)
# Get a container client and blob client
container_client = blob_service_client.get_container_client(CONTAINER_NAME)
blob_client = container_client.get_blob_client(BLOB_NAME)
# Create a connection to trino
conn = connect(
host=HOST,
port="7432",
auth=BasicAuthentication(USER_NAME, AUTH_KEY),
http_scheme="https",
http_headers={"cluster-name": "fsdomainquerycluster"}
)
customer_query_qr = '''
SELECT * FROM "lakehousetw"."fs_accelerator".customer_overview_raw
'''
customer_df = pd.read_sql(customer_query_qr,conn)
# Drop __metadata and country_code columns
customer_df = customer_df.drop('__metadata', axis=1)
customer_df = customer_df.drop(['country_code'], axis=1)
count = len(customer_df)
# Add country code column
customer_df['country_code'] = customer_df['country'].map(country_codes_dict)
customer_df['cibil_check_date'] = generate_cibil_check_date(count)
customer_df['cibil_score'] = generate_cibil_score_list(count)
# Save to csv.
customer_df.to_csv('./customer_mockdata.csv')
# Upload the CSV file to the blob container
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=BLOB_NAME)
with open('./customer_mockdata.csv', 'rb') as data:
blob_client.upload_blob(data, overwrite=True, content_settings=ContentSettings(content_type='application/csv'))
# Upload the CSV file to the blob the history container
blob_client = blob_service_client.get_blob_client(container=HISTORY_CONTAINER_NAME, blob=BLOB_NAME)
with open('./customer_mockdata.csv', 'rb') as data:
blob_client.upload_blob(data, overwrite=True, content_settings=ContentSettings(content_type='application/csv'))
The above Python script generates mock customer data by connecting to a Trino database, retrieving base customer information, enhancing it with additional fields like country codes, CIBIL check dates, and scores, and then exporting this enriched dataset to a CSV file.
- Generate synthetic data.
Python script
import random
from faker import Faker
from datetime import date, timedelta, datetime
fake = Faker()
# Mapping of country_codes
country_codes_dict = {
'India': '+91',
'Norway': '+47',
'Australia': '+61',
'Brazil': '+55',
'United States': '+1',
'France': '+33',
'Germany': '+49',
'Spain': '+34',
'Indonesia': '+62',
'Canada': '+1',
'Singapore': '+65',
'Netherlands': '+31',
'Italy': '+39'
}
# Mapping of country_cities_states
country_cities_states_mapping = {
'Australian': [
("Sydney", "New South Wales", "2000", "Australia"),
("Melbourne", "Victoria", "3000", "Australia"),
("Brisbane", "Queensland", "4000", "Australia"),
("Perth", "Western Australia", "6000", "Australia"),
("Adelaide", "South Australia", "5000", "Australia"),
],
'Brazilian': [
("Rio de Janeiro", "Rio de Janeiro", "20000", "Brazil"),
("Sao Paulo", "Sao Paulo", "01000", "Brazil"),
('Brasília', 'Federal District', '70000', "Brazil"),
("Salvador", 'Bahia', "40000", 'Brazil'),
("Fortaleza", 'Ceará', '60000', "Brazil")
],
'American': [
("New York City", "New York", '10001', 'United States'),
('Los Angeles', "California", '90001', 'United States'),
("Chicago", "Illinois", '60601', "United States"),
('Houston', "Texas", "77001", 'United States'),
('Miami', 'Florida', "33101", 'United States')
],
'Canadian': [
("Toronto", 'Ontario', 'M5V 1J9', 'Canada'),
("Vancouver", "British Columbia", 'V6B 1E2', "Canada"),
('Montreal', 'Quebec', "H2X 1J1", "Canada"),
("Calgary", 'Alberta', "T2P 0R5", 'Canada'),
("Ottawa", "Ontario", "K1P 1J1", 'Canada')
],
'European': [
('Paris', 'Île-de-France', "75001", "France"),
("Rome", "Lazio", "00100", 'Italy'),
("Madrid", "Madrid", "28001", 'Spain'),
("Berlin", "Berlin", "10115", "Germany"),
("Amsterdam", "North Holland", '1012 JS', "Netherlands")
],
'Indonesian': [
("Jakarta", "Jakarta", '10110', "Indonesia"),
("Surabaya", "East Java", "60111", "Indonesia"),
("Bandung", 'West Java', '40111', "Indonesia"),
('Medan', "North Sumatra", '20111', 'Indonesia'),
("Makassar", 'South Sulawesi', '90111', "Indonesia")
],
'Norwegian': [
('Oslo', 'Oslo', "0010", "Norway"),
("Bergen", 'Vestland', "5015", "Norway"),
("Trondheim", "Trondelag", "7010", "Norway"),
('Stavanger', "Rogaland", '4006', 'Norway'),
('Tromsø', "Troms og Finnmark", '9008', 'Norway')
],
'Singaporean': [
('Singapore', 'Singapore', '049317', "Singapore"),
('Bedok', "Singapore", "469001", 'Singapore'),
("Jurong East", 'Singapore', "609731", 'Singapore'),
("Tampines", "Singapore", "529653", "Singapore"),
('Woodlands', 'Singapore', "738099", "Singapore")
],
'Indian': [
("Mumbai", 'Maharashtra', "400001", "India"),
("Delhi", 'Delhi', '110001', "India"),
("Bangalore", 'Karnataka', '560001', "India"),
('Kolkata', "West Bengal", "700001", "India"),
('Chennai', "Tamil Nadu", '600001', "India"),
("Hyderabad", 'Telangana', '500001', "India"),
("Pune", "Maharashtra", '411001', "India"),
("Chandigarh", "Chandigarh", '160001', "India"),
("Jaipur", 'Rajasthan', '302001', "India"),
("Ahmedabad", 'Gujarat', '380001', "India"),
("Kochi", "Kerala", '682001', "India"),
("Lucknow", "Uttar Pradesh", '226001', "India"),
('Bhopal', "Madhya Pradesh", '462001', "India"),
("Patna", "Bihar", '800001', "India"),
('Coimbatore', "Tamil Nadu", '641001', "India")
]
}
# Get random DOB for Personal type customer along with minor_flag, senior_citizen_flag
def generate_dates_of_birth_with_derived_values(num_customers):
dates_of_birth = ["" for x in range(num_customers)]
minor_flag = ["No" for x in range(num_customers)]
senior_citizen_flag = ["No" for x in range(num_customers)]
itr = 0
for _ in range(int(num_customers * 0.10)):
dob = fake.date_of_birth(minimum_age=10, maximum_age=17)
dates_of_birth[itr] = dob.strftime("%Y-%m-%d")
minor_flag[itr] = "Yes"
itr = itr + 1
for _ in range(int(num_customers * 0.30)):
dob = fake.date_of_birth(minimum_age=18, maximum_age=30)
dates_of_birth[itr] = dob.strftime("%Y-%m-%d")
itr = itr + 1
for _ in range(int(num_customers * 0.35)):
dob = fake.date_of_birth(minimum_age=30, maximum_age=45)
dates_of_birth[itr] = dob.strftime("%Y-%m-%d")
itr = itr + 1
for _ in range(int(num_customers * 0.10)):
dob = fake.date_of_birth(minimum_age=45, maximum_age=59)
dates_of_birth[itr] = dob.strftime("%Y-%m-%d")
itr = itr + 1
for _ in range(int(num_customers * 0.15)):
dob = fake.date_of_birth(minimum_age=60, maximum_age=100)
dates_of_birth[itr] = dob.strftime("%Y-%m-%d")
senior_citizen_flag[itr] = "Yes"
itr = itr + 1
remaining = num_customers - itr
if remaining > 0:
for i in range(remaining):
dob = fake.date_of_birth(minimum_age=10, maximum_age=17)
dates_of_birth[itr] = dob.strftime("%Y-%m-%d")
minor_flag[itr] = "Yes"
senior_citizen_flag[itr] = "No"
itr = itr + 1
return dates_of_birth, minor_flag, senior_citizen_flag
# Create gender distribution for Personal Type customers
def generate_gender():
genders = ['Male', 'Female', 'Non Binary', 'Transgender', 'Intersex', 'I Prefer not to say']
probabilities = [0.60, 0.60, 0.1, 0.1, 0.1, 0.1]
return random.choices(genders, probabilities)[0]
# Mapping for Gender with title
title_mappings = {
'Male': ['Mr', 'Dr'],
'Female': ['Miss', 'Mrs', 'Dr'],
'Non Binary': ['Mx'],
'Transgender': ['Mx'],
'Intersex': ['Mx'],
'I Prefer not to say': ['']
}
# Get a Customer title from Gender
def generate_cust_title(gender, minor_flag):
if minor_flag == "Yes" and gender == "Male":
return 'Mr'
elif minor_flag == "Yes" and gender == "Female":
return 'Miss'
if gender in title_mappings:
return random.choice(title_mappings[gender])
else:
return ''
# Get names (first name, last name) from faker
def generate_names(num_customers, genders):
first_names = ["" for x in range(num_customers)]
middle_names = ["" for x in range(num_customers)]
last_names = ["" for x in range(num_customers)]
itr = 0
fake = Faker('en_IN')
for itr in range(num_customers):
if genders[itr] == "Male":
first_names[itr] = fake.first_name_male().strip(' ')
elif genders[itr] == "Female":
first_names[itr] = fake.first_name_female().strip(' ')
else:
first_names[itr] = fake.first_name().strip(' ')
if random.randint(1, 10) > 5:
middle_names[itr] = fake.first_name_male().strip(' ')
last_names[itr] = fake.last_name().strip(' ')
return first_names, middle_names, last_names
# Generate a Customer segment from given values
def generate_cust_segment():
segments = ['Urban', 'Rural', 'Semi']
probabilities = [0.50, 0.30, 0.20]
return random.choices(segments, probabilities)[0]
# Generate a Customer category from given values
def generate_cust_category():
categories = ['Non Resident', 'Resident Indian']
probabilities = [0.50, 0.60]
return random.choices(categories, probabilities)[0]
# Generate a Customer previlege
def generate_customer_previlege():
categories = ['Yes', 'No']
probabilities = [0.50, 0.50]
return random.choices(categories, probabilities)[0]
# Generate a random email id from first_name, and last_name
def generate_email_ids(first_names, last_names, num_customers, customer_id):
email_ids = []
for itr in range(num_customers):
email = f"{first_names[itr].lower()}.{last_names[itr].lower()}{int(customer_id[itr]) - 1000000000 + 100}@gmail.com"
email_ids.append(email)
return email_ids
# Generate a random 10 digit phone number
def generate_phone_number(customer_id):
print(type(customer_id))
return int(customer_id) + 100098143
# Mapping for title with marital status
marital_status_mapping = {
'Mr': ['Single', 'Married'],
'Mrs': ['Married'],
'Dr': ['Single', 'Married'],
'Mx': ['I prefer not to say'],
'': [''],
'Miss': ['Single', 'Widowed']
}
# Get a Marital status from Title
def generate_marital_status(title, minor_flag):
if minor_flag == "Yes":
return 'Single'
if title in marital_status_mapping:
return random.choice(marital_status_mapping[title])
else:
return ''
# Generate a random Nationality
def generate_nationality():
nationalaties = ['Australian', 'Brazilian', 'Canadian', 'European', 'Indian', 'Indonesian', 'Norwegian', 'Singaporean', 'American']
probabilities = [0.1, 0.2, 0.2, 0.2, 0.5, 0.2, 0.2, 0.2, 0.5]
return random.choices(nationalaties, probabilities)[0]
# Generate a random Customer Occupation for Personal Type
def get_customer_occupation(minor_flag):
if minor_flag == "Yes":
return 'Non Salaried'
occup = ['Salaried' , 'Non Salaried']
probabilities = [0.70 , 0.30]
occupation = random.choices(occup, probabilities)[0]
return occupation
# Generate a random Customer Sourcing
def generate_customer_sourcing():
source = ['Branch', 'Partner', 'Online']
probabilities = [0.40, 0.20, 0.40]
return random.choices(source, probabilities)[0]
# Generate a random Customer Status
def generate_customer_status(minor_flag):
if minor_flag == 'Yes':
return 'Active'
statuses = ['Active', 'Dormant', 'Deceased']
probabilities = [0.80, 0.10, 0.10]
return random.choices(statuses, probabilities)[0]
# Generate a random Customer Risk Category
def generate_customer_risk_category():
statuses = ['High', 'Low', 'Medium']
probabilities = [0.30, 0.30, 0.30]
return random.choices(statuses, probabilities)[0]
# Generate a random Customer Affluence Level
def generate_customer_affluence_level():
statuses = ['High', 'Low', 'Medium']
probabilities = [0.30, 0.40, 0.50]
return random.choices(statuses, probabilities)[0]
# Generate a random list for DOB for Customer Type - Corporate & Merchant
def generate_random_date_list(num_customers, date_percentage):
num_dates = int(num_customers * date_percentage)
num_nulls = num_customers - num_dates
start_date = datetime(2000, 1, 1)
end_date = datetime(2023, 8, 31)
date_list = [start_date + timedelta(days=random.randint(0, (end_date - start_date).days)) for _ in range(num_dates)]
date_strings = [date.strftime("%Y-%m-%d") for date in date_list]
date_list = date_strings + [""] * num_nulls
random.shuffle(date_list)
return date_list
# Generate a tuple for customer city, state, pincode
def get_city_state_pincode(customer_category, nationality):
result = ()
if customer_category == "Resident Indian":
result = random.choice(country_cities_states_mapping['Indian'])
elif customer_category == "Non Resident":
result = random.choice(country_cities_states_mapping[nationality])
return result
# Convert a tuple of city, country, state, pin into a separate lists
def get_list_from_tuple(city_state_country):
city = []
country = []
state = []
pincode = []
for x in city_state_country:
city.append(x[0])
country.append(x[3])
state.append(x[1])
pincode.append(x[2])
return city, country, state, pincode
# Generate a list of Customer Type - Corporate & Merchant
def generate_customer_type(num_customers):
customer_types = []
customer_types = ["Merchant"]*int(num_customers * 0.5) + ["Corporate"]*int(num_customers * 0.5)
remaining = num_customers - len(customer_types)
return customer_types + ["Merchant"]*remaining
#Generate cibil check date
def generate_cibil_check_date(total_accounts):
start_date = datetime(2023, 10, 1)
end_date = datetime(2023, 11, 11)
date_list = [start_date + timedelta(days=random.randint(0, (end_date - start_date).days)) for _ in range(total_accounts)]
cibil_check_dates = [date.strftime("%Y-%m-%d") for date in date_list]
random.shuffle(cibil_check_dates)
return cibil_check_dates
# Generate a Cibil score
def generate_cibil_score_list(count):
cibil_score_list = []
cibil_score_310_to_650_count = int(count * 0.03)
cibil_score_650_to_900_count = count - cibil_score_310_to_650_count
for _ in range(cibil_score_310_to_650_count):
cibil_score_list.append(random.randint(310, 650))
for _ in range(cibil_score_650_to_900_count):
cibil_score_list.append(random.randint(651, 900))
random.shuffle(cibil_score_list)
return cibil_score_list
The above Python script generates synthetic customer data including names, dates of birth, genders, contact details, addresses, and various attributes like marital status, nationality, and credit scores.
- Add customer overview.
Python script
import pandas as pd
from customer_attribute_helper import *
import datetime
import os
from azure.storage.blob import BlobServiceClient, BlobClient, ContentSettings
from dotenv import load_dotenv
from trino.dbapi import connect
from trino.auth import BasicAuthentication
load_dotenv()
BLOB_ACCOUNT_URL = os.getenv('BLOB_ACCOUNT_URL')
SAS_TOKEN = os.getenv('SAS_TOKEN')
CONTAINER_NAME = os.getenv('CONTAINER_NAME')
BLOB_NAME = os.getenv('BLOB_NAME')
HISTORY_CONTAINER_NAME = os.getenv('HISTORY_CONTAINER_NAME')
USER_NAME = os.getenv('USERNAME')
AUTH_KEY = os.getenv('AUTH_KEY')
HOST = os.getenv('HOST')
# Create a BlobServiceClient with the SAS token
blob_service_client = BlobServiceClient(account_url=BLOB_ACCOUNT_URL, credential=SAS_TOKEN)
# Create a BlobServiceClient with the SAS token
blob_service_client = BlobServiceClient(account_url=BLOB_ACCOUNT_URL, credential=SAS_TOKEN)
# Get a container client and blob client
container_client = blob_service_client.get_container_client(CONTAINER_NAME)
blob_client = container_client.get_blob_client(BLOB_NAME)
# Create a connection to trino
conn = connect(
host=HOST,
port="7432",
auth=BasicAuthentication(USER_NAME, AUTH_KEY),
http_scheme="https",
http_headers={"cluster-name": "fsdomainquerycluster"}
)
# Personal Type Customer attributes
personal_type_customer_attributes = [
'Cust Segment', 'Cust Title', 'Customer Category', 'Customer Privelege', 'Customer Type', 'Email address', 'Gender', 'Marital Status', 'Minor Flag', 'Mobile Number1', 'Nationality', 'Occupation', 'Senior Citizen Flag','Customer Risk Category', 'Affluence Level', 'Customer Status', 'Customer AddressLine1', 'Customer AddressLine2', 'Customer AddressLine3', 'City', 'State', 'Country', 'Pin', 'Country Code', 'Cibil Check Date', 'Cibil Score'
]
# Merchant & Corporate Type Customer attributes
merchant_and_corporate_type_customers_attributes = [
'Cust Segment', 'Customer Category', 'Customer Privelege', 'Customer Type', 'Email address', 'Mobile Number1', 'Nationality', 'Customer Risk Category', 'Affluence Level', 'Customer Status', 'Customer AddressLine1', 'Customer AddressLine2', 'Customer AddressLine3', 'City', 'State', 'Country', 'Pin', 'Country Code', 'Cibil Check Date', 'Cibil Score'
]
# Function to take input and update customer attributes
def update_personal_type_customer_attributes(attributes_list, customer_df):
print("Enter the updated values for following attributes (Press ENTER to Skip) : \n")
is_updated = False
for attribute in attributes_list:
updated_value = input(attribute + " : ")
# If value is entered, then will update in customer dataframe
if updated_value != '':
column_name = '_'.join(attribute.lower().split())
customer_df.loc[customer_df.index[0], column_name] = updated_value
is_updated = True
if is_updated == True:
customer_df.loc[customer_df.index[0], 'modified_at'] = datetime.datetime.utcnow()
return customer_df, is_updated
# Input customer ID to be updated
customer_id = input ("Enter Customer ID to be updated : ")
customer_query_qr = '''
SELECT * FROM "lakehousetw"."fs_accelerator".customer_overview_raw WHERE cust_id=\'{customer_id}\'
'''.format(customer_id=customer_id)
customer_df = pd.read_sql(customer_query_qr,conn)
customer_df.drop('__metadata', axis=1, inplace=True)
# If customer Id is valid
if customer_id in customer_df['cust_id'].values:
# Filter out dataframe with given customer ID
customer_type = customer_df.iloc[0]['customer_type']
if customer_type == "Personal":
customer_df, is_updated = update_personal_type_customer_attributes(personal_type_customer_attributes, customer_df)
else:
customer_df, is_updated = update_personal_type_customer_attributes(merchant_and_corporate_type_customers_attributes, customer_df)
# If any value is updated, then save the CSV and upload to blob
if is_updated == True:
customer_df.reset_index(drop=True, inplace=True)
customer_df.to_csv('./mock-data/sample-data/customer_mockdata_updated.csv')
# Upload the CSV file to the blob container
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=BLOB_NAME)
with open('./mock-data/sample-data/customer_mockdata.csv', 'rb') as data:
blob_client.upload_blob(data, overwrite=True, content_settings=ContentSettings(content_type='application/csv'))
# Upload the CSV file to the blob the history container
BLOB_NAME = "customer_mockdata_" + str(customer_id) + "_" + str(datetime.datetime.now().date())
blob_client = blob_service_client.get_blob_client(container=HISTORY_CONTAINER_NAME, blob=BLOB_NAME)
# with open('./mock-data/sample-data/customer_mockdata.csv', 'rb') as data:
# blob_client.upload_blob(data, overwrite=True, content_settings=ContentSettings(content_type='application/csv'))
print("\nUpdated Successfully.")
else:
print("\nNothing to update.")
else:
print("Customer with ID " + customer_id + " does not exist.")
The above Python script establishes connections to Azure Blob Storage and a Trino database using provided credentials. It queries the database to retrieve the maximum customer ID, which informs the generation of mock customer data. This data includes details for personal and merchant/corporate customers, such as names, addresses, and demographic information. Using Pandas, it organizes this data into separate DataFrames for each customer type, merges them into a unified dataset, and exports it to a CSV file named customer_mockdata_20k.csv. Finally, the script uploads this CSV file to Azure Blob Storage.
- Update customer overview.
Python script
import pandas as pd
from customer_attribute_helper import *
import datetime
import os
from azure.storage.blob import BlobServiceClient, BlobClient, ContentSettings
from dotenv import load_dotenv
from trino.dbapi import connect
from trino.auth import BasicAuthentication
load_dotenv()
BLOB_ACCOUNT_URL = os.getenv('BLOB_ACCOUNT_URL')
SAS_TOKEN = os.getenv('SAS_TOKEN')
CONTAINER_NAME = os.getenv('CONTAINER_NAME')
BLOB_NAME = os.getenv('BLOB_NAME')
HISTORY_CONTAINER_NAME = os.getenv('HISTORY_CONTAINER_NAME')
USER_NAME = os.getenv('USERNAME')
AUTH_KEY = os.getenv('AUTH_KEY')
HOST = os.getenv('HOST')
# Create a BlobServiceClient with the SAS token
blob_service_client = BlobServiceClient(account_url=BLOB_ACCOUNT_URL, credential=SAS_TOKEN)
# Create a BlobServiceClient with the SAS token
blob_service_client = BlobServiceClient(account_url=BLOB_ACCOUNT_URL, credential=SAS_TOKEN)
# Get a container client and blob client
container_client = blob_service_client.get_container_client(CONTAINER_NAME)
blob_client = container_client.get_blob_client(BLOB_NAME)
# Create a connection to trino
conn = connect(
host=HOST,
port="7432",
auth=BasicAuthentication(USER_NAME, AUTH_KEY),
http_scheme="https",
http_headers={"cluster-name": "fsdomainquerycluster"}
)
# Personal Type Customer attributes
personal_type_customer_attributes = [
'Cust Segment', 'Cust Title', 'Customer Category', 'Customer Privelege', 'Customer Type', 'Email address', 'Gender', 'Marital Status', 'Minor Flag', 'Mobile Number1', 'Nationality', 'Occupation', 'Senior Citizen Flag','Customer Risk Category', 'Affluence Level', 'Customer Status', 'Customer AddressLine1', 'Customer AddressLine2', 'Customer AddressLine3', 'City', 'State', 'Country', 'Pin', 'Country Code', 'Cibil Check Date', 'Cibil Score'
]
# Merchant & Corporate Type Customer attributes
merchant_and_corporate_type_customers_attributes = [
'Cust Segment', 'Customer Category', 'Customer Privelege', 'Customer Type', 'Email address', 'Mobile Number1', 'Nationality', 'Customer Risk Category', 'Affluence Level', 'Customer Status', 'Customer AddressLine1', 'Customer AddressLine2', 'Customer AddressLine3', 'City', 'State', 'Country', 'Pin', 'Country Code', 'Cibil Check Date', 'Cibil Score'
]
# Function to take input and update customer attributes
def update_personal_type_customer_attributes(attributes_list, customer_df):
print("Enter the updated values for following attributes (Press ENTER to Skip) : \n")
is_updated = False
for attribute in attributes_list:
updated_value = input(attribute + " : ")
# If value is entered, then will update in customer dataframe
if updated_value != '':
column_name = '_'.join(attribute.lower().split())
customer_df.loc[customer_df.index[0], column_name] = updated_value
is_updated = True
if is_updated == True:
customer_df.loc[customer_df.index[0], 'modified_at'] = datetime.datetime.utcnow()
return customer_df, is_updated
# Input customer ID to be updated
customer_id = input ("Enter Customer ID to be updated : ")
customer_query_qr = '''
SELECT * FROM "lakehousetw"."fs_accelerator".customer_overview_raw WHERE cust_id=\'{customer_id}\'
'''.format(customer_id=customer_id)
customer_df = pd.read_sql(customer_query_qr,conn)
customer_df.drop('__metadata', axis=1, inplace=True)
# If customer Id is valid
if customer_id in customer_df['cust_id'].values:
# Filter out dataframe with given customer ID
customer_type = customer_df.iloc[0]['customer_type']
if customer_type == "Personal":
customer_df, is_updated = update_personal_type_customer_attributes(personal_type_customer_attributes, customer_df)
else:
customer_df, is_updated = update_personal_type_customer_attributes(merchant_and_corporate_type_customers_attributes, customer_df)
# If any value is updated, then save the CSV and upload to blob
if is_updated == True:
customer_df.reset_index(drop=True, inplace=True)
customer_df.to_csv('./mock-data/sample-data/customer_mockdata_updated.csv')
# Upload the CSV file to the blob container
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=BLOB_NAME)
with open('./mock-data/sample-data/customer_mockdata.csv', 'rb') as data:
blob_client.upload_blob(data, overwrite=True, content_settings=ContentSettings(content_type='application/csv'))
# Upload the CSV file to the blob the history container
BLOB_NAME = "customer_mockdata_" + str(customer_id) + "_" + str(datetime.datetime.now().date())
blob_client = blob_service_client.get_blob_client(container=HISTORY_CONTAINER_NAME, blob=BLOB_NAME)
# with open('./mock-data/sample-data/customer_mockdata.csv', 'rb') as data:
# blob_client.upload_blob(data, overwrite=True, content_settings=ContentSettings(content_type='application/csv'))
print("\nUpdated Successfully.")
else:
print("\nNothing to update.")
else:
print("Customer with ID " + customer_id + " does not exist.")
Similarly, mock data have been created for Product, Transaction, and Account enities.
Design Data Product solution architecture¶
In this step, we determined the specific resources required to develop this Data Product. These resources include: Workflow, Policy, Scanner, and Soda stack.
Define performance target¶
In this step we define the quality checks needed to measure the performance of the Data Product.
Create Data Product manifest file¶
This is the final step, where we create a manifest file for Data Product as given below:
name: customer-overview-dp
version: v1alpha
type: data
tags:
- data-product
- dataos:type:product
- dataos:product:data
- dataos:product:data:customer-overview-dp
description: A unified, accurate, and persistent set of identifiers and attributes that describe a customer and that can be used to connect customer data across multiple organizational silos, and business processes and units. This mastered data, that is continuously live and up-to-date, can be fed to operational and analytical systems to drive business.
entity: product
v1alpha:
data:
domain: financial-services
resources:
- description: Data Product pipeline
purpose: build the data product's data set
type: workflow
version: v1
refType: dataos
name: wf-customer-overview-pipeline
workspace: fs-domain-workspace
inputs:
- description: customer_overview
purpose: source
refType: dataos
ref: dataos://twdepot:finance_service/customer_overview
outputs:
- description: Data Product Dataset
purpose: consumption
refType: dataos_address
ref: dataos://lakehousetw:fs_accelerator/customer_overview_dp
Apply the Data Product manifest file by executing the below command:
Develop¶
Steps required to build this Data Product are:
Create Flare jobs for Data Ingestion and Transformation¶
In this Data Product we are utilizing Flare Stack for the transformation of customer entity data, ensuring it is structured and optimized for further querying and analysis.
Steps
SELECT
*
FROM
customer_dp
WHERE
LENGTH(cust_id) = 10
AND LENGTH(cust_first_name) <= 35
AND cust_first_name IS NOT NULL
AND REGEXP_like(cust_first_name, '^[a-zA-Z]+$')
AND LENGTH(cust_last_name) <= 35
AND LENGTH(cibil_score) = 3
AND cibil_score BETWEEN 300 and 900
AND cibil_check_date is not null
AND country_code is not null
AND REGEXP_like(cust_last_name, '^[a-zA-Z]*$')
AND LENGTH(COALESCE(cust_middle_name, '') ) <= 35
or cust_middle_name is null
AND REGEXP_like(cust_middle_name, '^[a-zA-Z]*$')
AND LENGTH(mobile_number1) <= 10
AND LENGTH(customer_addressline1) <= 50
AND LENGTH(customer_addressline2) <= 50
AND LENGTH(customer_addressline3) <= 50
AND LENGTH(city) <= 30
AND LENGTH(state) <= 30
AND LENGTH(pin) <= 10
AND LENGTH(email_addr) <= 50
AND REGEXP_like(email_addr, '^[a-z0-9.]+@[a-z]+\.[a-z]{2,3}')
AND cust_segment IN ('Urban', 'Rural', 'Semi-Urban')
AND cust_title IN (
'Mr',
'Miss',
'Mrs',
'Mx',
'Dr'
)
AND customer_category IN ('Non Resident', 'Resident Indian')
AND customer_privelege IN ('Yes', 'No')
AND customer_type IN ('Personal', 'Corporate', 'Merchant')
AND gender IN (
'Male',
'Female',
'Non Binary',
'Transgender',
'Intersex',
'I prefer not to say'
)
AND marital_status IN (
'Single',
'Married',
'Widowed',
'I prefer not to say'
)
AND minor_flag IN ('Yes', 'No')
AND occupation IN ('Salaried', 'Non Salaried')
AND senior_citizen_flag IN ('Yes', 'No')
AND sourcing_channel IN ('Branch', 'Partner', 'Online')
AND customer_risk_category IN ('High', 'Medium', 'Low')
AND afflunce_level IN ('High', 'Medium', 'Low')
AND customer_status IN ('Active', 'Dormant', 'Deceased')
AND country IN (
'France',
'Italy',
'Spain',
'Germany',
'Netherlands',
'Australia',
'Brazil',
'Canada',
'India',
'Indonesia',
'Norway',
'Singapore',
'United States'
)
AND nationality IN (
'Australian',
'Brazilian',
'Canadian',
'European',
'Indian',
'Indonesian',
'Norwegian',
'Singaporean',
'American'
)
AND REGEXP_like(cast(cibil_check_date as string) , '^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$')
Flare Worflow manifest
version: v1
name: wf-customer-overview-raw-data
type: workflow
tags:
- customer-overview
description:
workflow:
title: Fs Customer Overview Raw Dataset
dag:
- name: customer-overview-raw-data
title: Fs Customer Overview Raw Dataset
description: This job will give fs customer overview data
spec:
stack: flare:5.0
compute: fs-runnable-default
stackSpec:
driver:
coreLimit: 1800m
cores: 1
memory: 2048m
executor:
coreLimit: 3200m
cores: 1
instances: 2
memory: 3800m
job:
explain: true
inputs:
- name: customer
dataset: dataos://twdepot:finance_service/customer_overview
format: csv
logLevel: INFO
steps:
- /jobsfolder/data-product/transformation/steps/steps-raw.yaml
outputs:
- name: final
dataset: dataos://lakehousetw:${SCHEMA}/customer_overview_raw?acl=rw # option: lakehouse
format: iceberg
description: This dataset gives you details of all customer data and their corresponding attributes
tags:
- demo.customer
options:
saveMode: overwrite # option: append
iceberg:
merge:
onClause: "old.cust_id = new.cust_id AND old.modified_at = new.modified_at"
whenClause:
"NOT MATCHED THEN INSERT *"
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
title: Customer banking Raw Source Data
variables:
keepSystemColumns: "false"
sparkConf:
- spark.sql.shuffle.partitions: 1
- spark.default.parallelism: 2
- spark.sql.extensions: org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
Flare Worflow manifest
version: v1
name: fs-customer-overview-change
type: workflow
tags:
- financial_service
- customer-overview
description: This job will give fs customer overview dataset
workflow:
title: Fs customer Overview Dataset
dag:
- name: fs-customer-dp-dataset
title: Fs Customer Overview Dataset
description: This job will give fs Customer overview data
spec:
stack: flare:5.0
compute: fs-runnable-default
stackSpec:
driver:
coreLimit: 1800m
cores: 1
memory: 2048m
executor:
coreLimit: 3200m
cores: 1
instances: 2
memory: 3800m
job:
explain: true
inputs:
- name: customer_dp
dataset: dataos://lakehousetw:${SCHEMA}/customer_overview_raw?acl=rw
format: iceberg
incremental:
context: customer007
sql: >
with cte as (
SELECT
cust_id,
cast(cust_dob as date) cust_dob,
cust_first_name,
cust_last_name,
cust_middle_name,
cust_segment,
cust_title,
customer_category,
customer_privelege,
customer_type,
email_addr,
gender,
marital_status,
minor_flag,
mobile_number1,
nationality,
occupation,
senior_citizen_flag,
sourcing_channel,
customer_risk_category,
afflunce_level,
customer_status,
customer_addressline1,
customer_addressline2,
customer_addressline3,
city,
state,
country,
pin,
cast(created_at AS timestamp) created_at,
cast(modified_at AS timestamp) modified_at,
date(cast(cibil_check_date as timestamp)) cibil_check_date,
cast(cibil_score as int) cibil_score,
country_code,
ROW_NUMBER() OVER (PARTITION BY cust_id ORDER BY modified_at DESC) as rn
from customer007
)
select
cust_id,
cust_dob,
cust_first_name,
cust_last_name,
cust_middle_name,
cust_segment,
cust_title,
customer_category,
customer_privelege,
customer_type,
email_addr,
gender,
marital_status,
minor_flag,
mobile_number1,
nationality,
occupation,
senior_citizen_flag,
sourcing_channel,
customer_risk_category,
afflunce_level,
customer_status,
customer_addressline1,
customer_addressline2,
customer_addressline3,
city,
state,
country,
pin,
created_at,
modified_at,
cibil_check_date,
cibil_score,
country_code
FROM cte
where rn = 1 and 1 = $|start|
keys:
- name: start
sql: select 1
logLevel: INFO
steps:
- /jobsfolder/data-product/transformation/steps/steps.yaml
outputs:
- name: final
dataset: dataos://lakehousetw:${SCHEMA}/customer_overview_dp?acl=rw
format: iceberg
description: This dataset gives you details of all customer and their corresponding attributes.
tags:
- demo.customer_dp
options:
saveMode: overwrite
iceberg:
partitionSpec:
- type: identity
column: country
- type: identity
column: state
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
sparkConf:
- spark.sql.shuffle.partitions: 1
- spark.default.parallelism: 2
- spark.sql.extensions: org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
The above workflows involve various data transformations and writing to Lakehouse. Similarly, transformations have been applied to other entities.
Create workflow for Data Profiling¶
We utilized the Flare stack to carry out the data profiling task. Below is the manifest file for the data profiling job using the Flare stack.
Worflow manifest
version: v1
name: wf-customer-overview-profile
type: workflow
tags:
- profiling
description: The job performs profiling on customer data from lakehouse
workflow:
title: Customer Overview Profiler
dag:
- name: customer-overview-profile
title: Customer Overview Profiler
spec:
stack: flare:5.0
compute: fs-runnable-default
title: Customer Overview Profiler
persistentVolume:
name: persistent-v
directory: fides
stackSpec:
driver:
coreLimit: 1800m
cores: 1
memory: 2048m
executor:
coreLimit: 3200m
cores: 1
instances: 2
memory: 3800m
job:
explain: true
inputs:
- name: customer_data
dataset: dataos://lakehousetw:${SCHEMA}/customer_overview_dp?acl=rw
format: iceberg
incremental:
context: customer_dp_profile_03
sql: >
SELECT
cust_id,
cust_dob,
cust_first_name,
cust_last_name,
cust_middle_name,
cust_segment,
cust_title,
customer_category,
customer_privelege,
customer_type,
email_addr,
gender,
marital_status,
minor_flag,
nationality,
occupation,
senior_citizen_flag,
sourcing_channel,
customer_risk_category,
afflunce_level,
customer_status,
cast(mobile_number1 AS string) AS mobile_number1,
customer_addressline1,
customer_addressline2,
customer_addressline3,
city,
state,
country,
pin,
created_at,
modified_at
FROM
customer_dp_profile_03
WHERE
cust_segment = 'Semi'
AND country = 'United States'
AND occupation = 'Salaried'
AND city = 'Chicago'
AND 1 = $|start|
keys:
- name: start
sql: select 1
logLevel: INFO
profile:
level: basic
sparkConf:
- spark.sql.adaptive.autoBroadcastJoinThreshold: 40m
- spark.dynamicAllocation.enabled: true
- spark.driver.maxResultSize: 0
- spark.dynamicAllocation.executorIdleTimeout: 120s
- spark.dynamicAllocation.initialExecutors: 1
- spark.dynamicAllocation.minExecutors: 1
- spark.dynamicAllocation.maxExecutors: 2
- spark.dynamicAllocation.shuffleTracking.enabled: true
Create Policy for Governance¶
After transforming and storing the data in lakehouse, we now need to implement data governance policies.
version: v1
name: customeroverviewrawpiipolicy
type: policy
layer: user
description: "data policy to hash pii columns - test"
owner: iamgroot
policy:
data:
type: mask
priority: 80
selector:
user:
match: any
tags:
- "roles:id:restricted-acess"
column:
tags:
- "TW.mask"
mask:
operator: hash
hash:
algo: sha256
The above data masking policy will mask the data for the users with restricted-access role.
name: customerbucketdob
version: v1
type: policy
layer: user
description: "bucketing Date of Birth Sensitive information"
policy:
data:
type: mask
priority: 85
selector:
user:
match: any
tags:
- "roles:id:dob-bucketing"
column:
tags:
- "TW.dob"
mask:
operator: bucket_date
bucket_date:
precision : "quarter"
The above data masking policy will mask the specific columns with "TW.dob" tag, for the users with dob-bucketing role.
version: v1
name: customeroverviewrpiireaderpolicy
type: policy
layer: user
description: "data policy to allow read of pii columns - test"
owner:
policy:
data:
type: mask
priority: 75
selector:
user:
match: any
tags:
- roles:id:pii-reader
column:
tags:
- "TW.mask"
- "TW.dob"
mask:
operator: pass_through
Create Scanner workflow for metadata extraction¶
The Scanner is a stack orchestrated by Workflow to extract metadata. The following Scanner manifest scans metadata from the Depot named lakehousetw and registers it on Metis.
version: v1
name: wf-lakehousetw-depot-scanner
type: workflow
tags:
- lakehousetw
description: The job scans schema tables and register metadata
workflow:
dag:
- name: lakehousetw-depot-scanner
description: The job scans schema from lakehousetw depot tables and register metadata to metis
spec:
tags:
- scanner
stack: scanner:2.0
runAsUser: metis
compute: fs-runnable-default
stackSpec:
depot: dataos://lakehousetw
sourceConfig:
config:
schemaFilterPattern:
includes:
- ${SCHEMA}
Create Flare jobs for quality checks¶
We have implemented the Flare stack, orchestrated by Workflow, to perform quality checks. Below is the manifest file for the Flare stack configuration used for these quality checks.
version: v1
name: wf-customer-data-quality
type: workflow
tags:
- demo.customer
description: The job performs metrics calculations checks and metrix on customerdp overview
workflow:
title: Customer overview Quality Datasets
dag:
- name: customer-data-quality
title: Metrics and checks
description: The job performs metrics calculations checks and metrix on customer overview
spec:
stack: flare:5.0
compute: runnable-default
title: Customerdp data Quality Datasets
description: The job performs metrics calculations checks and metrix on customer overview
stackSpec:
driver:
coreLimit: 2400m
cores: 2
memory: 3072m
executor:
coreLimit: 3400m
cores: 2
instances: 2
memory: 4096m
job:
explain: true
logLevel: INFO
inputs:
- name: source
dataset: dataos://lakehousetw:${SCHEMA}/customer_overview_dp
format: iceberg
assertions:
- column: cust_id
validFormat:
regex: ^[A-Za-z0-9]{10}$
tests:
- duplicate_count == 0
- invalid_count == 0
- column: cust_segment
validFormat:
regex: ^\d{4}$
tests:
- duplicate_count == 0
- missing_count <= 0
- column: sourcing_channel
validFormat:
regex: ^[A-Za-z]{20}$
tests:
- duplicate_count == 0
- missing_count <= 0
- invalid_count == 0
- column: customer_risk_category
validFormat:
regex: ^[A-Za-z]{10}$
tests:
- duplicate_count == 0
- missing_count <= 0
- invalid_count == 0
- column: customer_category
validFormat:
regex: ^[A-Za-z]{4}$
tests:
- duplicate_count == 0
- missing_count <= 0
- invalid_count == 0
- column: customer_privelege
validFormat:
regex: ^[A-Za-z]{10}$
tests:
- duplicate_count == 0
- missing_count <= 0
- invalid_count == 0
Deploy¶
Having developed the Data Product, we must make it accessible to various Data Product personas for management and consumption on the Data Product Hub and Metis. Below is the manifest file for the FS Accelerator Data Product.
name: customer-overview-dp
version: v1alpha
type: data
tags:
- data-product
- dataos:type:product
- dataos:product:data
- dataos:product:data:customer-overview-dp
description: A unified, accurate, and persistent set of identifiers and attributes that describe a customer and that can be used to connect customer data across multiple organizational silos, and business processes and units. This mastered data, that is continuously live and up-to-date, can be fed to operational and analytical systems to drive business.
entity: product
v1alpha:
data:
domain: financial-services
resources:
- description: Data Product pipeline
purpose: build the data product's data set
type: workflow
version: v1
refType: dataos
name: wf-customer-overview-pipeline
workspace: fs-domain-workspace
inputs:
- description: customer_overview
purpose: source
refType: dataos
ref: dataos://twdepot:finance_service/customer_overview
outputs:
- description: Data Product Dataset
purpose: consumption
refType: dataos_address
ref: dataos://lakehousetw:fs_accelerator/customer_overview_dp
After the Data Product is successfully deployed, It is ready to be consumed by the Data Product consumers to create dashboards.
Data Product Consumption¶
This Data Product is utilized to generate dashboards in Superset. We have developed three distinct dashboards: one for visualizing campaign performance, another for lead generation analysis, and a third for spend analysis. Let's see each one in detail.
Campaign Funnel Dashboard¶
Campaign Funnel Dashboard provides a comprehensive overview of a marketing campaign's performance by tracking the progression of customers through different stages of the campaign funnel. The dashboard is divided into two main sections: the Campaign Funnel and Campaign Stats.
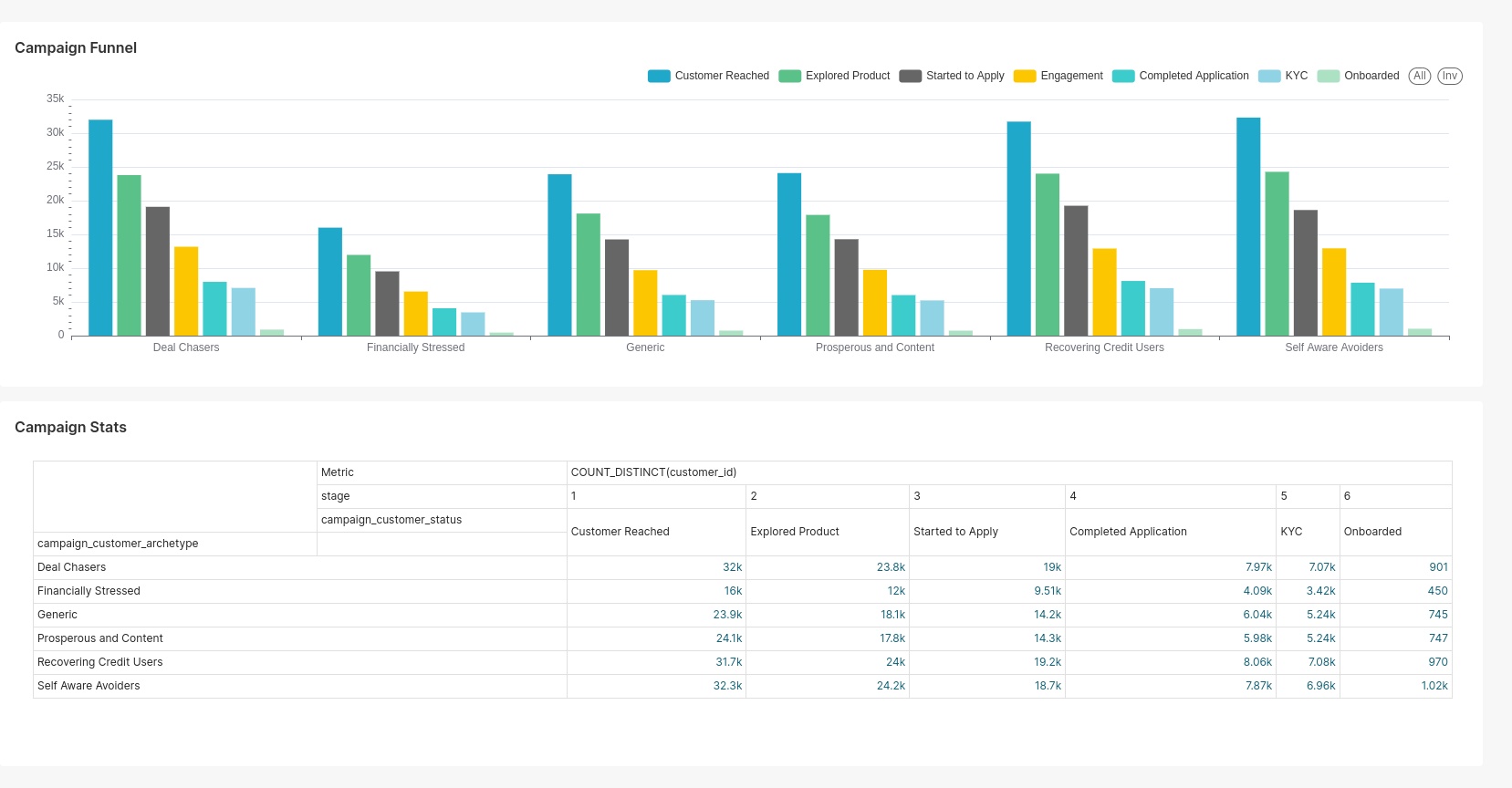
The Campaign Funnel section displays a bar chart of customers at various campaign stages for different archetypes: Deal Chasers, Financially Stressed, Generic, Prosperous and Content, Recovering Credit Users, and Self Aware Avoiders. Stages include Customer Reached, Explored Product, Started to Apply, Engagement, Completed Application, KYC, and Onboarded. The Campaign Stats section provides a table summarizing the count of customers at each stage for these archetypes, allowing for a quick comparison and highlighting campaign effectiveness for each group.
Lead Generation Dashboard¶
Lead Generation Dashboard provides an extensive overview of customer data, segmented across various dimensions to facilitate a deeper understanding of customer behaviors, demographics, and sales performance. The dashboard is divided into several key sections:
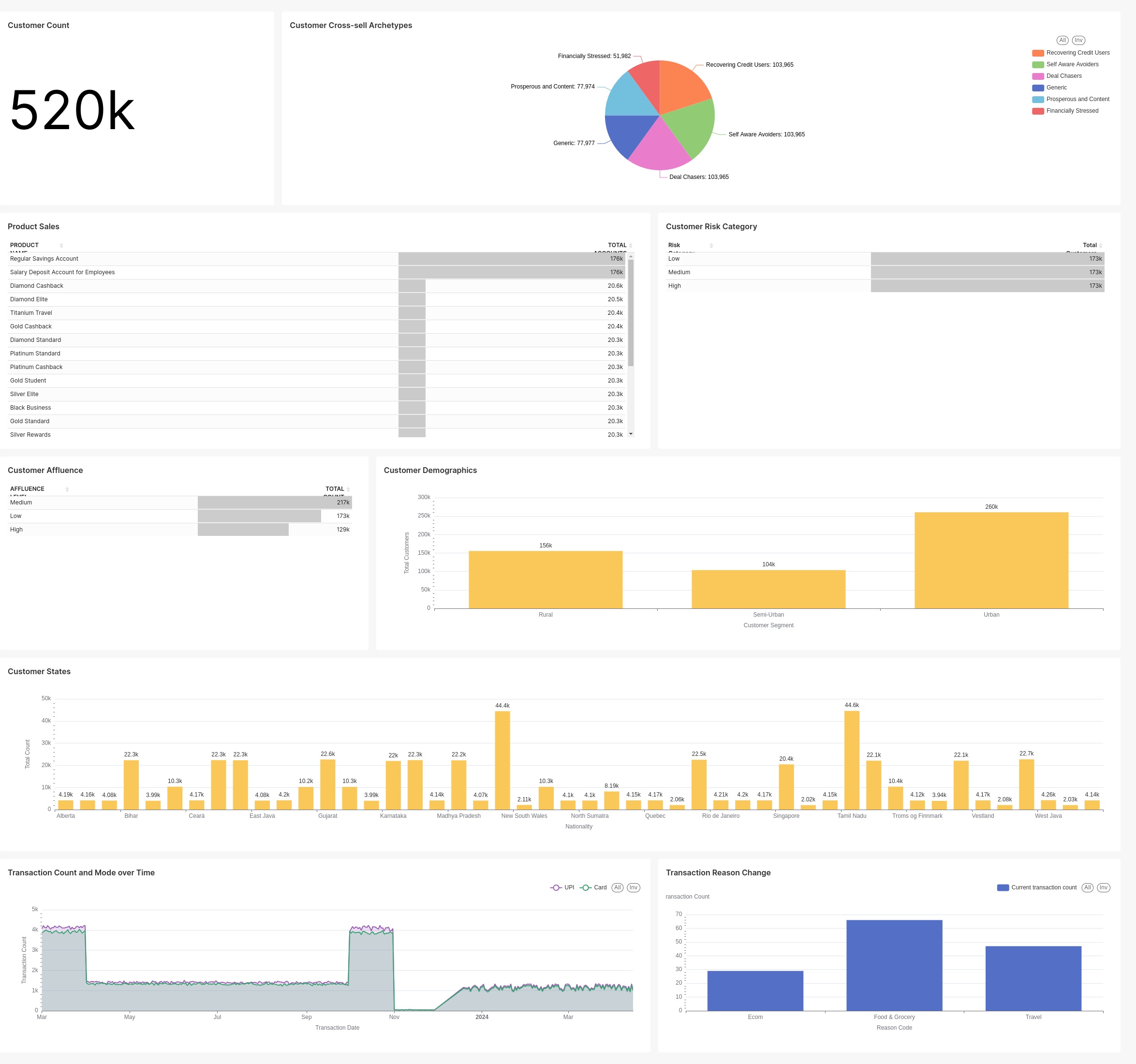
This dashboard displays key metrics: a total customer count of 520k, with segmentation by cross-sell archetypes shown in a pie chart. Sales data for various products and their contribution to total sales are visualized in a bar chart. Customer risk categories (Low, Medium, High) and affluence levels are also depicted in bar charts, each showing similar distributions (Low: 62%, Medium: 17%, High: 21%). Demographics are broken down into Rural (156k), Semi-Urban (126k), and Urban (238k) in another bar chart. Geographic distribution of customers by states is shown, along with a line chart tracking transaction counts and modes (UPI, QR, Card) over time. Lastly, a bar chart analyzes reasons for transactions, such as Exam, Food & Grocery, and Travel.
Spend Analysis Dashboard¶
Spend Analysis Dashboard provides an in-depth analysis of customer spending behaviors over time, segmenting the data across various dimensions to offer a comprehensive view of spending patterns and trends. The dashboard is divided into several key sections:
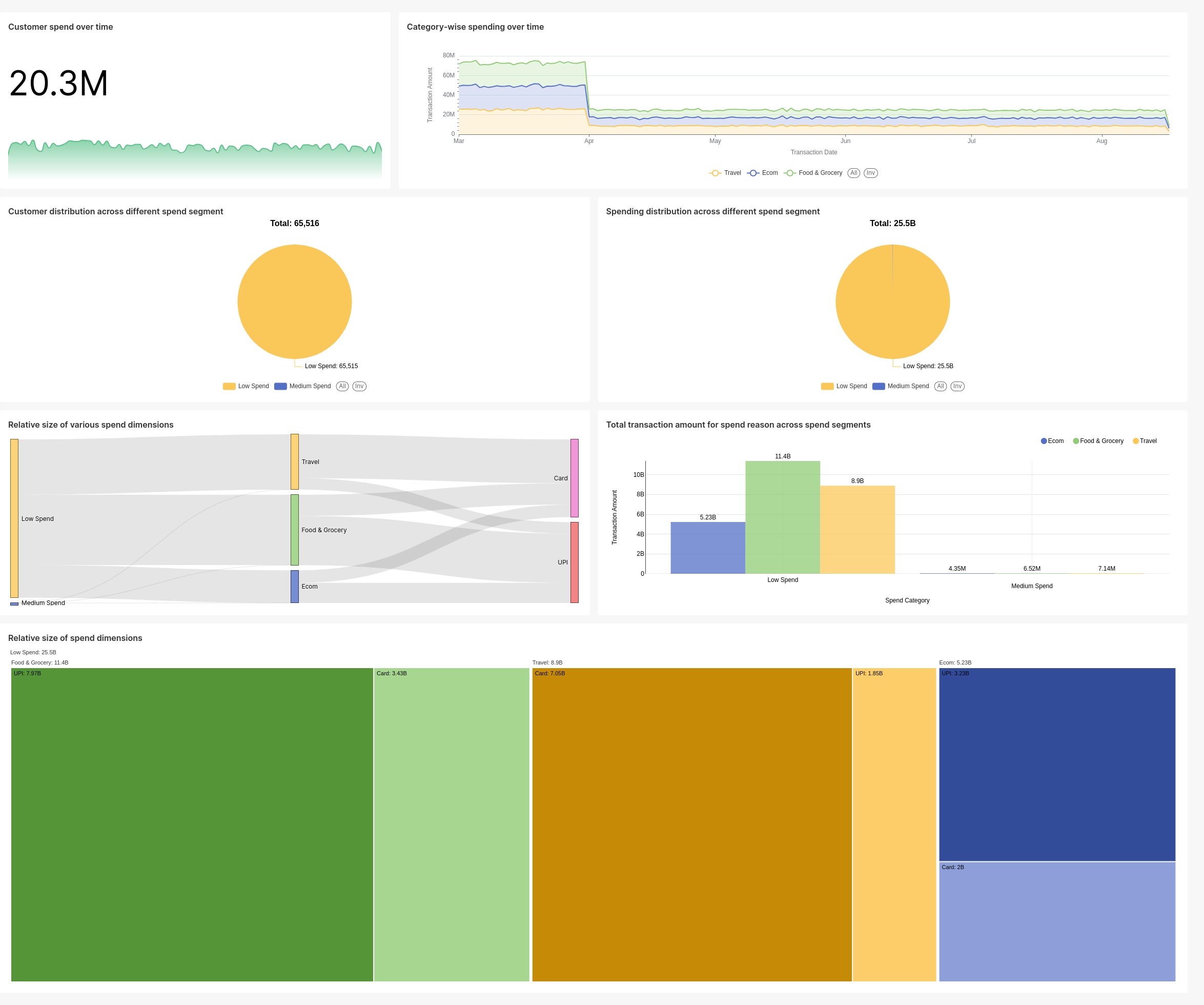
This dashboard tracks customer spending with a line chart showing a cumulative spend of 20.3M over time. Category-wise spending (Travel, Ecom, Food & Grocery) trends are also highlighted. A pie chart shows customer distribution, with 65,516 in the Low Spend segment. Another pie chart depicts spending distribution, with Low Spend at 25.5B. A Sankey diagram illustrates spend flow across dimensions like Travel, Food & Grocery, UPI, and Card. Transaction amounts for different reasons are compared in a bar chart: Low Spend (Ecom: 5.28B, Food & Grocery: 11.8B, Travel: 8.9B) and Medium Spend (Ecom: 4.73M, Food & Grocery: 6.52M, Travel: 7.14M). Finally, a treemap shows the relative size of spend dimensions, including Low Spend (25.5B), Food & Grocery (6.1B), Travel (8.9B), UPI (1.95B), Card (3.24B), and Exam (5.28B).