Lakesearch Query Rewriter¶
Lakesearch includes a Query Rewriter feature that dynamically modifies incoming queries before execution. This ensures that searches return more relevant results by applying contextual modifications, such as filtering or restructuring queries based on data partitions or predefined business rules.
In this implementation, the Query Rewriter adds a platform-based filter to every query, ensuring that only results matching "Windows" as the platform are retrieved.
How does the query rewriter work?¶
The following implementation defines a custom query rewriter that:
- Extracts the original match clause from the incoming query.
- Adds a filter to ensure results are scoped accordingly.
- Maintains the original search intent while enforcing the additional filter.
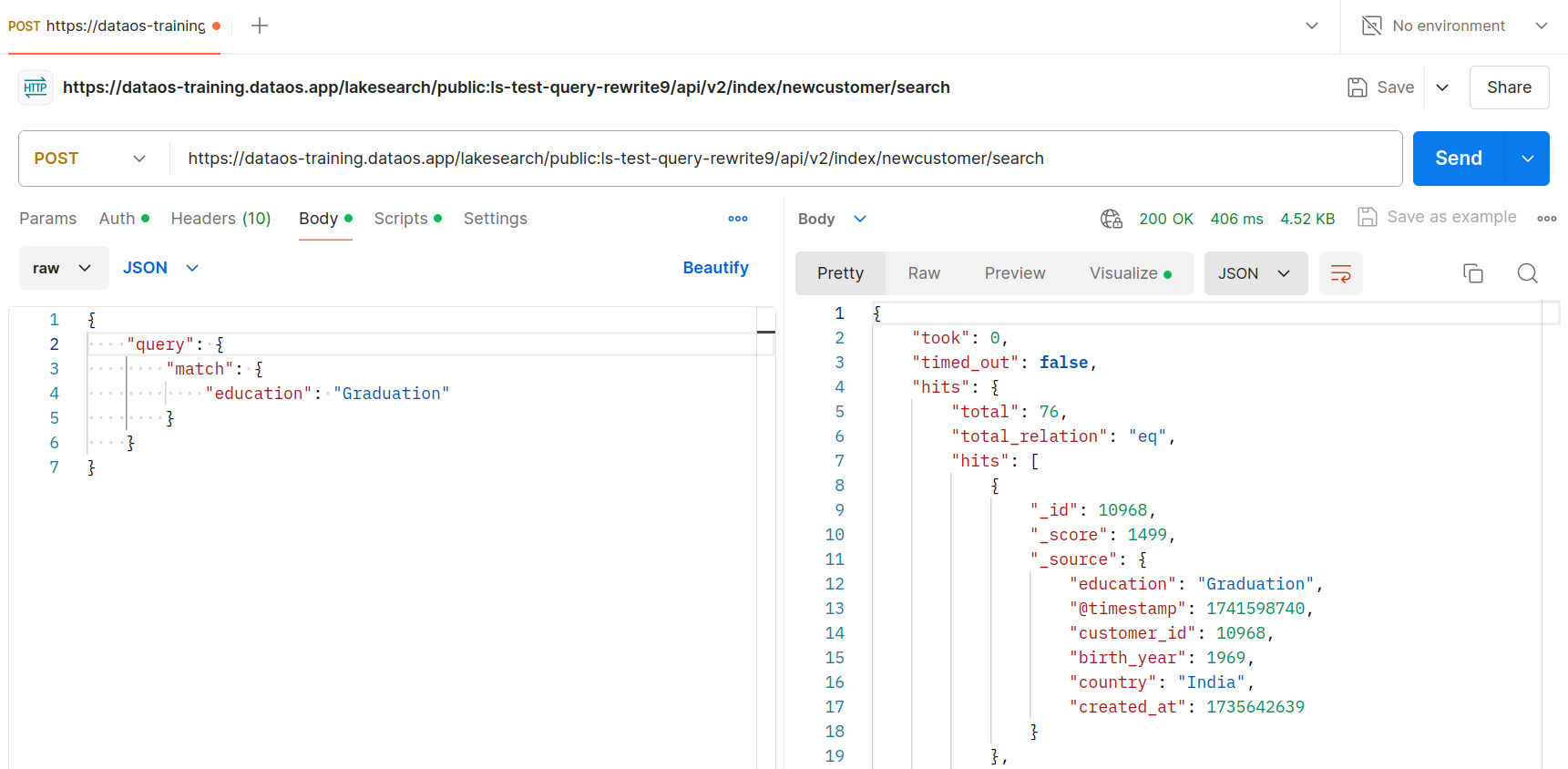
For example, in a scenario where users should only see data from their own country, a Python script can be created to automatically append a filter, such as "country" = "India", to every query, as shown below. Once this script is deployed in a Lakesearch Service, any request to the endpoint will return only the data where the country is India, ensuring restricted access based on predefined rules.
Pre-requisites¶
A user must have the following requirements met before setting up a Lakesearch Service.
-
A user is required to have knowledge of Python.
-
Ensure that DataOS CLI is installed and initialized in the system. If not the user can install it by referring to this section.
-
A user must have the following tags assigned.
dataos-ctl user get INFO[0000] 😃 user get... INFO[0001] 😃 user get...complete NAME │ ID │ TYPE │ EMAIL │ TAGS ───────────────┼─────────────┼────────┼──────────────────────┼───────────────────────────────── Iamgroot │ iamgroot │ person │ iamgroot@tmdc.io │ roles:id:data-dev, │ │ │ │ roles:id:user, │ │ │ │ users:id:iamgroot -
If the above tags are not available, a user can contact a DataOS operator to assign the user with one of the following use cases using the Bifrost Governance. A DataOS operator can create new usecases as per the requirement.
Bifrost Governance -
Ensure the Lakesearch Stack is available in the DataOS Environment. To deploy the Lakesearch Stack in your DataOS Environment follow the below steps.
Create a Lakesearch Stack manifest file using the template below and apply it to make the Lakesearch Stack available:
lakesearch_stack.yaml
name: lakesearch-v2 version: v1alpha type: stack tags: - dataos:type:resource - dataos:resource:stack - dataos:type:cluster-resource - dataos:layer:user description: dataos lakesearch stack v1alpha version 2 layer: user stack: name: lakesearch version: '2.0' reconciler: stackManager image: registry: docker.io repository: tmdcio image: lakesearch tag: 0.4.0 auth: imagePullSecret: dataos-container-registry environmentVars: DEPOT_SERVICE_URL: https://${{dataos-fqdn}}/ds ENABLE_SET_ULIMITS: '1' GIN_MODE: release HEIMDALL_URL: https://${{dataos-fqdn}}/heimdall/ LAKESEARCH_CONFIG_PATH: /etc/dataos/config/lakesearch.yaml LAKESEARCH_GRPC_SERVER_PORT: '4090' PROJECT_ROOT_PATH: /go/src/bitbucket.org/rubik_/lakesearch PUSHGATEWAY_URL: http://thanos-query-frontend.sentinel.svc.cluster.local:9090 SEARCHD_TEMPLATE_PATH: /etc/searchd/searchd.conf.tmpl SEARCHD_URL: http://localhost:9308 stackSpecValueSchema: jsonSchema: | { "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "properties": { "lakesearch": { "type": "object", "properties": { "index_tables": { "items": { "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" }, "source": { ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] ] }, "indexers": { "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" "type": "array" } } } } } serviceConfig: configFileTemplate: | lakesearch.yaml: | {{ toYaml .ApplicationSpec.StackSpec | indent 2 }} containerResourceTemplate: | container: name: "{{.Name}}{{.Stamp}}-indexer" image: "{{.Image}}" imagePullPolicy: IfNotPresent command: - "/usr/bin/lakesearch" ports: - containerPort: 4080 volumeMounts: {{ if .HasConfigConfs }} - name: dataos-config-mount mountPath: "{{.DataOsConfigMountPath}}" readOnly: true {{- end }} {{ if .ApplicationSpec.TempVolume -}} - name: {{.Name}}-{{.Type}}{{.Stamp}}-tdm mountPath: "{{.DataTempMountPath}}" subPath: {{.Name}}{{.Stamp}} {{- end }} {{ if .ApplicationSpec.PersistentVolume -}} - name: {{.Name}}-{{.Type}}{{.Stamp}}-pdm mountPath: "{{.DataPersistentMountPath}}/{{.ApplicationSpec.PersistentVolume.Directory}}" subPath: "{{.ApplicationSpec.PersistentVolume.Directory}}" {{- end }} {{ if .Volumes }} {{- range $volume := .Volumes }} - name: {{$volume.Name}} mountPath: "{{$volume.MountPath}}" readOnly: {{$volume.ReadOnly}} {{ if $volume.SubPath }} subPath: "{{$volume.SubPath}}" {{- end }} {{- end }} {{- end }} {{ if .ApplicationSpec.Resources -}} resources: {{toYaml .ApplicationSpec.Resources | indent 4}} i>.... {{- end }} envFrom: - secretRef: name: "{{.Name}}-{{.Type}}{{.Stamp}}-env" {{ if .EnvironmentVarsFromSecret }} {{- range $secName := .EnvironmentVarsFromSecret }} - secretRef: name: "{{$secName}}" {{- end }} {{- end }} sidecars: - name: "{{.Name}}{{.Stamp}}-searcher" image: "{{.Image}}" imagePullPolicy: IfNotPresent command: - /usr/bin/lakesearch ports: - containerPort: 9306 - containerPort: 9308 - containerPort: 9312 securityContext: privileged: true volumeMounts: {{ if .HasConfigConfs }} - name: dataos-config-mount mountPath: "{{.DataOsConfigMountPath}}" readOnly: true {{- end }} {{ if .ApplicationSpec.TempVolume -}} - name: {{.Name}}-{{.Type}}{{.Stamp}}-tdm mountPath: "{{.DataTempMountPath}}" subPath: {{.Name}}{{.Stamp}} {{- end }} {{ if .ApplicationSpec.PersistentVolume -}} - name: {{.Name}}-{{.Type}}{{.Stamp}}-pdm mountPath: "{{.DataPersistentMountPath}}/{{.ApplicationSpec.PersistentVolume.Directory}}" subPath: "{{.ApplicationSpec.PersistentVolume.Directory}}" {{- end }} {{ if .Volumes }} {{- range $volume := .Volumes }} - name: {{$volume.Name}} mountPath: "{{$volume.MountPath}}" readOnly: {{$volume.ReadOnly}} {{ if $volume.SubPath }} subPath: "{{$volume.SubPath}}" {{- end }} {{- end }} {{- end }} envFrom: - secretRef: name: "{{.Name}}-{{.Type}}{{.Stamp}}-env" {{ if .EnvironmentVarsFromSecret }} {{- range $secName := .EnvironmentVarsFromSecret }} - secretRef: name: "{{$secName}}" {{- end }} {{- end }} env: - name: MODE value: searchd secretProjection: type: propFileApply the Stack manifest file using the following command:
-
Configure Volume Resource for storage allocation. Follow the below steps to configure a Volume Resource.
-
Copy the template below and replace
with your desired Resource name and with the appropriate volume size (e.g., 100Gi, 20Gi, etc.), according to your available storage capacity. Make sure the configuration is aligned with both your storage and performance requirements. For the accessMode, you can choose ReadWriteOnce (RWO) for exclusive read-write access by a single node, or ReadOnlyMany (ROX) if the volume needs to be mounted as read-only by multiple nodes. name: <name> # Name of the Resource version: v1beta # Manifest version of the Resource type: volume # Type of Resource tags: # Tags for categorizing the Resource - volume description: Common attributes applicable to all DataOS Resources layer: user volume: size: <size> # Example: 100Gi, 50Mi, 10Ti, 500Mi, 20Gi accessMode: <accessMode> # Example: ReadWriteOnce, ReadOnlyMany type: tempTo check the dataset size, use the following query:
The resultant size will be in the bytes. -
Apply the Volume manifest file
Apply the persistent volume manifest file, using the following command in terminal:
This will deploy the Persistent Volume Resource, making it available for use by Lakesearch Service.
-
Steps¶
-
Create a Python file containing the below code by replacing
"platform": "Windows"with the key:value by which the data will be filtered. Also ensure while indexing the column by which the data will be filtered should be one of these types:keyword,int,bigint,bool,timestamp, orfloatin a Lakesearch Service.from py.lakesearch.query_rewriter_config import QueryRewriterConfig from py.lakesearch.registrar import Registrar class ImplementQueryRewriter(QueryRewriterConfig): def rewrite_query(self, token: str, user: dict, index: str, query: dict) -> dict: """Modify the incoming query to enforce filtering on platform='Windows'""" # Extract existing match clause match_clause = query["query"]["match"] # Wrap the match clause in a dictionary if it exists final_result = {"match": match_clause} if match_clause else None # Define the additional filter filter_clause = { "equals": { "platform": "Windows" # The value to filter by } } # Construct the final query if match_clause: updated_query = { "query": { "bool": { "must": [ filter_clause, # Add the filter clause final_result # Add the original match clause ] } } } else: # If no match clause exists, apply only the filter updated_query = { "query": { "bool": { "must": [filter_clause] } } } return {"query": updated_query} # Register the custom query rewriter Registrar.setQueryRewriter(ImplementQueryRewriter())Statement Description Mandatory from py.lakesearch.query_rewriter_config import QueryRewriterConfigThis line imports a base class (or configuration interface) named QueryRewriterConfigfrom thepy.lakesearch.query_rewriter_configmodule. This base class defines the structure and required methods for the query rewriter that you want to implement.YES from py.lakesearch.registrar import RegistrarThis import brings in the Registrarclass from thepy.lakesearch.registrarmodule. The purpose of this class is to register your custom query rewriter so that the system knows to use it when processing queries.YES -
Create a Lakesearch Service manifest file with the following YAML configuration by referring the Python and requirement file in the
configsection of the Lakesearch Service:name: ls-test-query-rewrite version: v1 type: service tags: - service - dataos:type:resource - dataos:resource:service - dataos:layer:user description: Lakesearch Service v4 workspace: public service: servicePort: 4080 ingress: enabled: true stripPath: false path: /lakesearch/public:ls-test-query-rewrite noAuthentication: true replicas: 1 logLevel: 'DEBUG' compute: runnable-default envs: LAKESEARCH_SERVER_NAME: "public:ls-test-query-rewrite" DATA_DIR: public/ls-test-query-rewrite/data02 USER_MODULES_DIR: /etc/dataos/config persistentVolume: name: ls-v2-test-vol directory: public/ls-test-query-rewrite/data02 resources: requests: cpu: 1000m memory: 1536Mi stack: lakesearch:4.0 configs: ex_impl_query_rewriter.py: /Users/iamgroot/Documents/Work/lakesearchv2/query-rewriter/user_modules/ex_impl_query_rewriter.py stackSpec: lakesearch: source: datasets: - name: devices dataset: dataos://lakehouse:ls_data/devices_with_d index_tables: - name: devices description: "index for devices" tags: - devices properties: morphology: stem_en partitions: - devices_before_110125 - devices_after_110125 columns: - name: row_num type: bigint - name: id description: "mapped to row_num" tags: - identifier type: bigint - name: device_id type: text - name: org_id type: keyword - name: device_name type: text - name: serial_number type: bigint - name: model_type type: text - name: family type: text - name: category type: keyword - name: model_name type: text - name: platform type: keyword - name: manufacturer type: text - name: subscription_id type: text - name: created_at type: timestamp - name: updated_at type: timestamp - name: is_active type: bool - name: _delete type: bool indexers: - index_table: devices_before_110125 base_sql: | SELECT row_num, row_num as id, device_id, org_id, device_name, serial_number, model_type, family, category, model_name, platform, platform as platform_vec, manufacturer, subscription_id, cast(created_at as timestamp) as created_at, cast(updated_at as timestamp) as updated_at, is_active, _delete FROM devices options: start: 1608681600 step: 86400 batch_sql: | WITH base AS ( {base_sql} ) SELECT * FROM base WHERE epoch(updated_at) >= {start} AND epoch(updated_at) < {end} throttle: min: 10000 max: 60000 factor: 1.2 jitter: true - index_table: devices_after_110125 base_sql: | SELECT row_num, row_num as id, device_id, org_id, device_name, serial_number, model_type, family, category, model_name, platform, platform as platform_vec, manufacturer, subscription_id, cast(created_at as timestamp) as created_at, cast(updated_at as timestamp) as updated_at, is_active, _delete FROM devices options: start: 1736640000 step: 86400 batch_sql: | WITH base AS ( {base_sql} ) SELECT * FROM base WHERE epoch(updated_at) >= {start} AND epoch(updated_at) < {end} throttle: min: 10000 max: 60000 factor: 1.2 jitter: trueTo know more about each attribute in detail, please refer to this link.
-
Apply the manifest file by executing the below command.
-
Validate the Service by executing the below command.
Expected output:
dataos-ctl resource get -t service -n testingls -w public INFO[0000] 🔍 get... INFO[0000] 🔍 get...complete NAME | VERSION | TYPE | WORKSPACE | STATUS | RUNTIME | OWNER ------------|---------|---------|-----------|--------|-----------|-------------- testingls | v1 | service | public | active | running:1 | iamgroot -
If the Lakesearch Service’s runtime status appears pending for a long time then check the Service logs for any possible errors by executing the below command.
Expected output
dataos-ctl log -t service -n testingls -w public -r INFO[0000] 📃 log(public)... INFO[0002] 📃 log(public)...complete NODE NAME │ CONTAINER NAME │ ERROR ────────────────────────────────────┼────────────────────────┼──────── testingls-96b2-d-597d7c9f4c-r87b2 │ testingls-96b2-indexer │ -------------------LOGS------------------- 8:42AM DBG pkg/searchd/raw_sql_query.go:29 > [8.152977ms] << SHOW TABLE city STATUS; took=8.152977 8:42AM DBG pkg/routes/accesslog.go:18 > /lakesearch/public:testingls/metrics code=200 method=GET took=1037855 8:42AM DBG pkg/searchd/raw_sql_query.go:29 > [8.106225ms] << SHOW TABLE city STATUS; took=8.106225 8:42AM DBG pkg/routes/accesslog.go:18 > /lakesearch/public:testingls/metrics code=200 method=GET took=1111317 8:42AM DBG pkg/searchd/raw_sql_query.go:29 > [8.425655ms] << SHOW TABLE city STATUS; took=8.425655 8:42AM DBG pkg/routes/accesslog.go:18 > /lakesearch/public:testingls/metrics code=200 method=GET took=1408504 8:42AM DBG pkg/searchd/raw_sql_query.go:29 > [8.535937ms] << SHOW TABLE city STATUS; took=8.535937 8:43AM DBG pkg/routes/accesslog.go:18 > /lakesearch/public:testingls/metrics code=200 method=GET took=1104167 8:43AM DBG pkg/searchd/raw_sql_query.go:29 > [8.172188ms] << SHOW TABLE city STATUS; took=8.172188 8:43AM DBG pkg/routes/accesslog.go:18 > /lakesearch/public:testingls/metrics code=200 method=GET took=1053376 8:43AM DBG pkg/searchd/raw_sql_query.go:29 > [8.043104ms] << SHOW TABLE city STATUS; took=8.043104 8:43AM INF pkg/searchd/indexer.go:90 > 56/ Start --->> city Indexer=city 8:43AM DBG pkg/searchd/raw_sql_query.go:29 > [973.294µs] << SELECT `start`, `end` FROM `__indexer_state` WHERE `indexname` = 'city' took=0.973294 8:43AM INF pkg/searchd/indexer.go:155 > {start}:1736448351, {end}:1839177951 8:43AM DBG pkg/searchd/raw_sql_query.go:29 > [587.614µs] << DESC city took=0.587614 8:43AM DBG pkg/source/connection.go:119 > [526.949321ms] << WITH base AS ( SELECT city_id, zip_code, zip_code as id, city_name, county_name, state_code, state_name, version, cast(ts_city as timestamp) as ts_city FROM city ) SELECT * FROM base WHERE epoch(ts_city) >= 1736448351 AND epoch(ts_city) < 1839177951 Source=datasets took=526.949321 8:43AM DBG pkg/searchd/bulk_insert.go:70 > BulkInsert <<-- [500] {"items":[],"current_line":1,"skipped_lines":1,"errors":true,"error":""} 8:43AM DBG pkg/searchd/bulk_insert.go:81 > BulkInsert performed of empty payload 8:43AM DBG pkg/searchd/bulk_insert.go:37 > BulkInsert took [751.708µs] took=0.751708 8:43AM DBG pkg/searchd/raw_sql_query.go:29 > [810.819µs] << REPLACE INTO `__indexer_state` VALUES (18003902094994090146, 'city', 1736448351, 1839264351) took=0.810819 8:43AM INF pkg/searchd/indexer.go:127 > 56/ city <<--- Done #created=0 #deleted=0 #rows=0 Indexer=city 8:43AM INF pkg/searchd/indexer.go:141 > Sleeping... Indexer=city duration=60000
For a detailed breakdown of the configuration options and attributes of a Lakesearch Service, please refer to the documentation: Attributes of Lakesearch Service manifest
Indexing with Query Rewriter¶
In the below example rewriter is applied to indexed datasets (e.g., devices_with_d), ensuring that every search query can be modified before execution.
index_tables:
- name: devices
description: "Index for devices"
tags:
- devices
properties:
morphology: stem_en
partitions:
- devices_before_110125
- devices_after_110125
columns:
- name: row_num
type: bigint
- name: id
description: "Mapped to row_num"
tags:
- identifier
type: bigint
- name: device_id
type: text
- name: org_id
type: keyword
- name: device_name
type: text
- name: serial_number
type: bigint
- name: model_type
type: text
- name: platform
type: keyword
- name: manufacturer
type: text
- name: created_at
type: timestamp
- name: updated_at
type: timestamp
This ensures that every query execution applies the filtering logic defined in the ImplementQueryRewriter class.
Query Rewriter execution details¶
Class definition and method¶
This section describes the logic behind the query rewriter workings.
class ImplementQueryRewriter(QueryRewriterConfig):- Here, we are defining a new class called
ImplementQueryRewriterthat inherits fromQueryRewriterConfig. - This means that the class must implement any abstract or required methods defined in
QueryRewriterConfig, ensuring it conforms to the expected interface.
- Here, we are defining a new class called
-
def rewrite_query(self, token: str, user: dict, index: str, query: dict) -> dict:- This method is the core of the custom query rewrite.
-
The method is expected to return a dictionary that represents the updated query after rewriting.
-
It takes the following parameters:
Parameter Description Format Example token: strLikely used for authentication or session tracking purposes. <api_token>YXBpa2V5LjkyZDY1MzQ0LTNitNDdhYS1iMzLTM1NmU4M2E1M2NiNg=user: dictA dictionary containing user information, such as roles or tags json {"id": "userId","tags": ["<list of tags>"]}json {"tags": ["roles:id:data-dev", "roles:id:operator", "roles:id:system-dev", "roles:id:user", "users:id:iamgroot"], "id": "iamgroot"}index: strThe index (or collection) name that the query is targeting. <index_name>devicesquery: dictThis is the original query (the search query payload requested by the user) in dictionary format. json {"<request_payload>"}json {"query": {"match": {"device_name": "agreement"}}}
Registering the Custom Query Rewriter¶
Registrar.setQueryRewriter(ImplementQueryRewriter())
- This line of code registers your custom query rewriter with the search system. In other words, this is where you're plugging your custom logic into the framework so that all subsequent query rewrites follow the behavior defined in your implementation.
-
Working:
-
Instantiation:
ImplementQueryRewriter()creates an instance of your custom query rewriter class. -
Registration:
Registrar.setQueryRewriter(...)is a method call that tells the system to use the provided instance as the active query rewriter.
-
-
Once registered, whenever a query needs to be rewritten (for example, to apply custom filters or adjustments), the system will invoke the
rewrite_querymethod defined inImplementQueryRewriter.
Examples¶
Simple Filter¶
The code modifies the query to only fetch documents where devices are running on Windows platform.
Python
from py.lakesearch.query_rewriter_config import QueryRewriterConfig
from py.lakesearch.registrar import Registrar
class ImplementQueryRewriter(QueryRewriterConfig):
def rewrite_query(self, token: str, user: dict, index: str, query: dict) -> dict:
# Extract the existing match clause from the incoming query directly
match_clause = query["query"]["match"]
# Wrap the result in a dictionary if found
final_result = {"match": match_clause} if match_clause else None
# Create the new filter
filter_clause = {
"equals": {"platform": "Windows"} # The value you want to filter by
}
# Build the final query structure
if match_clause:
updated_query = {
"query": {
"bool": {
"must": [
filter_clause, # Add the filter clause
final_result, # Add the original match clause
]
}
}
}
else:
# If there's no match clause, just return the filter (or handle as needed)
updated_query = {"query": {"bool": {"must": [filter_clause]}}}
return {"query": updated_query}
# Register the custom query rewriter
Registrar.setQueryRewriter(ImplementQueryRewriter())
User-specific filters¶
The code checks whether the user has the "operator" tag.
-
If the user have the tag, the query is updated to only fetch documents where the device is running on the Windows platform.
-
If the user does not have the "operator" tag, the query is updated to fetch documents where the device is running on the Android platform.
Python
import logging
from google.protobuf.json_format import MessageToJson
from py.lakesearch.query_rewriter_config import QueryRewriterConfig
from py.lakesearch.registrar import Registrar
class ImplementQueryRewriter(QueryRewriterConfig):
def rewrite_query(self, token: str, user: dict, index: str, query: dict) -> dict:
# Print the contents of the user dictionary
logging.info(f"Token: {token}")
logging.info(f"User dictionary contents: {MessageToJson(user)}")
logging.info(f"Index: {index}")
logging.info(f"Query: {MessageToJson(query)}")
# Check if "roles:id:operator" tag exists in the user dictionary
tags = user["tags"]
operator_tag_present = any(tag == "roles:id:operator" for tag in tags)
# Determine the platform based on the tag
platform = "Windows" if operator_tag_present else "Android"
# Extract the existing match clause from the incoming query directly
match_clause = query["query"]["match"]
# Wrap the result in a dictionary if found
final_result = {"match": match_clause} if match_clause else None
# Create the new filter based on the platform
filter_clause = {
"equals": {
"platform": platform # Use the determined platform
}
}
# Build the final query structure
if match_clause:
updated_query = {
"query": {
"bool": {
"must": [
filter_clause, # Add the filter clause
final_result # Add the original match clause
]
}
}
}
else:
# If there's no match clause, just return the filter (or handle as needed)
updated_query = {
"query": {
"bool": {
"must": [
filter_clause
]
}
}
}
return {"query": updated_query}
# Register the custom query rewriter
Registrar.setQueryRewriter(ImplementQueryRewriter())
To get to know more about search types, filters, aggregations, and expressions, please refer to this link.