Bucketing¶
Bucketing is an optimization technique that helps to prevent the shuffling and sorting of data during compute-heavy operations such as joins. Based on the bucketing columns we specify, data is collected in a number of bins.
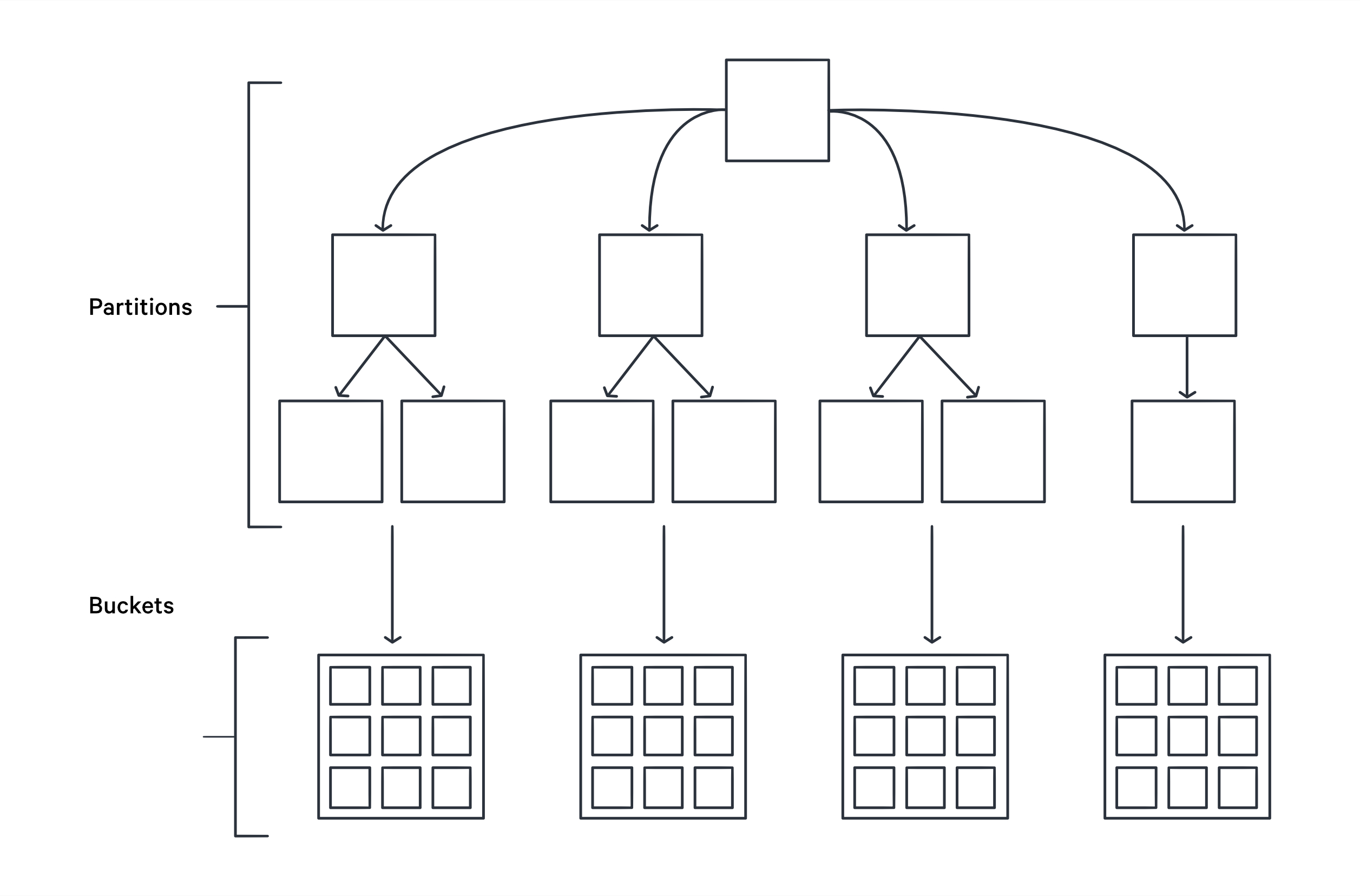
Bucketing vs Partitioning¶
Bucketing is similar to partitioning, but in the case of partitioning, we create directories for each partition. In bucketing, we create equal-sized buckets, and data is distributed across these buckets by a hash on the value of the bucket.
When to use bucketing?¶
Bucketing is helpful in the following scenarios:
- When joins are performed between dimension tables that contain primary keys for joining.
- When join operations are being performed between small and large tables.
- Where the data is heavily skewed, or for executing faster joins on a cluster we can also use the bucketing technique to improve performance.
Configurations¶
partitionSpec:
- type: bucket # select type bucket
column: week_year_column # bucketing column
numBuckets: 2 # number of buckets
Code Snippets¶
Simple Bucketing¶
Flare Workflow
version: v1
name: wf-sample-01
type: workflow
workspace: curriculum
workflow:
dag:
- name: sample
spec:
stack: flare:7.0
compute: runnable-default
stackSpec:
driver:
coreLimit: 12000m
cores: 2
memory: 12000m
executor:
coreLimit: 12000m
cores: 4
instances: 3
memory: 22000m
job:
inputs:
- name: input
dataset: dataos://thirdparty01:onboarding/customer.csv
format: csv
logLevel: INFO
outputs:
- name: select_all_columns
dataset: dataos://lakehouse:sample/customer_bucket_data?acl=rw
format: Iceberg
description: unpivotdata
options:
saveMode: overwrite
sort:
mode: global
columns:
- name: customer_id
order: desc
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
# Bucketing
partitionSpec:
- type: bucket # bucket
column: country # bucketing column
numBuckets: 4 # number of buckets
title: unpivot data
steps:
- sequence:
- name: select_all_columns
sql: Select * from input
sparkConf:
- spark.sql.extensions: org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
To verify the changes run the following query in the workbench this will give you the number of buckets, check with input and output data so the input data will only have 1 partition with:
Expected Output
| content | integer | ⋮ | file_path | varchar | ⋮ | file_format | varchar | ⋮ | spec_id | integer | ⋮ | record_count | bigint | ⋮ | file_size_in_bytes | bigint | ⋮ | column_sizes |
|---------------------------------------------------------------------------------------------------------------------|---------|-----|-----------------------------------------------------------------------------------------------------------------|---------|-----|-------------|---------|-----|---------|---------|-----|-----------------|--------|-----|--------------------|--------|-----|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| gs://lake001-apparentm-dev/lakehouse/retail/customer/data/00000-0-68ccd2f4-efa2-445a-96aa-960bf8ff7861-0-00001.parquet | 0 | ⋮ | PARQUET | 0 | ⋮ | 100 | 21563 | ⋮ | { "2": 206, "3": 2040, "4": 265, "5": 613, "6": 627, "7": 123, "8": 862, "9": 1267, "10": 346, "11": 219, "12": 201, "13": 193, "14": 133, "15": 959, "16": 200, "17": 209, "18": 288, "19": 98, "20": 143, "21": 154, "22": 124, "23": 183, "24": 160, "25": 168, "26": 395, "27
Expected output
You will see the output has the 2 partition [0, 1] as following:
| content | file_path | file_format | spec_id | partition | record_count | file_size_in_bytes |
|-------------|----------------------------------------------------------------------------------------------------------------------------------------|-----------------|-------------|---------------|------------------|------------------------|
| 0 | gs://lake001-apparentm-dev/lakehouse01/sample/customer_bucket_data/data/customer_id_bucket=0/00000-4-3ae81b47-62aa-45c8-8acc-2447ba767eb8-0-00002.parquet | PARQUET | 0 | [0] | 1186 | 12076 |
| 0 | gs://lake001-apparentm-dev/lakehouse01/sample/customer_bucket_data/data/customer_id_bucket=1/00000-4-3ae81b47-62aa-45c8-8acc-2447ba767eb8-0-00001.parquet | PARQUET | 0 | [1] | 1186 | 12076 |
Big Data-Nested Bucket¶
Flare Workflow
version: v1
name: wf-sample-02
type: workflow
workflow:
dag:
- name: sample
spec:
stack: flare:7.0
compute: runnable-default
stackSpec:
driver:
coreLimit: 2200m
cores: 2
memory: 2000m
executor:
coreLimit: 3300m
cores: 3
instances: 1
memory: 6000m
job:
inputs:
- name: input
dataset: dataos://lakehouse:retail/city
format: iceberg
logLevel: INFO
outputs:
- name: random_data
dataset: dataos://lakehouse:sample/bucket_large_data_02?acl=rw
format: Iceberg
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
partitionSpec:
- type: identity
column: category
- type: bucket # bucket
column: seg_id # bucketing column
numBuckets: 20 # number of buckets
- type: day
column: ts
name: day_partitioned
title: unpivot data
steps:
- sequence:
- name: random_data
sql: |
SELECT
uuid,
seg_id,
ts,
CASE WHEN cat > 0.67 THEN
'A'
WHEN cat > 0.33 THEN
'B'
ELSE
'C'
END AS category
FROM (
SELECT
explode (rand_value) uuid,
cast(random() * 100 AS int) seg_id,
add_months (CURRENT_TIMESTAMP, cast(random() * 100 AS int)) ts,
random() AS cat
FROM (
SELECT
SEQUENCE (1,
10000000) AS rand_value))
sparkConf:
- spark.sql.extensions: org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions