Query as Input in Flare Data Pipeline¶
Information
In this guide, you'll learn how to use a query result as input in a Flare workflow. The Flare workflow will generate a dataset from the query output and save it to Lakehouse for further analysis or use.
Using query results as inputs in the Flare data pipeline allows you to dynamically retrieve data from a data source based on specific criteria, transform it, and then use it in downstream processes. The query will be executed by the DataOS query engine, Minerva, and the result will be used as input in a Flare workflow, which loads it into the sink system.
In this example, we’ll create an enriched dataset by aggregating data from customer, product, order, return, and territory datasets. The Flare Workflow will then load this dataset into Lakehouse for further analysis. This enriched data will help with analytics, such as understanding customer behavior and product satisfaction, and can support marketing teams in reporting and engagement.
Key Steps¶
The creation of a Depot involves the steps:

Step 1: Identify Data to be Extracted¶
For this example, we are taking data that is stored in various tables on Lakehouse.
Step 2: Write and Validate the Query to be used as Input¶
Write a query to retrieve the desired data from the existing datasets. This SQL query extracts detailed customer order information by joining multiple tables from the lakehouse.sports schema. Verify the query output to ensure it meets the requirements.
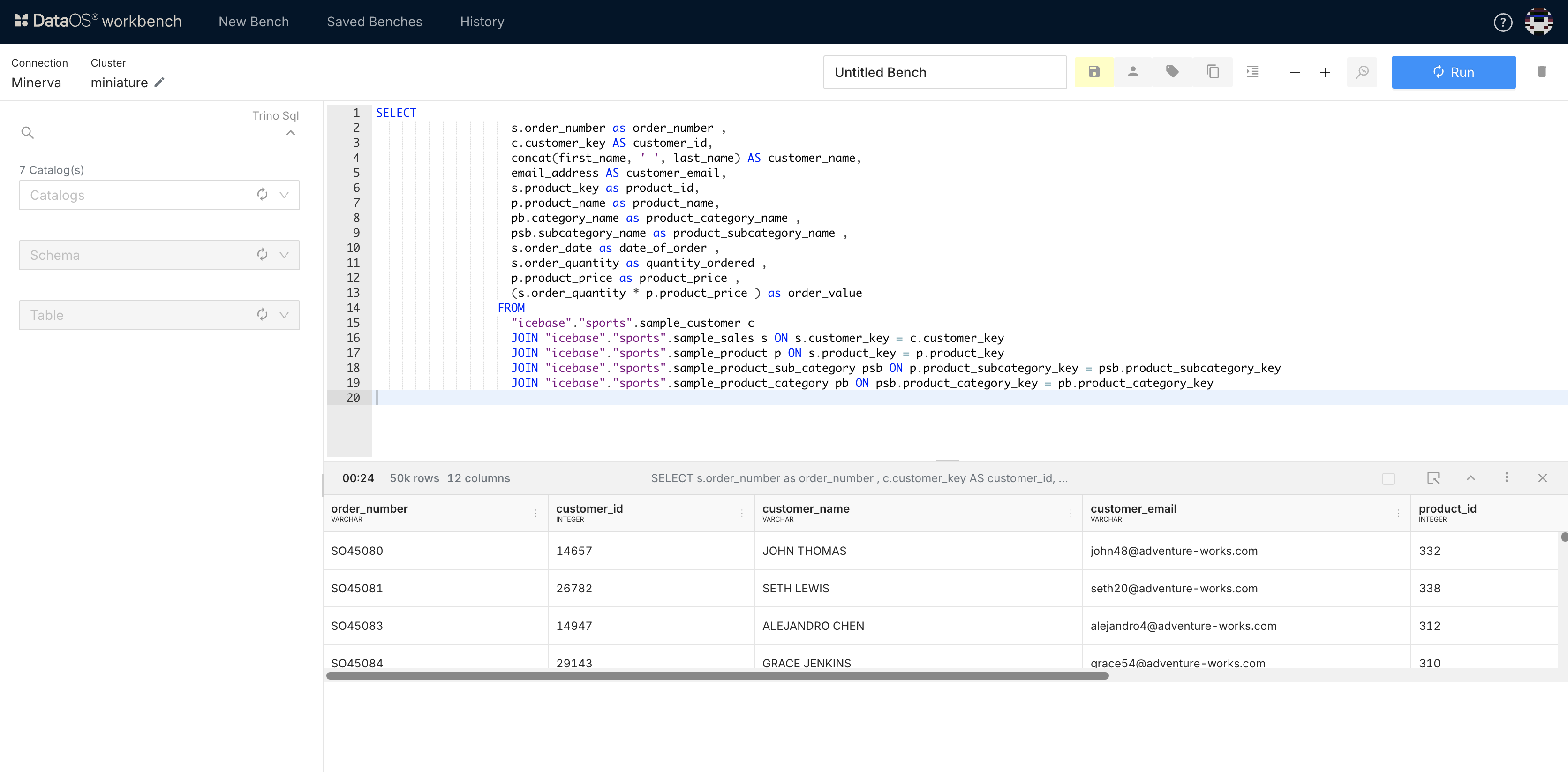
Step 3: Flare Workflow with Query as Input¶
Create a Flare workflow that takes Minerva query results as input and ingests the data in Lakehouse.
- Create a manifest YAML file.
-
In YAML configuration, define Workflow properties such as
name,version,type,owner, etc. -
In the
inputsection, provide your query.stackSpec: job: explain: true inputs: - name: data query: | SELECT s.order_number as order_number , c.customer_key AS customer_id, concat(first_name, ' ', last_name) AS customer_name, email_address AS customer_email, s.product_key as product_id, p.product_name as product_name, pb.category_name as product_category_name , psb.subcategory_name as product_subcategory_name , s.order_date as date_of_order , s.order_quantity as quantity_ordered , p.product_price as product_price , (s.order_quantity * p.product_price ) as order_value FROM "lakehouse"."sports".sample_customer c JOIN "lakehouse"."sports".sample_sales s ON s.customer_key = c.customer_key JOIN "lakehouse"."sports".sample_product p ON s.product_key = p.product_key JOIN "lakehouse"."sports".sample_product_sub_category psb ON p.product_subcategory_key = psb.product_subcategory_key JOIN "lakehouse"."sports".sample_product_category pb ON psb.product_category_key = pb.product_category_key -
The query will be executed by the Minerva query engine, so specify the
cluster,driver, and other relevant information as shown below. -
In the
outputsection, specify the dataset path where the query results should be saved. Include details about the dataset format and any compression methods to be used.outputs: - name: data title: sports data enriched table dataset: dataos://lakehouse:sports/enriched_table_test?acl=rw format: iceberg options: saveMode: overwrite iceberg: properties: write.format.default: parquet write.metadata.compression-codec: gzipHere is the complete YAML configuration for the Workflow.
```yaml version: v1 name: wfl-enriched-table type: workflow workflow: title: enriched table dag: - name: enriched-table-wfl title: sports data enriched table spec: stack: flare:7.0 compute: runnable-default stackSpec: job: explain: true inputs: - name: data query: | SELECT s.order_number as order_number , c.customer_key AS customer_id, concat(first_name, ' ', last_name) AS customer_name, email_address AS customer_email, s.product_key as product_id, p.product_name as product_name, pb.category_name as product_category_name , psb.subcategory_name as product_subcategory_name , s.order_date as date_of_order , s.order_quantity as quantity_ordered , p.product_price as product_price , (s.order_quantity * p.product_price ) as order_value FROM "lakehouse"."sports".sample_customer c JOIN "lakehouse"."sports".sample_sales s ON s.customer_key = c.customer_key JOIN "lakehouse"."sports".sample_product p ON s.product_key = p.product_key JOIN "lakehouse"."sports".sample_product_sub_category psb ON p.product_subcategory_key = psb.product_subcategory_key JOIN "lakehouse"."sports".sample_product_category pb ON psb.product_category_key = pb.product_category_key options: cluster: "system" SSL: "true" driver: "io.trino.jdbc.TrinoDriver" logLevel: INFO outputs: - name: data dataset: dataos://lakehouse:sports/enriched_table_test?acl=rw format: iceberg options: saveMode: overwrite iceberg: properties: write.format.default: parquet write.metadata.compression-codec: gzip title: sports data enriched table ```6. Save the manifest file and copy its path. Run the workflow. Upon successful completion, the data will be ingested into Lakehouse.
Step 4: Verify the Output Dataset¶
To verify the data saved in Lakehouse under the specified schema, follow the below steps:
- Open the Workbench app.
- Select the cluster specified in the YAML file.
- Select Catalog, Schema, and Table.
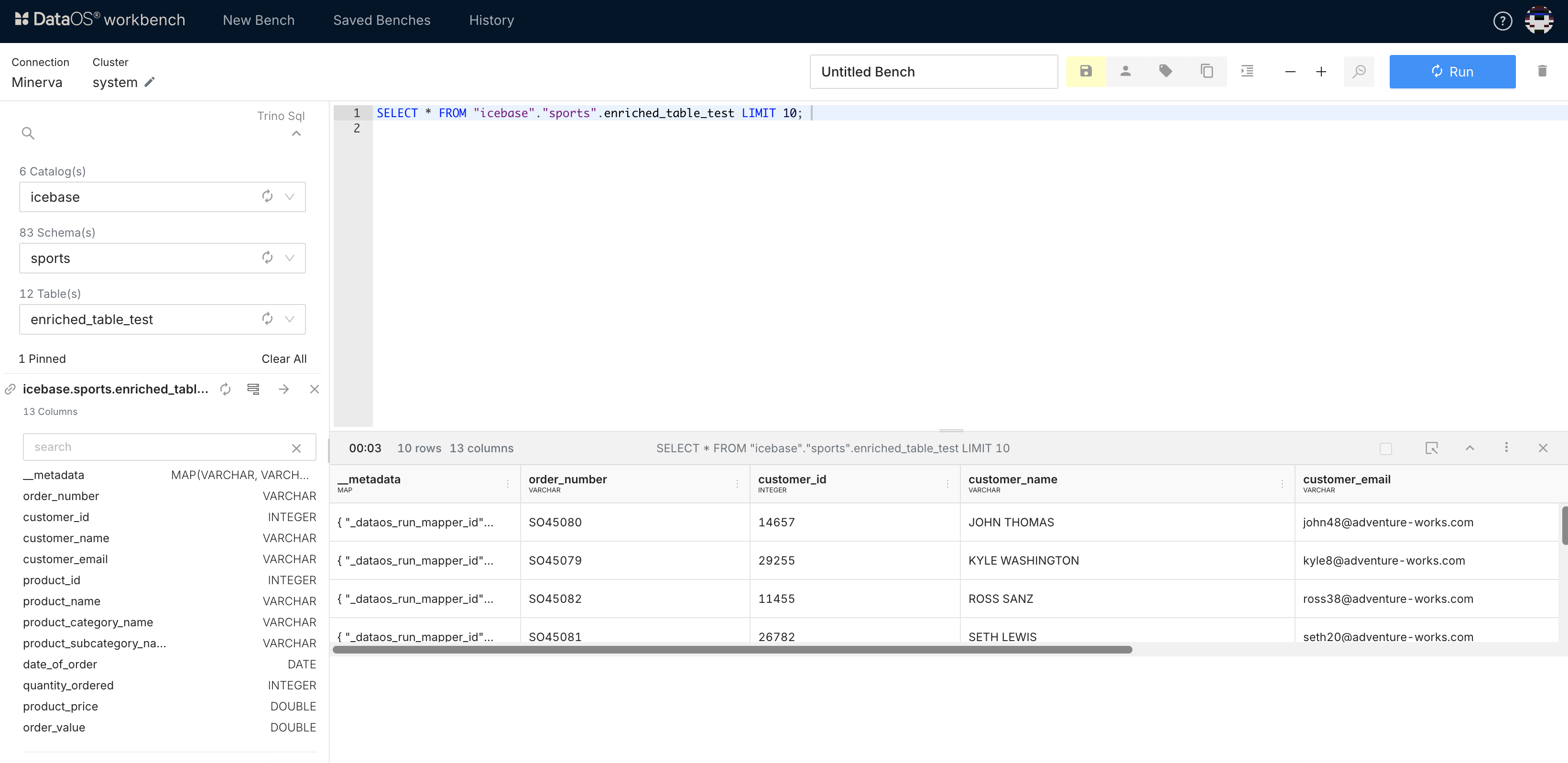
- To view the dataset, run the query in Workbench.
Query to show saved data in Lakehouse on Workbench