Column tagging¶
Flare provides a feature to tag columns in an output table, allowing users to have better control and governance over specific columns when writing datasets. This functionality is facilitated by the columnTags property, which is part of the outputs section in the Flare Workflow YAML configuration.
Three mutually exclusive ways have been defined to identify a column, which includes specifying either columnRegex, columnName, or columnNames within the columnTags property.
Different ways to identify the column¶
The following section provides a comprehensive overview of these three ways:
columnRegex¶
The columnRegex property allows the specification of a regular expression pattern to identify columns that require tagging. The pattern will initiate matching from the beginning of the string.
columnName¶
The columnName property is utilized to designate a particular column.
columnTags:
- columnName: "zip_code"
tags:
- PII.Gender
- PHI.DateOfBirth
- columnName: "state_name"
tags:
- PII.Sensitive
- PII.Name
- PII.Name
columnNames¶
The columnNames property is utilized when identical tags need to be applied to columns that match the specified name.
columnTags:
- columnNames: # Column Name
- "state_code"
- "zip_code"
- "county_name"
- "state_name"
- "city_id"
- "city_name"
- "version"
tags: # Tags
- PII.None
Important considerations¶
- Tags are case-sensitive. This implies that
PIIis not interchangeable withpiI,pii, orPii. So, consistency in the usage of tag names should be maintained between the Metis GUI and YAML. - If the intention is to attach a tag to a column that is already present on Metis, the correct tag, FQN (Fully Qualified Name), must be used. The FQN is constructed using the format
TagCategory.PrimaryTagName. - In the event of applying the incorrect tag to a dataset (through YAML), the following steps should be followed for the tag removal:
- Use the Metis GUI to manually remove the erroneous tag from the corresponding column. However, this step alone is not enough, as the tag may reappear in subsequent workflow runs.
- Subsequently, delete and rerun the workflow by excluding the undesired tag name. It is crucial to ensure that the workflow and DAG names match.
Code snippet¶
The code snippet to define column identifiers and tags is provided below:
version: v1 # Version
name: columnlevel-tag-workflow # Name of the Workflow
type: workflow # Type of Resource (Here its workflow)
title: Column Level Tagging # Title
description: | # Description
The purpose of this workflow is to provide tags at the column level using Flare.
workflow: # Workflow Section
dag: # Directed Acyclic Graph (DAG)
- name: columnlevel-tag-job # Name of the Job
title: Column Level Tagging Job # Title of the Job
description: | # Description
The purpose of this job is to tag columns at column level.
spec: # Specifications
stack: flare:7.0 # Stack Version
compute: runnable-default # Compute
stackSpec: # Flare Section
job: # Job Section
explain: true # Explain
logLevel: INFO # Loglevel
showPreviewLines: 2 # Show Preview Lines
inputs: # Inputs Section
- name: a_city_csv # Input Dataset Name
dataset: dataos://thirdparty01:none/city # UDL of the Dataset
format: csv # Input Dataset Format
schemaPath: dataos://thirdparty01:none/schemas/avsc/city.avsc # Schema Path
outputs: # Outputs Section
- name: finalDf # Output Dataset Name
dataset: dataos://lakehouse:publiccollection/customer_406?acl=rw # Output Dataset UDL
options: # Options
iceberg: # Iceberg Specific Properties Section
partitionSpec:
- column: version
type: identity
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
sort: # Sort
columns:
- name: version
order: desc
mode: partition
format: iceberg # Format of Output Dataset
# tags: # Tags (commented out)
# - Tier.System
# - Tier.Bronze
# - PII.DateOfBirth
# - XYZ.Dataset
# - Rubber
# - Pencil
title: Column tags
description: Column tags
columnTags: # Column Tag Property
- columnRegex: "city_*" # Column Regular Expression to specify columns to be tagged.
tags: # Tags to be designated
- PII.Sensitive
- PII.Email
- Tier.Bronze
- customer
- columnName: "zip_code" # Name of the column to be tagged
tags: # Tags to be applied to the column
- PII.Gender
- PHI.DateOfBirth
- columnName: "state_name" # Name of the column to be tagged
tags: # Tags to be applied to the column
- PII.Sensitive
- PII.Name
- PII.Name
- columnNames: # Name of the columns to be tagged (multiple)
- "state_name"
- "version"
- "zip_code"
- "zip_code"
tags: # Tags to be applied to the column
- PII.Name
- Tier.Bronze
- Rubber
- Pencil
- PII.*
steps: # Steps Section
- sequence: # Sequence Section
- name: finalDf # Name of the transformation step
sql: SELECT *, date_format(now(), 'yyyyMMddHHmm') AS version FROM a_city_csv LIMIT 10 # sql
functions: # Flare Function
- name: drop
columns:
- "__metadata_dataos_run_mapper_id"
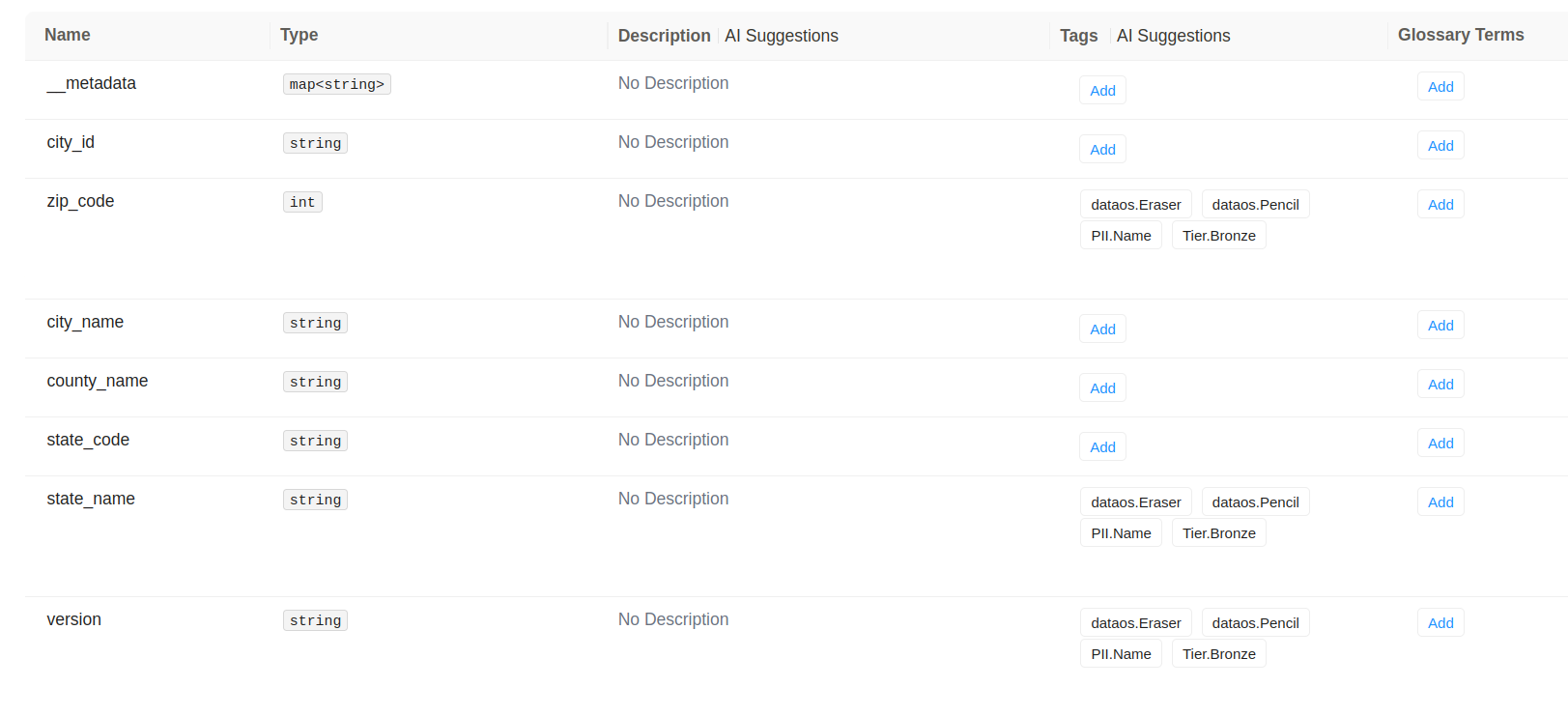
The above code snippet will apply the tags to the specified columns of the dataset. To verify that the correct tags have been applied, navigate to Metis. In Metis, go to Assets, go to Table choose customer_406 dataset. You will be able to see that the tags have been successfully applied, as shown in the image below.