Bloblang Overview¶
Bloblang is an advanced mapping language designed for readability and flexibility in transforming complex input documents. It enables schema modifications and data restructuring within Bento and is intended for adoption by other tools as a general-purpose mapping language.
In this guide, Bloblang is executed using a Bento Docker image. First pull the Bento's latest image using the following command:
docker pull ghcr.io/warpstreamlabs/bento:latest
# Expected Output
latest: Pulling from warpstreamlabs/bento
Digest: sha256:2c5a0b3f88ab5e929c17423d967d6d3fab41b11f5464b8aedfd8f36f761e7bf3
Status: Image is up to date for ghcr.io/warpstreamlabs/bento:latest
ghcr.io/warpstreamlabs/bento:latest
docker run -p 4195:4195 --rm ghcr.io/warpstreamlabs/bento blobl server --no-open --host 0.0.0.0
# Expected Output
2025/03/25 13:00:40 Serving at: http://0.0.0.0:4195
http://localhost:4195.
 Placement of Bento stack within DataOS
Placement of Bento stack within DataOS
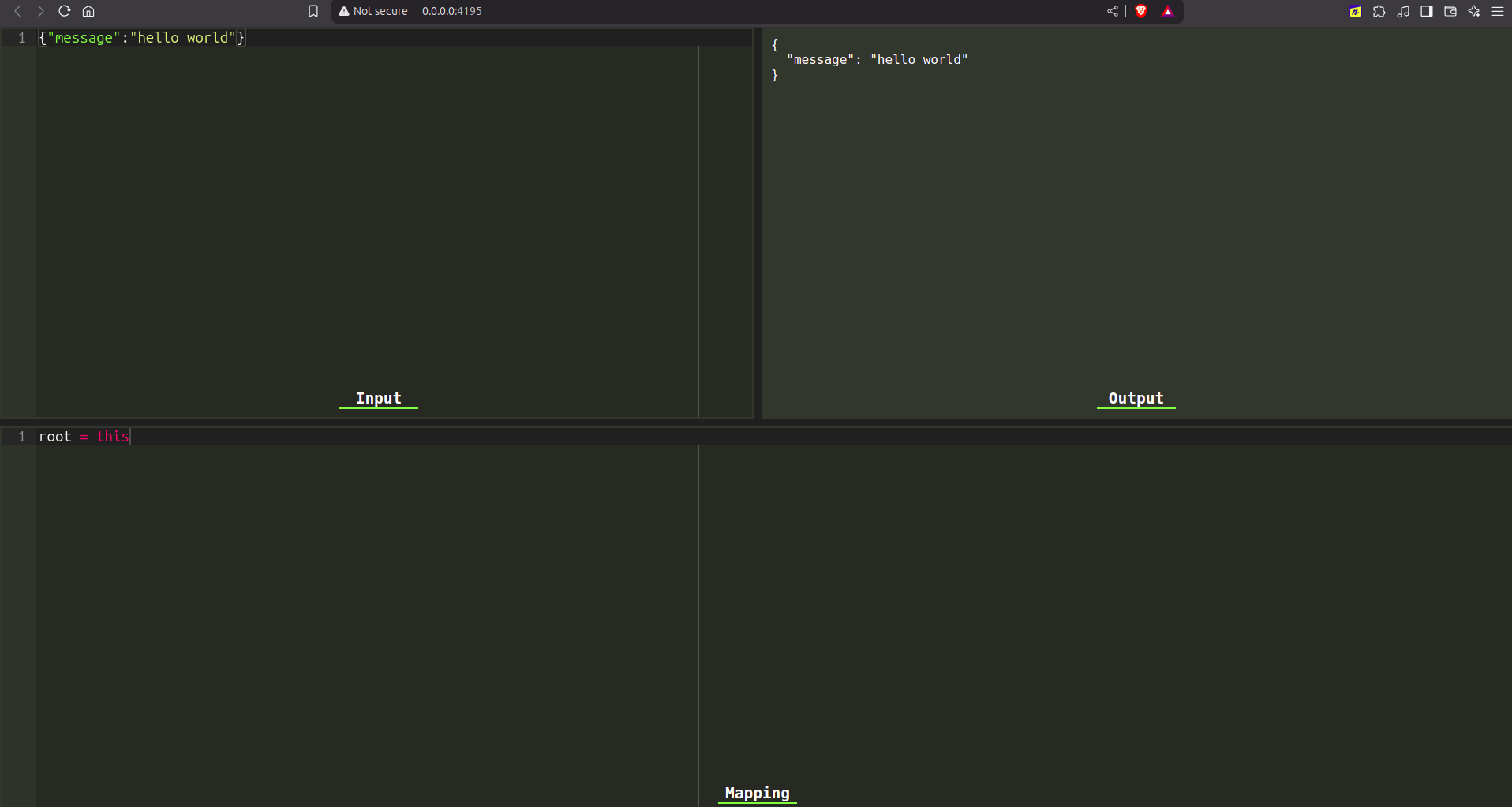
The interface consists of three panels:
- Top-left: Paste the input document.
- Bottom: Define the Bloblang mapping.
- Top-right: View the transformed output.
First assignment¶
The primary function of a Bloblang mapping is to generate a new document using an input document as a reference. This is achieved through a series of assignments. Bloblang is primarily used for mapping JSON documents, which will be the focus of this walkthrough.
Upon opening the editor, the initial mapping displayed consists of a single assignment:
In a Bloblang assignment, the left-hand side represents the assignment target, where root is a keyword referring to the root of the newly constructed document. The right-hand side contains a query that determines the assigned value, with this acting as a reference to the current context, which initially corresponds to the root of the input document.
Given an input JSON document:
This output is a formatted replica of the input document because the entire input was assigned to the root of the new document. To create a completely new document, a fresh object must be assigned to root:
Bloblang supports multiple literal types. In this mapping, the first line assigns an empty object literal to root. The second line creates a new field, foo, by assigning it the value of message from the input document.
The resulting output should appear as:
In Bloblang, if the assigned path contains fields that are unset, they are automatically created as empty objects. This rule applies to root as well, meaning the following mapping:
Will automatically create the objects required to produce the output document:
Quotes can be used to define path segments that contain symbols or whitespace. This ensures accurate field referencing within mappings.
Basic Methods and Functions¶
In Bloblang mappings, values often need to be modified during transformation. This is typically achieved using methods. The following example demonstrates how to apply a method to convert the message field from the input document to uppercase:
The syntax for applying a method follows a common pattern found in many programming languages: a dot (.) is added to the target value, followed by the method name and any required arguments within parentheses.
With this method applied, the output document looks like:
Since a Bloblang query always returns a value, methods can be applied to any query result, including the output of other methods. For example, the mapping can be extended to replace "WORLD" with "EARTH" in the message field using the replace_all method:
root.foo.bar = this.message.uppercase().replace_all("WORLD", "EARTH")
root.foo."buz me".baz = "I like mapping"
Some methods require arguments, which can be provided in nameless or named styles. Arguments are often literal values but can also be dynamic queries. The following mapping demonstrates the use of both named arguments and a dynamic argument:
root.foo.bar = this.message.uppercase().replace_all(old: "WORLD", new: this.message.capitalize())
root.foo."buz me".baz = "I like mapping"
Functions in Bloblang operate similarly to methods but do not require a target value. They are commonly used to extract external information, such as environment variables, or generate new data, such as timestamps or UUIDs.
The following example demonstrates the addition of a function to the mapping:
root.foo.bar = this.message.uppercase().replace_all("WORLD", "EARTH")
root.foo."buz me".baz = "I like mapping"
root.foo.id = uuid_v4()
The output will vary with each execution since the function generates dynamic values.
Deletions¶
In Bloblang, everything is an expression that can be assigned, including deletions. The deleted() function is used to remove fields from the output document. To demonstrate, the input document is modified as follows:
{
"name": "fooman barson",
"age": 7,
"opinions": ["trucks are cool","trains are cool","chores are bad"]
}
To create a full copy of the document while removing the name field, assign deleted() to it:
And it won't be included in the output:
Another way to remove fields is by using the without method. The previous example can be rewritten as a single assignment:
However, deleted() offers greater flexibility and will be useful in more advanced cases.
Variables¶
In Bloblang, variables allow values to be captured for later use without adding them to the resulting document. Variables are defined using the let keyword and referenced in subsequent queries with a $ prefix:
let id = uuid_v4()
root.id_sha1 = $id.hash("sha1").encode("hex")
root.id_md5 = $id.hash("md5").encode("hex")
Variables can be assigned any value type, including objects and arrays.
Unstructured and Binary Data¶
Bloblang allows assigning literal value types directly to root, such as:
When assigning a value type to root, the output is returned as a raw value, meaning strings are not quoted. This enables Bloblang to generate outputs in various formats, including encrypted, encoded, or binary data.
Unstructured mapping also applies to input handling. Instead of referencing the structured input document with this, the entire input can be treated as a binary string using the content function. Modify the mapping as follows:
After updating the mapping, enter any arbitrary text in the input panel. The output panel should display the same text but converted to uppercase.
Conditionals¶
To experiment with conditionals, update the input document to a structured format.
In Bloblang, all conditionals are expressions. This fundamental principle allows for flexible transformations, especially when working with deeply nested structures.
If Expression¶
The simplest conditional in Bloblang is the if expression, where the boolean condition does not require parentheses. The following mapping modifies the number of treats a pet receives based on a field:
Testing the mapping with pet.is_cute set to true should increase the treats count to 15. Changing pet.is_cute to false will revert treats to its original value of 5.
If a conditional expression lacks an else branch, the assignment is skipped, preserving the existing value from root = this.
To remove treats entirely when pet.is_cute is false, an else block can be added:
This is possible because field deletions are expressed as assigned values created with the deleted() function.
If Statement¶
The if keyword can also be used as a statement in order to conditionally apply a series of mapping assignments, the previous example can be rewritten as:
root = this
if this.pet.is_cute {
root.pet.treats = this.pet.treats + 10
} else {
root.pet.treats = deleted()
}
Converting this mapping to use a statement has resulted in a more verbose mapping as we had to specify root.pet.treats multiple times as an assignment target. However, using if as a statement can be beneficial when multiple assignments rely on the same logic:
root = this
if this.pet.is_cute {
root.pet.treats = this.pet.treats + 10
root.pet.toys = this.pet.toys + 10
}
Match Expression¶
Another conditional expression in Bloblang is match, which enables multiple branches. Each branch consists of a condition followed by => and the corresponding query to execute. The first matching condition determines the executed branch.
root = this
root.pet.toys = match {
this.pet.treats > 5 => this.pet.treats - 5,
this.pet.type == "cat" => 3,
this.pet.type == "dog" => this.pet.toys - 3,
this.pet.type == "horse" => this.pet.toys + 10,
_ => 0,
}
Execute the mapping with different values for pet.type and pet.treats to observe how the match expression selects the appropriate branch.
match expressions can also redefine the context for this, reducing redundant references in boolean conditions. The following mapping achieves the same logic as the previous one but with a more concise structure:
root = this
root.pet.toys = match this.pet {
this.treats > 5 => this.treats - 5,
this.type == "cat" => 3,
this.type == "dog" => this.toys - 3,
this.type == "horse" => this.toys + 10,
_ => 0,
}
Boolean conditions in a match expression can also be expressed as value types. In this case, the matched context is directly compared to the specified value.
root = this
root.pet.toys = match this.pet.type {
"cat" => 3,
"dog" => 5,
"rabbit" => 8,
"horse" => 20,
_ => 0,
}
Error Handling¶
Errors in Bloblang can occur due to variations in input data. When errors are not handled, unexpected failures may disrupt the mapping process.
To observe this behavior, update the input document as follows:
Update the mapping to a simple number comparison to observe how unhandled errors behave:
When an error occurs due to a type mismatch, Bloblang abandons the mapping and returns an error message, such as:
failed assignment (line 1): cannot compare types string (from field `this.angry_peasants`) and number (from field `this.palace_guards`)
To proceed safely despite errors, the catch method can be used. This method allows a fallback value to be specified if an error occurs. Since methods can be applied to any query, the arithmetic operation can be enclosed in brackets and catch applied to the entire expression:
Instead of returning an error, the output now includes the field in_trouble set to true. Modify the value of angry_peasants to test various inputs, including numeric values, to observe different output behaviors.
One of the powerful features of catch is that when it is added at the end of a series of expressions and methods it will capture errors at any part of the series, which allows to capture errors at any granularity. For example, the mapping:
root.abort_mission = if this.mission.type == "impossible" {
!this.user.motives.contains("must clear name")
} else {
this.mission.difficulty > 10
}.catch(false)
Will catch errors caused by:
this.mission.typenot being a stringthis.user.motivesnot being an arraythis.mission.difficultynot being a number
But will always return false if any of those errors occur. Try it out with this input and play around by breaking some of the fields:
{
"mission": {
"type": "impossible",
"difficulty": 5
},
"user": {
"motives": ["must clear name"]
}
}
Now try out this mapping:
root.abort_mission = if (this.mission.type == "impossible").catch(true) {
!this.user.motives.contains("must clear name").catch(false)
} else {
(this.mission.difficulty > 10).catch(true)
}
This version is more granular and will capture each of the errors individually, with each error given a unique true or false fallback.
Validation¶
Errors can be useful in scenarios where invalid data should be handled separately, such as routing to a dead-letter queue or filtering out bad records. Common Bento error-handling patterns for such cases are covered in the error handling guide.
Bloblang provides multiple ways to create errors for data validation. Several helper methods simplify field validation and type coercion. Try the following mapping to see them in action:
With some of these sample inputs:
{"foo":"nope","bar":"hello world","baz":[1,2,3]}
{"foo":5,"baz":[1,2,3]}
{"foo":10,"bar":"hello world","baz":[]}
However, these methods don't cover all use cases. The general purpose error throwing technique is the throw function, which takes an argument string that describes the error. When it's called it will throw a mapping error that abandons the mapping.
The type method can be used to check a field’s data type. If the type does not match the expected value, an error can be triggered. This approach ensures data integrity by validating input before processing.
root.foos = if this.user.foos.type() == "array" {
this.user.foos
} else {
throw("foos must be an array, but it ain't, what gives?")
}
Try this mapping out with a few sample inputs:
Context¶
In Bloblang, the context refers to the value returned by the this keyword. Initially, this references the root of the input document, which is why root = this produces an identical output to the input.
However, the "context" can change depending on the mapping structure. This has already been demonstrated within a match expression. Another way to modify the context is by applying a "bracketed query expression" as a method to a query, which follows this structure:
Within the bracketed query expression the context becomes the result of the query that it's a method of, so within the brackets in the above mapping the value of this points to the result of this.foo.bar, and the mapping is therefore equivalent to:
With this handy trick the throw mapping from the validation section above could be rewritten as:
root.foos = this.user.foos.(if this.type() == "array" { this } else {
throw("foos must be an array, but it ain't, what gives?")
})
Naming the Context¶
Shadowing the this keyword with new contexts can make mappings harder to read and limits access to only one context at a time. As an alternative, Bloblang supports context capture expressions, which function similarly to lambda expressions in other languages. These expressions allow assigning a name to the new context using the syntax:
This approach improves readability and flexibility in complex mappings.
Within the brackets, the newly defined field thing captures the context that would have otherwise been assigned to this. As a result, this continues to reference the root of the input document, maintaining access to the original context while allowing more explicit naming within the scoped expression.
Coalescing¶
Opening bracketed query expressions on fields enables coalescing, a technique in Bloblang used to handle structural deviations in input data. This is useful when a value may exist in multiple possible paths.
To try this, update the input document as follows:
To flatten the structure, apply the following mapping:
In cases where the contents field exists under different parent fields (article, comment, or share), a match expression could be used to check for their existence. However, a more concise approach is to use the "pipe operator (|)".
In Bloblang, the pipe operator joins multiple queries, selecting the first one that returns a non-null result. Update the mapping as follows:
Modify the input document by changing the article field to comment. The contents value should remain "Some people did some stuff" in the output document, demonstrating how the pipe operator selects the first available field.
To simplify the mapping and avoid repeating this.thing, a "bracketed query expression" can be used to change the context, allowing for a cleaner structure and easier expansion with additional fields:
Also, the keyword this within queries can be omitted and made implicit, which allows to reduce this even further:
A pipe operator can also be added at the end of the expression to provide a fallback literal value if none of the specified candidates exist. This ensures that contents always has a defined value, even when article, comment, or share are missing.
Advanced Methods¶
Bloblang provides advanced methods for manipulating structured data types, enabling operations such as mapping array elements and filtering object keys based on their values. These methods allow for efficient data transformation and handling complex mappings.
To explore these features, update the input document to the following list:
{
"num_friends": 5,
"things": [
{
"name": "yo-yo",
"quantity": 10,
"is_cool": true
},
{
"name": "dish soap",
"quantity": 50,
"is_cool": false
},
{
"name": "scooter",
"quantity": 1,
"is_cool": true
},
{
"name": "pirate hat",
"quantity": 7,
"is_cool": true
}
]
}
To filter the input document and retain only the items that are "cool" and available in sufficient quantity, the "filter method" can be used. This method evaluates each element based on a specified condition and includes only those that meet the criteria.
When the mapping is executed, the output is reduced because the filter method applies a query to each element of the array. The context shifts to the current array element during evaluation. By capturing the context into a field (e.g., thing), the root of the input remains accessible via this, allowing for more flexible referencing within the query.
The filter method requires the query parameter to resolve to a boolean true or false, and if it resolves to true the element will be present in the resulting array, otherwise it is removed.
The ability to apply a query argument across a range is a powerful feature of Bloblang. When working with complex structured data, advanced methods like filter and map_each become essential.
The map_each method enables modification of each element in an array or each value in an object. Update the input document as follows:
{
"talking_heads": [
"1:E.T. is a bad film,Pokemon corrupted an entire generation",
"2:Digimon ripped off Pokemon,Cats are boring",
"3:I'm important",
"4:Science is just made up,The Pokemon films are good,The weather is good"
]
}
The input consists of an array of strings, where each element contains an identifier, a colon separator, and a comma-separated list of opinions. To transform each string into a structured object, the map_each method can be applied with a mapping that extracts and organizes the components. Use the following mapping:
root = this.talking_heads.map_each(raw -> {
"id": raw.split(":").index(0),
"opinions": raw.split(":").index(1).split(",")
})
In the previous mapping, the map_each method applies a query where the context is the array element, captured into the field raw. The query result defines the transformed structure of each element in the output array.
To extract the identifier and opinions, the split method is used twice:
1. The first part (index(0)) retrieves the identifier.
2. The second part (index(1)) contains the opinions, which are further split by commas to create an array.
Since the colon-based split operation is performed twice, a more efficient approach uses "bracketed query expressions" to avoid redundancy and improve performance. Update the mapping as follows:
root = this.talking_heads.map_each(raw -> raw.split(":").(split_string -> {
"id": split_string.index(0),
"opinions": split_string.index(1).split(",")
}))
Reusable Mappings¶
Named mappings in Bloblang allow for reusable and modular transformations, improving readability and efficiency. These mappings are defined using the map keyword and can be invoked within other mappings.
Define a named mapping as follows:
map parse_talking_head {
let split_string = this.split(":")
root.id = $split_string.index(0)
root.opinions = $split_string.index(1).split(",")
}
root = this.talking_heads.map_each(raw -> raw.apply("parse_talking_head"))
The body of a named map, enclosed in curly brackets, functions as an isolated mapping. Within this scope, root refers to a newly created value for each invocation of the map, while this refers to the root of the provided context.
Named maps are executed using the apply method, which accepts a string parameter identifying the map to invoke. This allows for dynamic selection of the target map.
In the provided example, a custom map was used to generate structured objects without relying on object literals. Additionally, named maps support the creation of scoped variables that exist only within the map's execution context.
A key feature of named mappings is their ability to invoke themselves recursively, enabling transformations on deeply nested structures. The following example demonstrates a mapping that removes all values from a document if they contain the word "Voldemort" (case insensitive):
map remove_naughty_man {
root = match {
this.type() == "object" => this.map_each(item -> item.value.apply("remove_naughty_man")),
this.type() == "array" => this.map_each(ele -> ele.apply("remove_naughty_man")),
this.type() == "string" => if this.lowercase().contains("voldemort") { deleted() },
this.type() == "bytes" => if this.lowercase().contains("voldemort") { deleted() },
_ => this,
}
}
root = this.apply("remove_naughty_man")
Try running that mapping with the following input document:
{
"summer_party": {
"theme": "the woman in black",
"guests": [
"Emma Bunton",
"the seal I spotted in Trebarwith",
"Voldemort",
"The cast of Swiss Army Man",
"Richard"
],
"notes": {
"lisa": "I don't think voldemort eats fish",
"monty": "Seals hate dance music"
}
},
"crushes": [
"Richard is nice but he hates pokemon",
"Victoria Beckham but I think she's taken",
"Charlie but they're totally into Voldemort"
]
}
Charlie will be upset but at least it's safe.
Unit Testing¶
Mappings should be validated with unit tests to ensure their reliability. Without proper testing, mappings can become unmanageable over time.
Bento provides unit testing capabilities that can be applied to mappings. To begin, save a mapping in a file, such as naughty_man.blobl. The example from the reusable mappings section can be used as a reference:
map remove_naughty_man {
root = match {
this.type() == "object" => this.map_each(item -> item.value.apply("remove_naughty_man")),
this.type() == "array" => this.map_each(ele -> ele.apply("remove_naughty_man")),
this.type() == "string" => if this.lowercase().contains("voldemort") { deleted() },
this.type() == "bytes" => if this.lowercase().contains("voldemort") { deleted() },
_ => this,
}
}
root = this.apply("remove_naughty_man")
Next, define the unit tests in an accompanying YAML file within the same directory. Name this file naughty_man_test.yaml:
tests:
- name: test naughty man scrubber
target_mapping: './naughty_man.blobl'
environment: {}
input_batch:
- content: |
{
"summer_party": {
"theme": "the woman in black",
"guests": [
"Emma Bunton",
"the seal I spotted in Trebarwith",
"Voldemort",
"The cast of Swiss Army Man",
"Richard"
]
}
}
output_batches:
-
- json_equals: {
"summer_party": {
"theme": "the woman in black",
"guests": [
"Emma Bunton",
"the dolphin I spotted in Trebarwith",
"The cast of Swiss Army Man",
"Richard"
]
}
}
A single test has been defined, referencing the mapping file to be executed. The test includes an input message, which is a simplified version of the previously used document, and output predicates that perform a JSON comparison against the expected output.
Execute the tests using:
Alternatively, Bento will automatically discover and run all tests with:
The output should resemble the following:
Test 'naughty_man_test.yaml' failed
Failures:
--- naughty_man_test.yaml ---
test naughty man scrubber [line 2]:
batch 0 message 0: json_equals: JSON content mismatch
{
"summer_party": {
"guests": [
"Emma Bunton",
"the seal I spotted in Trebarwith" => "the dolphin I spotted in Trebarwith",
"The cast of Swiss Army Man",
"Richard"
],
"theme": "the woman in black"
}
}
The expected output in the test contains an error. Once corrected, executing the test should produce the following output:
With the test in place, any future modifications to the mapping are better protected against regressions. More details on the Bento unit test specification, including alternative output predicates, can be found in the relevant documentation.