Benthos¶
Benthos is a high-performance and resilient stream processing stack within DataOS that provides an easy-to-use declarative YAML programming paradigm for performing common data engineering tasks such as transformation, mapping, schema validation, filtering, hydrating, multiplexing, and enrichment with simple, chained, stateless processing steps. It allows users to quickly adapt their data pipelines as requirements change by interacting with other services and then can write to one or more sinks with the spectrum of connectors available out-of-the-box with it.
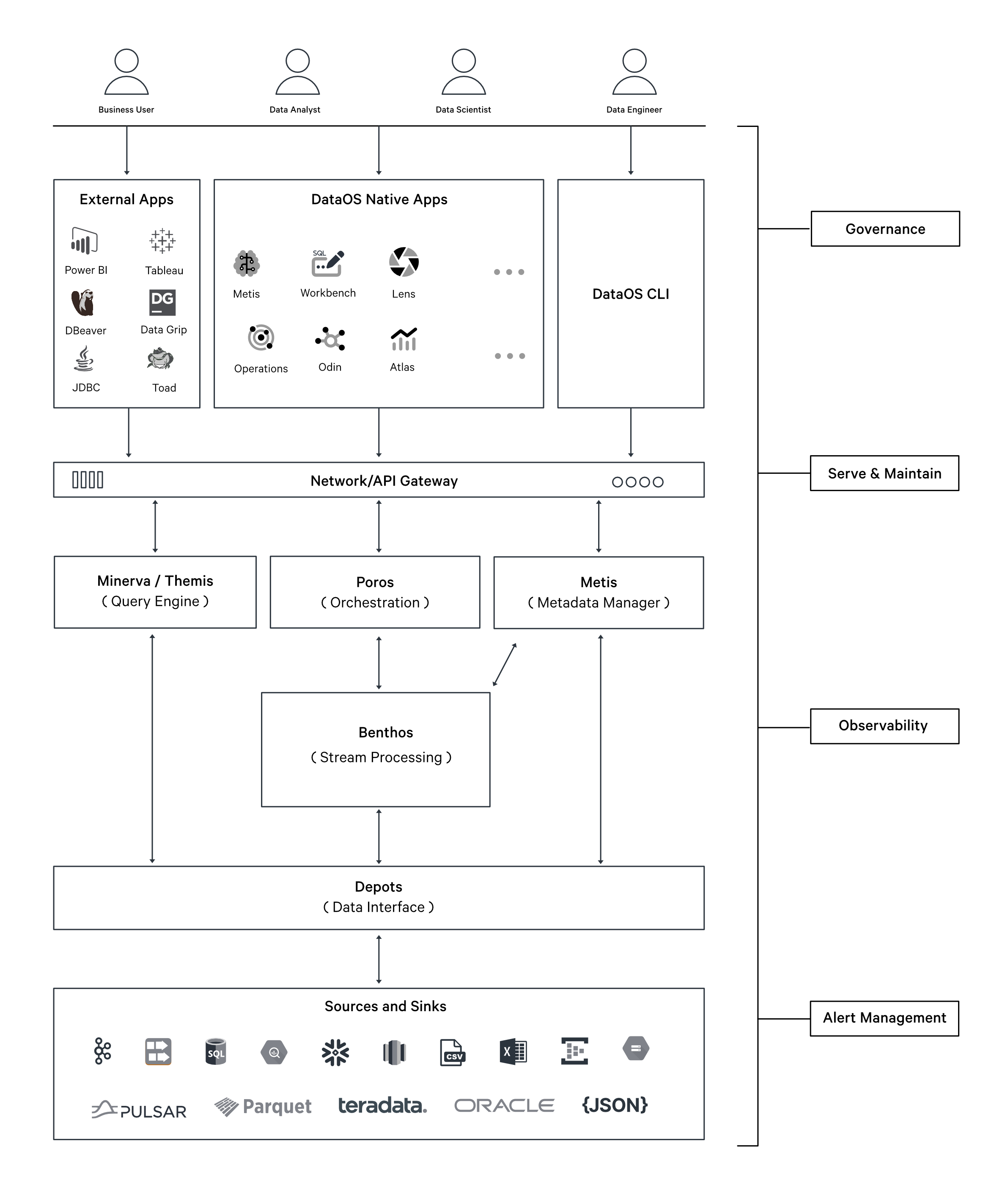 Placement of Benthos stack within DataOS
Placement of Benthos stack within DataOS
Benthos is designed to be reliable, with an in-process transaction model and no need for a disk-persisted state, and it’s easy to deploy and scale. Additionally, with supports for a wide range of processors and a “lit mapping language,” Bloblang, built-in. It also offers a visual web application called Benthos Studio that allows users to create, edit, and test configs.
Why use Benthos¶
Benthos offers a wide range of features that make it an ideal solution for stream processing, including:
-
No Runtime Dependencies: Benthos utilizes static binaries with no runtime library dependencies, simplifying deployment.
-
Resilient: Built with an in-process transaction model, Benthos ensures at-least-once delivery without persisting messages during transit. It gracefully handles back pressure by temporarily stopping consumption when output targets block traffic.
-
Scalability: Benthos is designed for horizontal scalability, allowing seamless scaling as data volume increases.
-
Declarative Configuration: Benthos employs a declarative approach, eliminating the need for code compilation or building.
-
Observability: Integration with Prometheus enables the collection of logs and metrics for better observability.
-
Cloud Native: Benthos is compatible with integration frameworks, log aggregators, and ETL workflow engines, making it a cloud-native solution that can complement traditional data engineering tools or serve as a simpler alternative.
-
Extensible: Benthos supports extension through Go plugins or subprocesses.
-
Stateless and Fast: Benthos is designed to be stateless and horizontally scalable. However, it can interact with other services to perform stateful operations.
-
Flexibility: Benthos allows connectivity with various sources and sinks using different brokering patterns. It facilitates single message transformation, mapping, schema validation, filtering, hydrating, and enrichment through interactions with other services, such as caching.
-
Bloblang: Benthos includes a built-in lit mapping language, Bloblang, which enables deep exploration of nested structures for extracting required information.
-
Payload Agnostic: Benthos supports structured data in JSON, Avro, or even binary formats, providing flexibility in data processing.
-
Real-time Data Processing: Benthos is designed for real-time data processing, making it suitable for scenarios requiring immediate ingestion and processing of generated data.
-
High Configurability: Benthos offers high configurability, allowing the construction of complex data processing pipelines that transform and enrich data during ingestion.
Now, let's dive into the details and explore Benthos further.
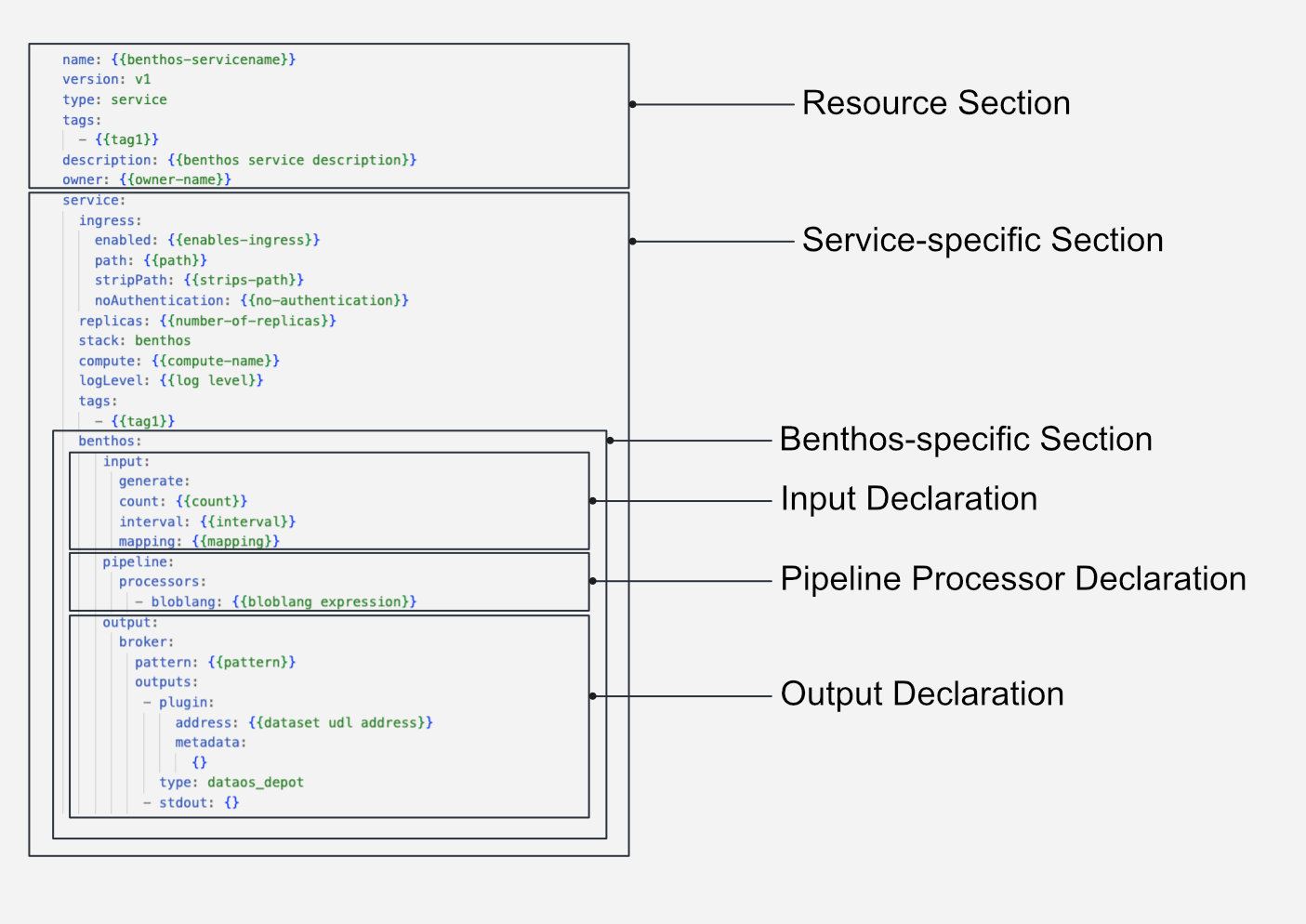
Syntax of Benthos YAML Configuration¶
Getting Started with Benthos¶
Setting Up Benthos Locally¶
Whether you're a seasoned data wrangler or a curious beginner, Benthos has something for you. Ready to take the plunge? Let's start by setting up Benthos locally.
Setting Up Benthos on DataOS¶
In DataOS, a Benthos streaming pipeline is implemented using the Service resource. Benthos Services allow for the quick definition of stream and event processing pipelines. To start your Benthos journey on DataOS, refer to the link below
Components of Benthos Pipeline¶
Benthos operates in a declarative manner, defining stream pipelines using a YAML configuration file. This file serves as a recipe, specifying the sources and transformation components required for data processing. Benthos offers a rich set of components within the YAML file. To learn more about these components, click on the link below:
Configuration¶
Effective configuration is crucial for utilizing the Benthos stack efficiently. With the right configuration settings, you can optimize your data processing pipelines, achieve maximum throughput, and handle errors effectively. Explore our comprehensive list on Benthos configuration, covering basic setup to advanced techniques:
Bloblang Guide¶
Tired of cumbersome data wrangling? Bloblang, the native mapping language of Benthos, provides a streamlined solution for data transformation. With its expressive and powerful syntax, Bloblang simplifies the process of transforming data without the need for complex scripts or convoluted pipelines. Discover the capabilities of Bloblang in our tutorial:
Recipes¶
Benthos, with its modular architecture and extensive range of processors, inputs/outputs, is perfect for creating real-time data processing recipes. Our collection of use cases and case scenarios demonstrates how Benthos can solve common data processing challenges. Explore the possibilities with Benthos: