Bento Stack¶
Bento is a stream processing Stack within DataOS that enables the definition of data transformations using a declarative YAML-based approach. It streamlines common data engineering tasks, including transformation, mapping, schema validation, filtering, hydrating, multiplexing, etc.
Bento employs stateless, chained processing steps, allowing stream data pipelines to adapt efficiently as requirements evolve. It integrates seamlessly with other services and provides built-in connectors for writing to various destinations.
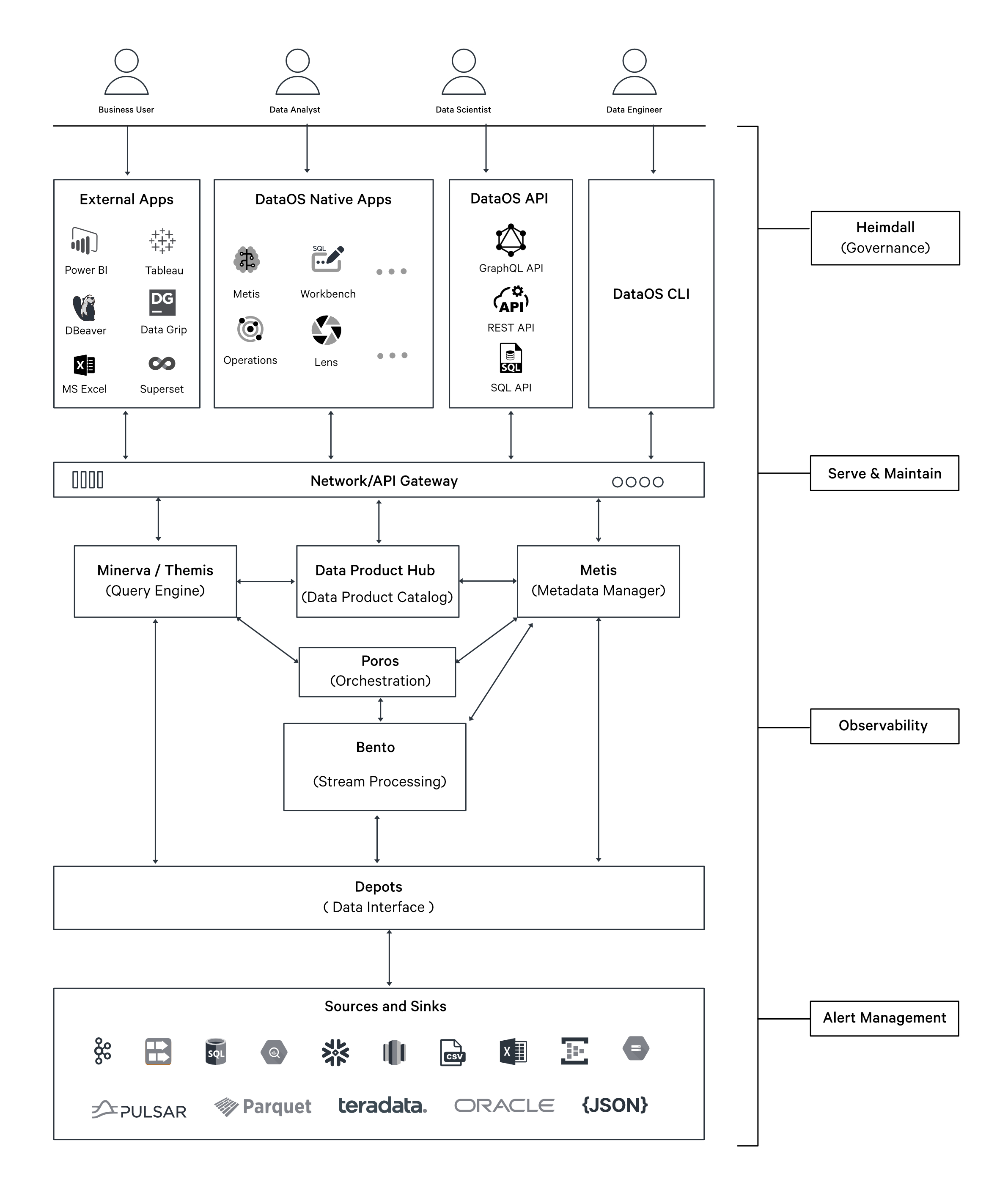
Bento Stack in the Data Product Lifecycle
Bento operates as a Stack and can be orchestrated using either a Worker or a Service Resource, depending on the use case. Bento-powered Workers and Services support the build phase of the Data Product Lifecycle by enabling:
- Stream data transformation – Continuous real-time processing, such as ingesting IoT sensor data into a messaging queue like Kafka and Pulsar.
- Independent processing – Long-running data transformations that do not require external network communication, such as standalone data processing streams.
Key features of Bento¶
Bento offers a wide range of features that make it an ideal solution for stream processing, which are as follows:
| Feature | Description |
|---|---|
| No Runtime Dependencies | Uses static binaries with no runtime library dependencies, simplifying deployment. |
| Resilient | Ensures at-least-once delivery without persisting messages during transit and gracefully handles back pressure. |
| Scalability | Designed for horizontal scalability to handle increasing data volume. |
| Declarative Configuration | Eliminates the need for code compilation or building through a declarative approach. |
| Observability | Integrates with Prometheus for logs and metrics collection. |
| Cloud Native | Compatible with integration frameworks, log aggregators, and ETL workflow engines. |
| Extensible | Supports extension through Go plugins or subprocesses. |
| Stateless and Fast | Stateless design with horizontal scalability and support for stateful operations via external services. |
| Flexibility | Connects to various sources and sinks using different brokering patterns. Supports mapping, validation, filtering, and enrichment. |
| Bloblang | Built-in mapping language for deep exploration of nested structures. |
| Payload Agnostic | Supports structured data formats like JSON, Avro, and binary formats. |
| Real-time Data Processing | Enables real-time ingestion and processing of data. |
| High Configurability | Allows construction of complex data pipelines for transformation and enrichment during ingestion. |
Now, let's dive into the details and explore Bento further.
Syntax of Bento Manifest Configuration¶
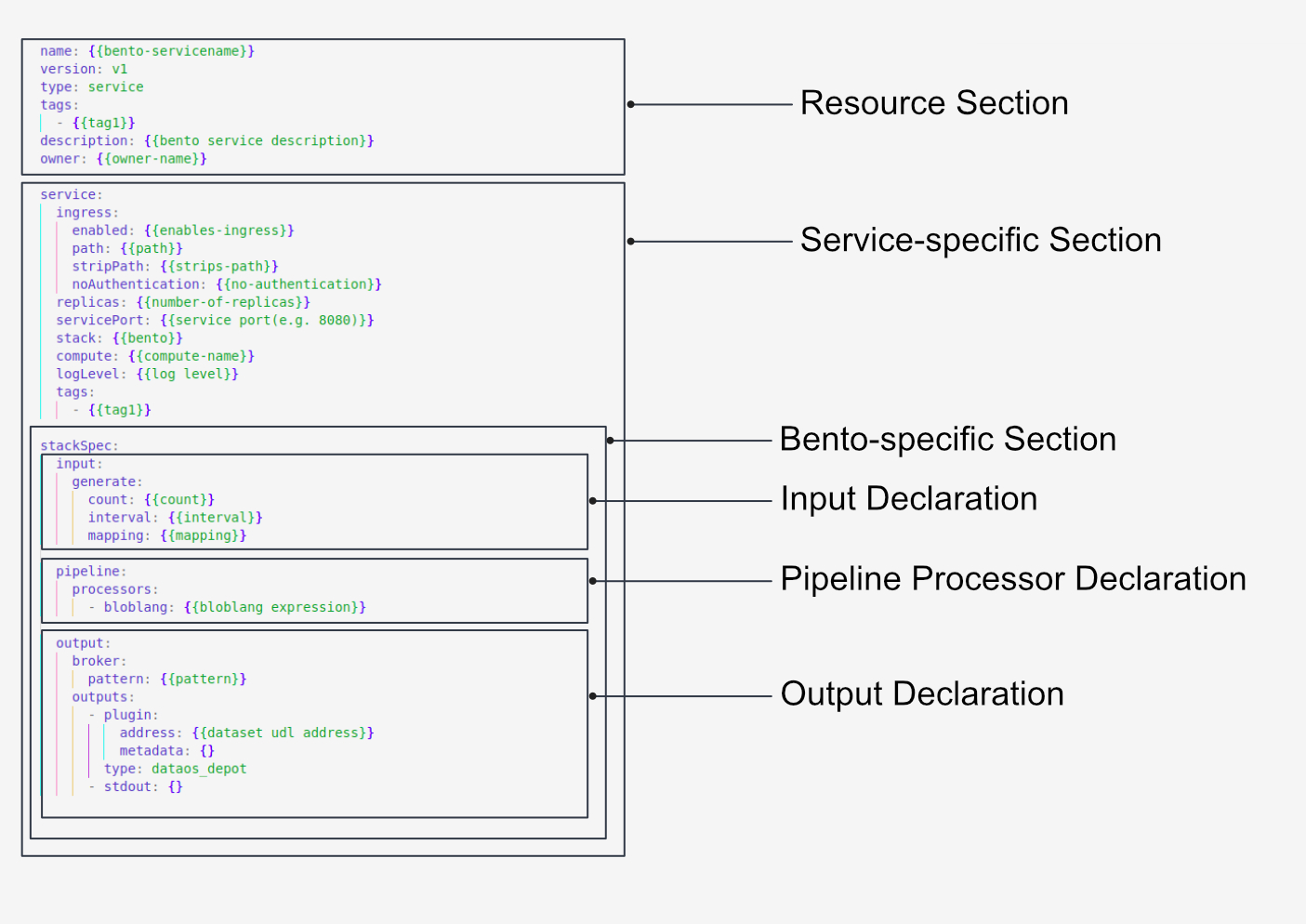
Getting Started with Bento¶
Setting Up Bento Locally¶
Bento offers functionality suitable for both experienced data professionals and those new to data management. Follow the steps below to set up Bento in a local environment.
Setting Up Bento on DataOS¶
In DataOS, a Bento streaming pipeline is implemented using the Service resource. Bento Services facilitate the efficient definition of stream and event processing pipelines. For detailed instructions on starting with Bento in DataOS, refer to the following link:
Components of Bento Pipeline¶
Bento operates in a declarative manner, defining stream pipelines using a YAML configuration file. This file serves as a recipe, specifying the sources and transformation components required for data processing. Bento offers a rich set of components within the YAML file. To learn more about these components, click on the link below: Components
Configuration¶
Effective configuration is essential for maximizing the efficiency of the Bento stack. Proper configuration settings enhance data processing performance, improve throughput, and ensure effective error handling. Refer to the comprehensive Bento configuration guide for details on both basic setup and advanced techniques: Configurations
Bloblang Guide¶
Tired of cumbersome data wrangling? Bloblang, the native mapping language of Bento, provides a streamlined solution for data transformation. With its expressive and powerful syntax, Bloblang simplifies the process of transforming data without the need for complex scripts or convoluted pipelines. Discover the capabilities of Bloblang in the following tutorial: Bloblang
Recipes¶
Bento, with its modular architecture and extensive range of processors, inputs/outputs, is perfect for creating real-time data processing recipes. Following collection of use cases and case scenarios demonstrates how Bento can solve common data processing challenges:
- How can rate limiting be performed in Bento pipelines?
- What techniques enable effective pagination in Bento workflows?
- What is the process for fetching stock data from an API to Lakehouse with Bento?
- What steps are involved in processing Twitter API data with Bento?
- How can data be fetched from the Instagram API using Bento?
- How can a Discord bot be integrated using Bento?