Aggregation Strategies
The following document helps determine the appropriate aggregation approach based on the situation, guiding whether to use a Lakehouse or Warehouse-centric strategy. It also highlights approaches to avoid.
Recommended practices¶
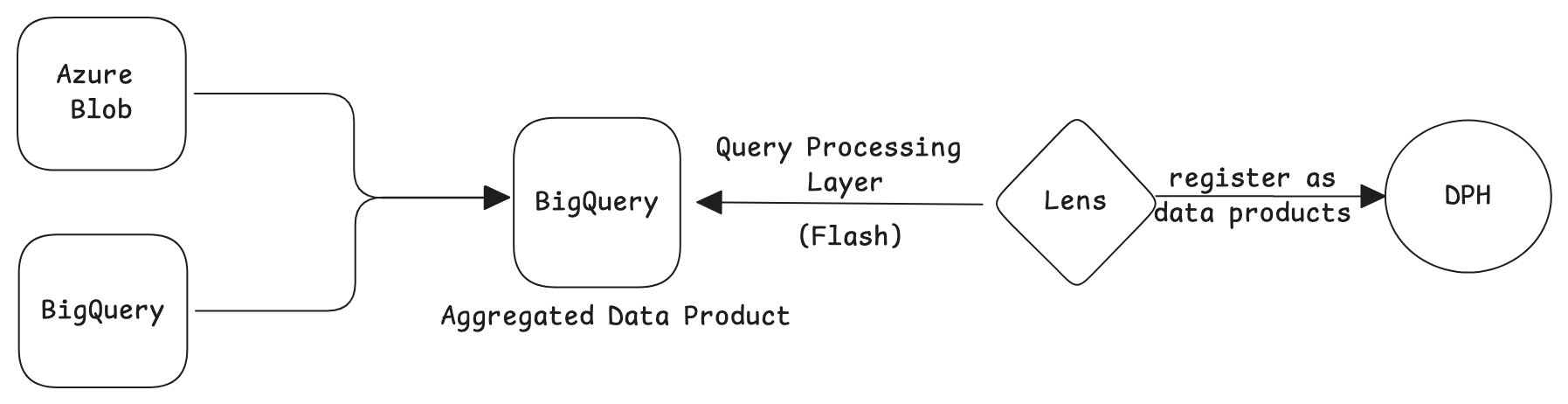
1. Pre-Aggregating physical tables before modeling (Lakehouse-centric Approach)¶
If the user chooses to create aggregated physical tables before modeling data in the Lakehouse the following points needs to be conisdered:
- The semantic model (Lens) will be built with Flash as the primary source.
- Flash serves as the query processing layer, enabling faster data retrieval.
This approach optimizes query performance by minimizing redundant computations.
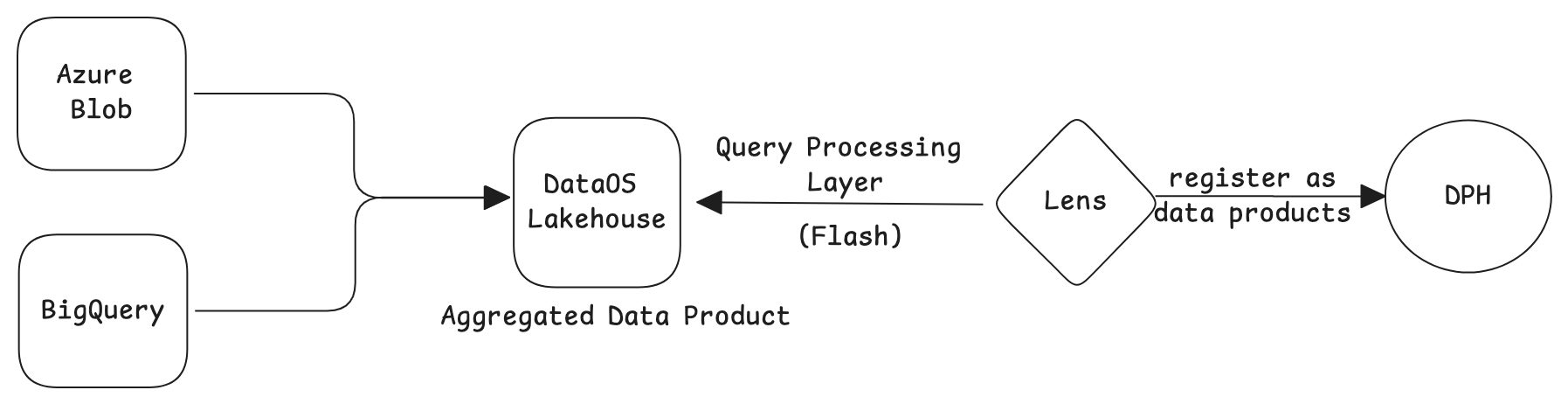
2. Pre-Aggregating physical tables before modeling (Warehouse-centric Approach)¶
If the user chooses to perform aggregation at the data warehouse level, the following points need to be considered:
- Aggregation occurs within the warehouse (such as BigQuery, Snowflake, or Redshift) before modeling.
- The warehouse engine handles both query optimization and execution.
This approach is well-suited for structured data processing and analytical workloads.
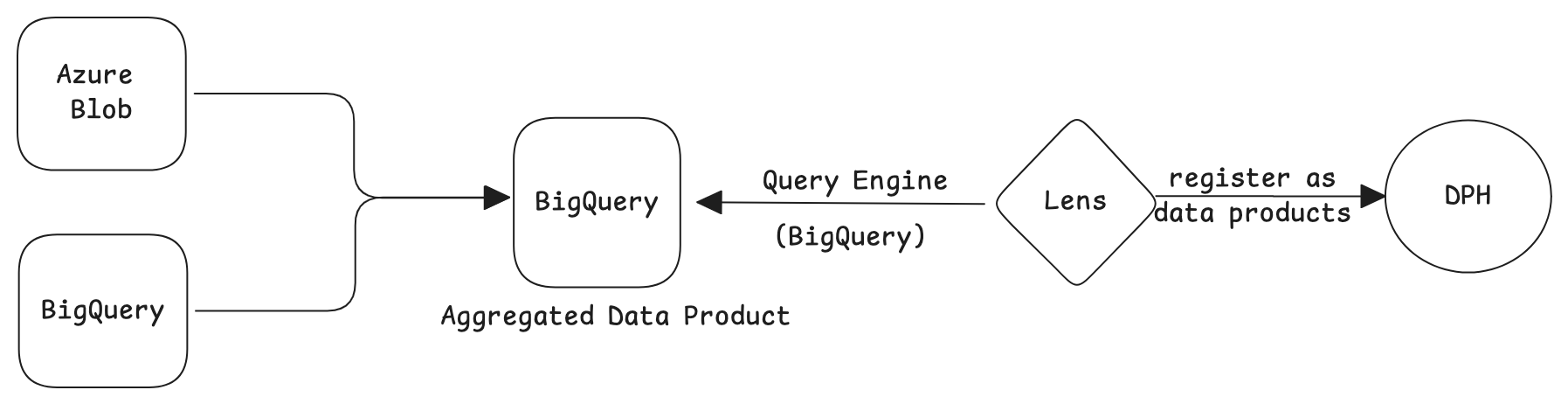
3. Using federation enginess Selectively (Exploration-Only Scenarios)¶
When working with data across multiple sources, federation engines can be helpful, but the following points should be considered:
- Use federation engines exclusively for data exploration and experimentation.
- Avoid using federation engines for data activation, as they may not consistently meet performance SLOs.
In such cases, directly querying the source system or using Flash for in-memory processing is often a more efficient alternative.
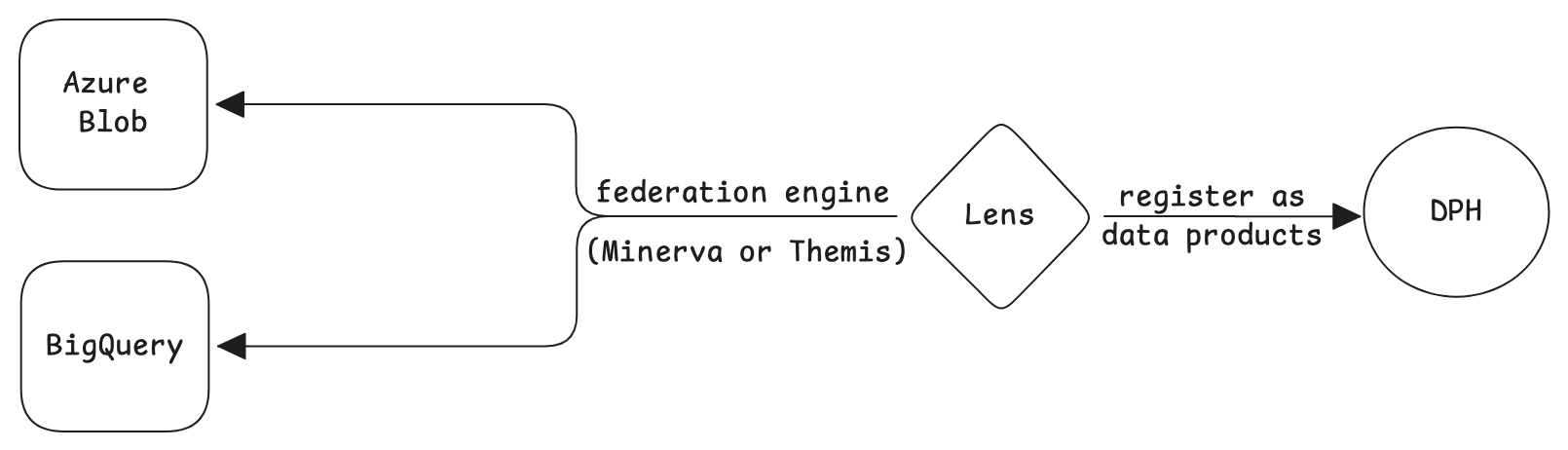
Practices to avoid¶
1. Using a federation engines on top of a warehouse query engines¶
Avoid layering federation engines on top of BigQuery, Snowflake, or Redshift. While technically viable, this approach diverges from best practices for the following reasons:
- Unnecessary Cost Overhead: Engaging multiple query engines where a single engine is sufficient leads to redundant computational expenses.
- Performance Degradation: Introducing an additional processing layer increases query latency and resource consumption, diminishing overall system efficiency.
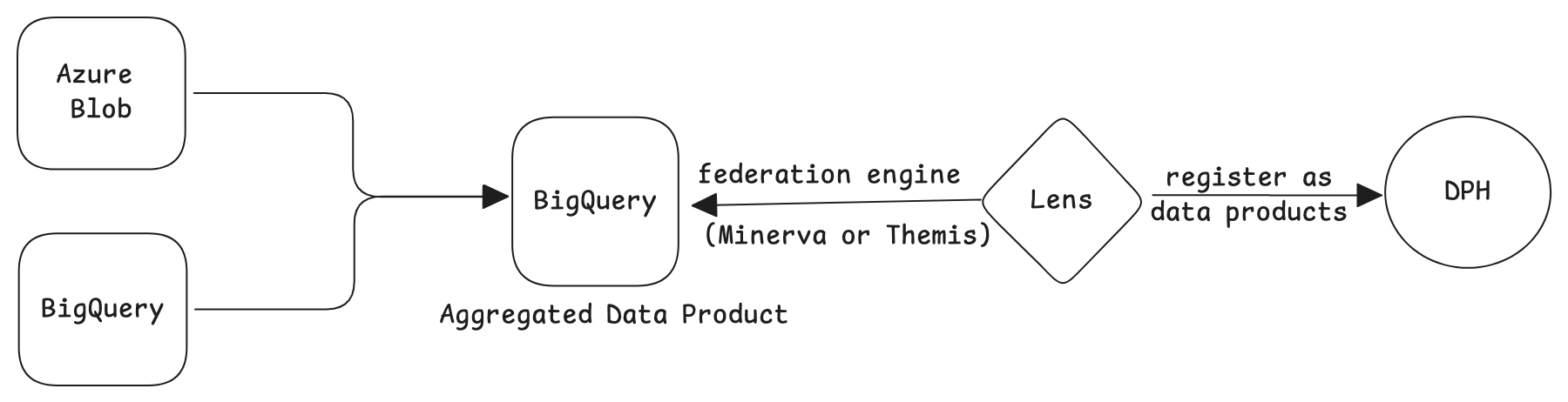
2. Using federation engines for single-source queries¶
Avoid utilizing a federation engine when querying data from a single source, as this design, while functional, is suboptimal. Flash is better suited to efficiently handle such use cases compared to federated engines like Minerva or Themis.
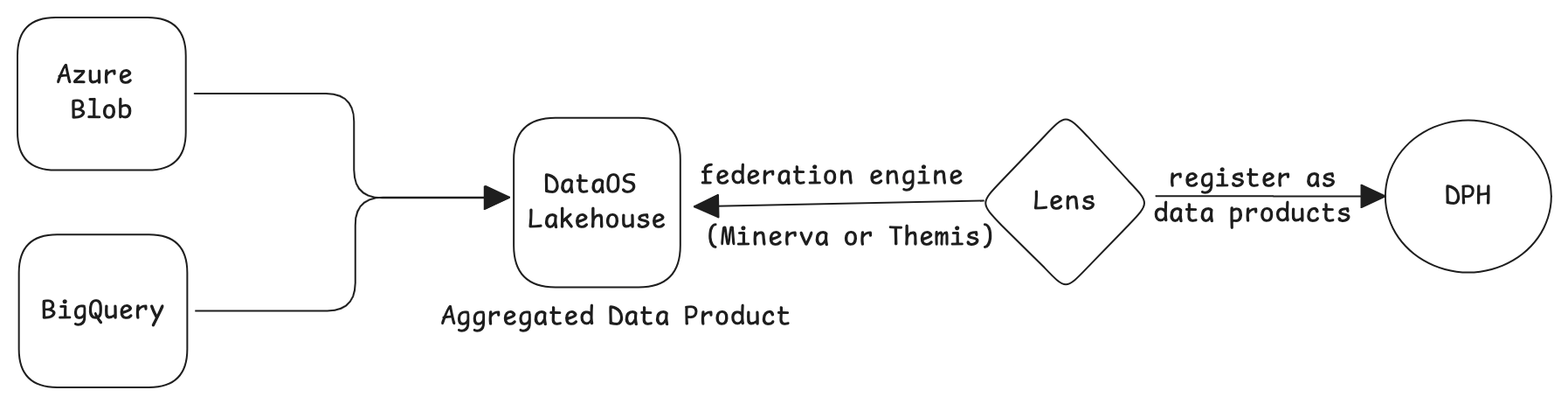
3. Using Flash when the source system’s query engine suffices¶
Avoid using Flash when the native query engine of the source system can be leveraged. While technically viable, employing both warehouse and Flash in such scenarios introduces redundancy, particularly when caching or data duplication is not required. This principle applies to all data warehouses such as Snowflake, Redshift, and BigQuery.