Lakesearch Stack¶
Lakesearch is a Stack within DataOS that provides the scalable full-text search solution for the DataOS Lakehouse. It allows app developers to enable full-text search on top of DataOS Lakehouse tables with an ability to scale the indexing and searching capabilities to meet business requirements.
The examples below illustrate the search functionality of Lakesearch where a user can access the API endpoint.
Scenario:
A travel application integrates Lakesearch to enhance its location-based services. Users can search for cities, states, or ZIP codes to find relevant information, such as weather, attractions, or available accommodations. Below is how Lakesearch works in this scenario.
-
Users can search for cities, states, or ZIP codes. When a user starts typing "Alab" in the search bar, the system suggests "Alabama" as a keyword, improving the search experience through autocomplete functionality.
Search with auto-suggest
Endpoint:https://unique-haddock.dataos.app/lakesearch/public:testingls/api/v2/index/city/words?word=alab*&limit=3 -
In cases where a user mistypes a search term, Lakesearch suggests similar words to help refine the query. For example, if the user types "auta" instead of "Autauga," the system provides suggestions like "Utah," "South," and "Dakota," ensuring accurate search results even with minor spelling errors.
Search by similar word
Endpoint:
https://unique-haddock.dataos.app/lakesearch/public:testingls/api/v2/index/city/suggestions?word=auta
Features of Lakesearch¶
Following are the features of Lakesearch:
-
Full-text search: Build a fast, relevant full-text search solution using inverted indexes, tokenization, and text analysis.
-
Semantic search: Understand the intent and contextual meaning behind search queries.
-
Build search experiences: Add search capabilities to apps or websites, or build enterprise search engines over your organization’s internal data sources.
Lakesearch Architecture¶
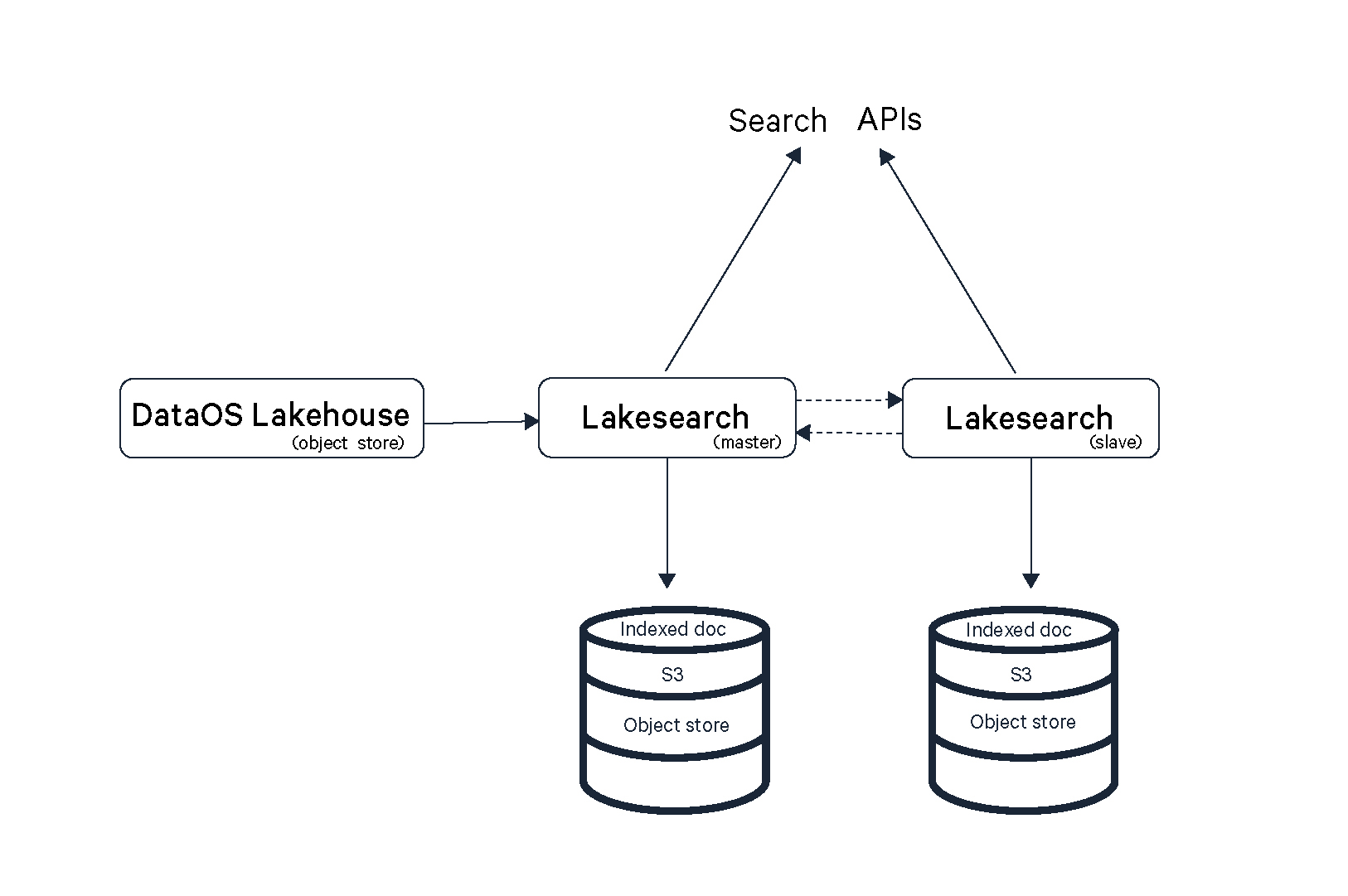
Lakesearch follows a Master-Slave architecture, a design pattern commonly used for scalability, load balancing, and high availability.
Master node¶
The Master node is responsible for indexing data, processing queries, and managing search operations. It extracts and processes raw data from the DataOS Lakehouse, converting it into an indexed format for efficient searching. When a search request is received, the Master node processes it and distributes the workload to Slave nodes if needed. Additionally, it manages the overall cluster by synchronizing indexed data across Slave nodes, ensuring consistency. The Master node also plays a key role in storage, saving indexed documents in an object store for quick and reliable retrieval.
Slave node¶
The Slave node supports the Master node by handling search queries, ensuring smooth performance through load balancing. In case of a failure in the Master node, the Slave node can take over search operations, acting as a failover mechanism to maintain system availability. By distributing query loads and ensuring data redundancy, the Slave node enhances the overall reliability and scalability of the system.
Object store¶
Indexed Document Storage (Object store - e.g. S3) stores indexed data, ensuring quick and efficient retrieval. It provides persistence, meaning the data remains intact even if nodes restart or fail. By leveraging an object store (e.g. S3), the system guarantees durability and scalability, enabling seamless access to indexed documents whenever needed.
Lakesearch query processing flow¶
The query processing in Lakesearch follows a structured workflow, ensuring optimal query execution based on query type and available resources.
Query execution steps¶
-
User submits a query: A search query is sent to the Lakesearch API (/search).
-
Query rewriter check: If a query rewriter is available, the query is rewritten and optimized. Otherwise, the original query is used.
-
Document retrieval: The query is executed against the indexed data in the Lakehouse.
-
Response handling: If an error occurs (e.g., authentication, syntax, timeout), an error response is returned. Otherwise, relevant documents are fetched and returned to the user. This structured approach ensures that search operations are optimized for speed and relevance.
Lakesearch index creation flow¶
Index creation in Lakesearch follows a batch-processing model, where indexing occurs in a loop until all batches are processed.
Indexing process¶
-
Defining index configuration: Users define index mappings in a YAML file, specifying the indexing logic. These mappings determine how data records are structured and stored. The configuration is deployed via the CLI.
-
Batch processing: The Lakesearch Service allocates resources and initiates the indexing process. The indexer retrieves data records in batches, processes them into documents, and stores them in object storage (Persistent Volume Claim) in the form of inverted indices.
-
Document storage & updates: Once processed, the indexed documents are stored in object storage (PVC). The system tracks progress throughout the indexing process to ensure consistency and completeness.
-
Completion: The indexing process continues until all available data records have been processed. Once no new data records are detected, the process completes, ensuring that the indexed data is fully available for search operations.
This architecture provides a scalable and cost-effective alternative to traditional full-text search implementations, making it well-suited for enterprise data lake environments.
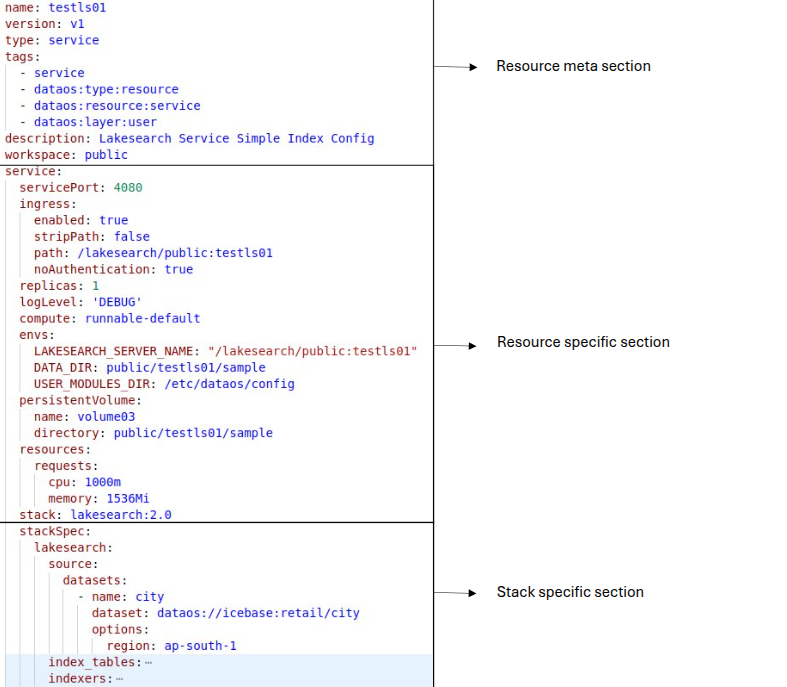
Structure of Lakesearch Service manifest file¶
How to set up a Lakesearch Service?¶
Once the Lakesearch Stack is available, follow the steps given in the links below to create a Lakesearch Service . The Lakesearch Service retrieves data from the source and indexes each column from one or multiple tables, making it searchable.
For a detailed breakdown of the configuration options and attributes of a Lakesearch Service, please refer to the documentation: Attributes of Lakesearch Service manifest.
How to perform index-based searches?¶
A user can start searching for the index, keywords, or similar words by accessing the Lakesearch Service API endpoint. Some basic index searching is given below, to know in detail about index searching, please refer to this link.
Searching for an index¶
A user can access the endpoint either by curl command or using any API platform.
-
To get the list of all the indices, a user can execute the following curl command in the terminal.
-
To get the details of an individual index by name execute the below curl command.
curl -X GET "https://unique-haddock.dataos.app/lakesearch/public:testingls/api/v2/index/city/search" \ -H "Authorization: Bearer dG9rZW5fZGlzdGluY3Rhklf9tYWlubHlfdXBfklF5LjU1ZmE1ZWQyLWUwNDgtNGI3Yi1hNGQ2LWNlNjA1YTAzZTE4YQ=="Expected output:
{ "took": 0, "timed_out": false, "hits": { "total": 1, "total_relation": "gte", "hits": [ { "_id": 36003, "_score": 1, "_source": { "state_name": "Alabama", "version": "202501090702", "@timestamp": 1739964871, "city_id": "CITY6", "zip_code": 36003, "city_name": "Autaugaville", "county_name": "Autauga County", "state_code": "AL", "ts_city": 1736406148 } } ] } }
Searching for a keyword¶
To search by the exact keyword execute the following curl command.
Searching for a similar word¶
To search by the similar word execute the following curl command.
Managing deleted records in Lakesearch¶
When records that have already been indexed in Lakesearch are deleted from the source table, they remain accessible through the search API unless explicitly handled. To manage this, Lakesearch supports soft deletes, ensuring that deleted records are appropriately excluded from search results.
Soft delete mechanism¶
Lakesearch relies on two additional columns in the Lakehouse table:
_delete(Boolean) – Tracks whether a record should be considered deleted. By default, all records have_delete = false.- Timestamp column (e.g.,
updated_atorlast_modified_date) – Records the last modification time.
When a record needs to be removed from search results:
- It is marked as
_delete = true. - The
updated_attimestamp is refreshed to reflect the change.
This ensures that Lakesearch recognizes the update and removes the record from indexed search results.
Handling hard deletes¶
If a record is permanently deleted from the source table, a mechanism must be in place to update _delete = true in the corresponding Lakehouse table record. If this update is not performed, Lakesearch remains unaware of the deletion, and the record will still be retrievable via the search API.
By implementing this process, Lakesearch ensures data consistency while allowing controlled deletion without losing historical traceability.
Best practices¶
This section involves recommends dos and don’ts while configuring a Lakesearch Service.
-
For large datasets, always use the partition indexer when configuring the Lakesearch Service. It divides the indexes into two parts, significantly reducing the time required to index all tables.
-
The persistent volume size should be at least 2.5 times the total dataset size, rounded to the nearest multiple of 10. To check the dataset size, use the following query:
The resultant size will be in the bytes.
Trobleshooting¶
In case of any issues while using Lakesearch, refer to the troubleshooting section for common errors, solutions, and debugging steps. This section covers potential failures related to indexing, query processing, and node synchronization, along with recommended fixes to ensure smooth operation.
FAQs¶
This section contains the answers to common questions about Lakesearch.
What is the difference between indexing in relational databases and indexing in full-text search solutions?
Indexing in Relational Databases (RDBMS) and Full-Text Search Solutions serve different purposes and work differently. Here's a comparison:| Feature | Relational Database Indexing | Full-Text Search Indexing |
|---|---|---|
| Purpose | Speeds up exact-match lookups and range queries in structured data. | Enables fast, efficient searching in large volumes of unstructured text data. |
| Data Type | Works best for structured, tabular data (numbers, dates, strings). | Optimized for text-based data with complex search requirements. |
| Index Structure | Uses B-Trees, Hash Indexes, or Bitmap Indexes. | Uses Inverted Index, where words are mapped to their locations in documents. |
| Query Type | Supports exact matches (=, LIKE 'abc%', BETWEEN). |
Supports full-text searches (MATCH() AGAINST(), tokenization, stemming). |
| Sorting & Ranking | Typically retrieves results in the order of insertion or by indexed columns. | Returns ranked results based on relevance scoring (e.g., TF-IDF, BM25). |
| Updates & Performance | Index updates are costly but required for integrity constraints. | Updates are optimized for incremental changes but can be computationally expensive. |
| Use Case | Searching for exact records, foreign key lookups, and range queries. | Searching for words, phrases, synonyms, and fuzzy matches in large text corpora. |
Example:
- RDBMS Indexing: A database indexing a
customer_idfor fast lookup in a table. - Full-Text Search Indexing: A search engine indexing millions of articles to find relevant ones based on a keyword search.