Ingest external files into DataOS¶
Information
You can ingest external files such as CSV, JSON, etc., into DataOS using PyFlare. In this guide, we will demonstrate this process using the example of ingesting a CSV file into the dropzone01 Depot in DataOS. The dropzone01 Depot is an object storage depot that is pre-configured and available by default with DataOS installations. For this example, we will use PyFlare to handle the file loading and saving processes, and PySpark for data transformations.
Pre-requisites¶
Make sure you have the specific permissions to write to the Depot. Such as, you require Manage All Depot use case to be able to write into the Depots.
Steps to ingest CSV files to dropzone01 Depot¶
This section involves the one-by-one steps to ingest CSV files to dropzone01 Depot.
Step 1: Open Notebook¶
a. In the DataOS interface, open the Notebook app.
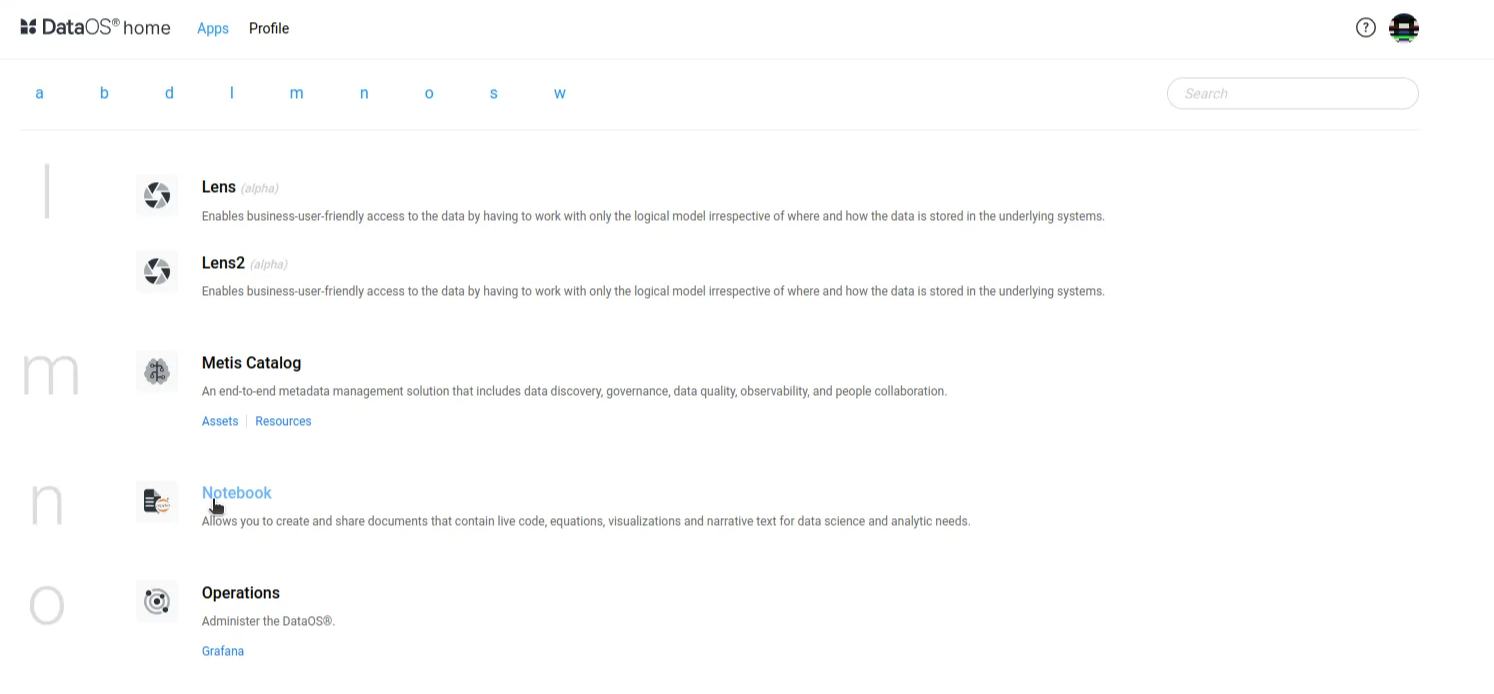
b. Open a Python 3 Notebook.

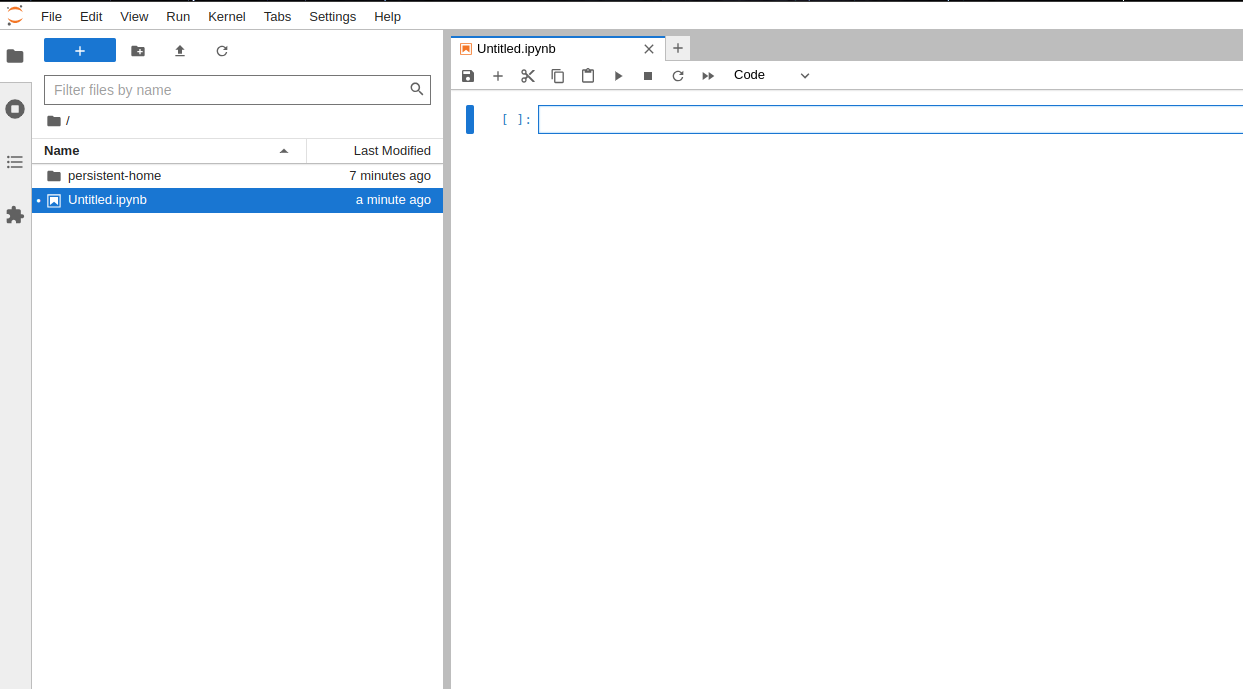
Step 2: Install the necessary Python libraries¶
Run the following code in the Notebook cell to install the required Python libraries.
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql.functions import col
from pyflare.sdk import load, save, session_builder
Step 3: Initialize the Spark session¶
In the next cell, run the following code, which defines essential configurations for initializing a Spark session, the entry point for the Spark application. These settings determine the application’s name and how it will be executed (local or distributed).
Step 4: Set up the DataOS environment¶
In the next cell, please run the following code and provide your DataOS FQDN and DataOS API key as the token to build a Spark session tailored for interacting with the DataOS platform, including accessing its Depots and enabling secure communication through the DataOS API key. It sets up the environment to process data using Spark while integrating seamlessly with the DataOS environment.
DATAOS_FQDN = "${{unique-haddock.dataos.app}}"
token = "${{Zyuio987hjsvcfTUHnmhDjjkFjFDD90rtyshKloKlsDg}}"
spark = session_builder.SparkSessionBuilder(log_level="INFO") \
.with_spark_conf(sparkConf) \
.with_user_apikey(token) \
.with_dataos_fqdn(DATAOS_FQDN) \
.with_depot("dropzone01", "rw") \
.build_session()
Expected Output
12-02 08:23 - pyflare.sdk.utils.pyflare_logger - INFO - Creating file at path: /opt/spark/conf/log4j.properties
12-02 08:23 - pyflare.sdk.utils.pyflare_logger - INFO - Data written successfully to: /opt/spark/conf/log4j.properties
12-02 08:23 - pyflare.sdk.utils.pyflare_logger - INFO - Secrets API status: 200
12-02 08:23 - pyflare.sdk.utils.pyflare_logger - INFO - Secrets API status: 200
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/spark/jars/log4j-slf4j-impl-2.17.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/spark/jars/flare-assembly-2.12.11.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Warning: Ignoring non-Spark config property: fs.s3a.committer.name
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SparkContext][Running Spark version 3.3.1]
[spark][2024 - 12 - 02 08:23:37][WARN][org.apache.hadoop.util.NativeCodeLoader][Unable to load native-hadoop library for your platform... using builtin-java classes where applicable]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.resource.ResourceUtils][==============================================================]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.resource.ResourceUtils][No custom resources configured for spark.driver.]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.resource.ResourceUtils][==============================================================]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SparkContext][Submitted application: Dataos Sdk Spark App]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.resource.ResourceProfile][Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.resource.ResourceProfile][Limiting resource is cpu]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.resource.ResourceProfileManager][Added ResourceProfile id: 0]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SecurityManager][Changing view acls to: dataos]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SecurityManager][Changing modify acls to: dataos]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SecurityManager][Changing view acls groups to: ]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SecurityManager][Changing modify acls groups to: ]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SecurityManager][SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(dataos); groups with view permissions: Set(); users with modify permissions: Set(dataos); groups with modify permissions: Set()]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.util.Utils][Successfully started service 'sparkDriver' on port 33765.]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SparkEnv][Registering MapOutputTracker]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SparkEnv][Registering BlockManagerMaster]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.storage.BlockManagerMasterEndpoint][Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.storage.BlockManagerMasterEndpoint][BlockManagerMasterEndpoint up]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SparkEnv][Registering BlockManagerMasterHeartbeat]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.storage.DiskBlockManager][Created local directory at /tmp/blockmgr-3a79ecd5-14bb-45cc-939b-94a8df05fdb2]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.storage.memory.MemoryStore][MemoryStore started with capacity 366.3 MiB]
[spark][2024 - 12 - 02 08:23:37][INFO][org.apache.spark.SparkEnv][Registering OutputCommitCoordinator]
[spark][2024 - 12 - 02 08:23:37][INFO][org.sparkproject.jetty.util.log][Logging initialized @2009ms to org.sparkproject.jetty.util.log.Slf4jLog]
[spark][2024 - 12 - 02 08:23:37][INFO][org.sparkproject.jetty.server.Server][jetty-9.4.48.v20220622; built: 2022-06-21T20:42:25.880Z; git: 6b67c5719d1f4371b33655ff2d047d24e171e49a; jvm 1.8.0_262-b19]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.Server][Started @2125ms]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.AbstractConnector][Started ServerConnector@29e7b005{HTTP/1.1, (http/1.1)}{0.0.0.0:4040}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.util.Utils][Successfully started service 'SparkUI' on port 4040.]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@38b6097d{/,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.executor.Executor][Starting executor ID driver on host jupyter-iamgroot-2eade-40tmdc-2eio]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.executor.Executor][Starting executor with user classpath (userClassPathFirst = false): '']
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.util.Utils][Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 37789.]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.network.netty.NettyBlockTransferService][Server created on jupyter-iamgroot-2eade-40tmdc-2eio:37789]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.storage.BlockManager][Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.storage.BlockManagerMaster][Registering BlockManager BlockManagerId(driver, jupyter-iamgroot-2eade-40tmdc-2eio, 37789, None)]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.storage.BlockManagerMasterEndpoint][Registering block manager jupyter-iamgroot-2eade-40tmdc-2eio:37789 with 366.3 MiB RAM, BlockManagerId(driver, jupyter-iamgroot-2eade-40tmdc-2eio, 37789, None)]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.storage.BlockManagerMaster][Registered BlockManager BlockManagerId(driver, jupyter-iamgroot-2eade-40tmdc-2eio, 37789, None)]
[spark][2024 - 12 - 02 08:23:38][INFO][org.apache.spark.storage.BlockManager][Initialized BlockManager: BlockManagerId(driver, jupyter-iamgroot-2eade-40tmdc-2eio, 37789, None)]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Stopped o.s.j.s.ServletContextHandler@38b6097d{/,null,STOPPED,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@314b33ee{/jobs,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@6fda7e17{/jobs/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@40354c40{/jobs/job,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@5fab7dcc{/jobs/job/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@1a80e679{/stages,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@7f47451f{/stages/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@7322a4bb{/stages/stage,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@1aefc3a0{/stages/stage/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@97588b0{/stages/pool,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@122b311c{/stages/pool/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@7f96a662{/storage,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@2aa8c193{/storage/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@26ae3045{/storage/rdd,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@2e39f5fd{/storage/rdd/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@1c161af5{/environment,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@37d9b263{/environment/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@394519b0{/executors,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@64e6cade{/executors/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@23c3431a{/executors/threadDump,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@5e968584{/executors/threadDump/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@7ed3cf2{/static,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@3e4c0647{/,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@5adece5c{/api,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@5843f92b{/jobs/job/kill,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@4fdbfbb{/stages/stage/kill,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:23:38][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@75d0b889{/metrics/json,null,AVAILABLE,@Spark}]
Step 5: Import the CSV file into the Notebook environment¶
Upload the CSV file from the local machine to the Notebook environment.
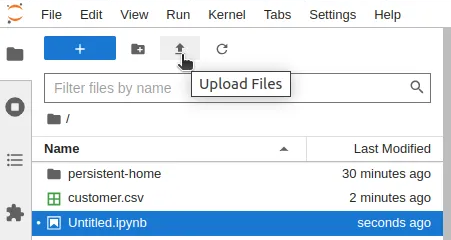
Step 6: Load the CSV file into the Spark Dataframe¶
In the next cell, run the following code that loads the CSV file into a Spark DataFrame with the column names inferred from the header. The data frame can then be used for further Spark operations.
Expected Output
[spark][2024 - 12 - 02 08:26:15][INFO][org.apache.spark.sql.internal.SharedState][Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir.]
[spark][2024 - 12 - 02 08:26:15][INFO][org.apache.spark.sql.internal.SharedState][Warehouse path is 'file:/home/dataos/spark-warehouse'.]
[spark][2024 - 12 - 02 08:26:15][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@56eae416{/SQL,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:26:15][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@67e3a11b{/SQL/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:26:15][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@6d4cc9bd{/SQL/execution,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:26:15][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@278fae9{/SQL/execution/json,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:26:15][INFO][org.sparkproject.jetty.server.handler.ContextHandler][Started o.s.j.s.ServletContextHandler@4da901ba{/static/sql,null,AVAILABLE,@Spark}]
[spark][2024 - 12 - 02 08:26:15][INFO][org.elasticsearch.hadoop.util.Version][Elasticsearch Hadoop v8.3.1 [2b824b4c2a]]
[spark][2024 - 12 - 02 08:26:16][INFO][org.opensearch.hadoop.util.Version][OpenSearch Hadoop v1.0.1 [5f8a79a632]]
[spark][2024 - 12 - 02 08:26:16][INFO][org.apache.spark.sql.execution.datasources.InMemoryFileIndex][It took 25 ms to list leaf files for 1 paths.]
[spark][2024 - 12 - 02 08:26:16][INFO][org.apache.spark.sql.execution.datasources.InMemoryFileIndex][It took 1 ms to list leaf files for 1 paths.]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: (length(trim(value#0, None)) > 0)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<value: string>]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator][Code generated in 161.289096 ms]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_0 stored as values in memory (estimated size 358.9 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_0_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_0_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.3 MiB)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.SparkContext][Created broadcast 0 from csv at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.SparkContext][Starting job: csv at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 0 (csv at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 0 (csv at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 0 (MapPartitionsRDD[3] at csv at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_1 stored as values in memory (estimated size 11.8 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_1_piece0 stored as bytes in memory (estimated size 5.9 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_1_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 5.9 KiB, free: 366.3 MiB)]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.SparkContext][Created broadcast 1 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[3] at csv at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 0.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 0.0 (TID 0) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4903 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 08:26:18][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 0.0 (TID 0)]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: file:///home/dataos/customer.csv, range: 0-527, partition values: [empty row]]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator][Code generated in 9.905967 ms]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 0.0 (TID 0). 1615 bytes result sent to driver]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 0.0 (TID 0) in 271 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 0.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 0 (csv at NativeMethodAccessorImpl.java:0) finished in 0.371 s]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.scheduler.DAGScheduler][Job 0 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 0: Stage finished]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.scheduler.DAGScheduler][Job 0 finished: csv at NativeMethodAccessorImpl.java:0, took 0.404755 s]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator][Code generated in 11.361903 ms]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<value: string>]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_2 stored as values in memory (estimated size 358.9 KiB, free 365.5 MiB)]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_2_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 365.5 MiB)]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_2_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.SparkContext][Created broadcast 2 from csv at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 08:26:19][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
Run the following code for a quick inspection of the data.
Expected Output
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<cust_id: string, cust_dob: string, cust_first_name: string, cust_middle_name: string, cust_last_name: string ... 1 more field>]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_58 stored as values in memory (estimated size 358.8 KiB, free 364.8 MiB)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_58_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 364.7 MiB)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_58_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.SparkContext][Created broadcast 58 from showString at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.SparkContext][Starting job: showString at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 24 (showString at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 24 (showString at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 24 (MapPartitionsRDD[128] at showString at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_59 stored as values in memory (estimated size 10.7 KiB, free 364.7 MiB)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_59_piece0 stored as bytes in memory (estimated size 5.8 KiB, free 364.7 MiB)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_59_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 5.8 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.SparkContext][Created broadcast 59 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 24 (MapPartitionsRDD[128] at showString at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 24.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 24.0 (TID 24) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4903 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 24.0 (TID 24)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: file:///home/dataos/customer.csv, range: 0-527, partition values: [empty row]]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 24.0 (TID 24). 1948 bytes result sent to driver]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 24.0 (TID 24) in 8 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 24.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 24 (showString at NativeMethodAccessorImpl.java:0) finished in 0.012 s]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Job 24 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 24: Stage finished]
[spark][2024 - 12 - 02 09:50:42][INFO][org.apache.spark.scheduler.DAGScheduler][Job 24 finished: showString at NativeMethodAccessorImpl.java:0, took 0.013727 s]
+----------+----------+---------------+----------------+--------------+------------+
| cust_id| cust_dob|cust_first_name|cust_middle_name|cust_last_name|cust_segment|
+----------+----------+---------------+----------------+--------------+------------+
|1000068129|1994-07-07| Yuvraj| null| Shanker| Semi-Urban|
|1000068134|2002-03-22| Prerak| null| Aurora| Urban|
|1000068139|1994-11-09| Divyansh| null| Shere| Rural|
|1000068143|2003-10-26| Krish| null| Gola| Urban|
|1000068147|2001-08-01| Miraya| Biju| Jha| Urban|
|1000068164|1999-04-22| Anya| null| Gandhi| Urban|
|1000068179|2002-06-10| Kanav| null| Badal| Urban|
|1000068185|2001-12-07| Ehsaan| Keya| Sane| Urban|
|1000068193|1993-10-18| Vanya| null| Shere| Semi-Urban|
|1000068199|2002-04-02| Sahil| Aaryahi| Tata| Rural|
+----------+----------+---------------+----------------+--------------+------------+
Step 7: Write the data to the dropzone01 Depot in CSV format¶
In the next cell, run the following code which saves the DataFrame df to a CSV format in the filedrop/customer path of the dropzone01 Depot in DataOS. The overwrite mode ensures any existing data at that location is replaced.
save(
name="dataos://dropzone01:filedrop/customer",
dataframe=df,
format="CSV",
mode="overwrite",
options={"header": "true"}
)
Expected Output
12-02 09:42 - pyflare.sdk.utils.pyflare_logger - INFO - Secrets API status: 200
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<cust_id: string, cust_dob: string, cust_first_name: string, cust_middle_name: string, cust_last_name: string ... 1 more field>]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Job UUID 3fcc59d0-0ba2-410c-a738-e378c0e51ec1 source spark.sql.sources.writeJobUUID]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using committer magic to output data to s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using Committer MagicCommitter{AbstractS3ACommitter{role=Task committer attempt_202412020942436910169306211933304_0000_m_000000_0, name=magic, outputPath=s3a://drop001-uniquehad-dev/filedrop/customer, workPath=s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-3fcc59d0-0ba2-410c-a738-e378c0e51ec1/tasks/attempt_202412020942436910169306211933304_0000_m_000000_0/__base, uuid='3fcc59d0-0ba2-410c-a738-e378c0e51ec1', uuid source=JobUUIDSource{text='spark.sql.sources.writeJobUUID'}}} for s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol][Using output committer class org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: Setup Job (no job ID)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Job 3fcc59d0-0ba2-410c-a738-e378c0e51ec1 setting up]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Job 3fcc59d0-0ba2-410c-a738-e378c0e51ec1 setting up: duration 0:00.132s]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Setup Job (no job ID): duration 0:00.283s]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_46 stored as values in memory (estimated size 358.8 KiB, free 363.6 MiB)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_46_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 363.5 MiB)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_46_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.SparkContext][Created broadcast 46 from save at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.SparkContext][Starting job: save at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 19 (save at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 19 (save at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 19 (MapPartitionsRDD[99] at save at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_47 stored as values in memory (estimated size 209.9 KiB, free 363.3 MiB)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_47_piece0 stored as bytes in memory (estimated size 75.9 KiB, free 363.2 MiB)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_47_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 75.9 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.SparkContext][Created broadcast 47 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 19 (MapPartitionsRDD[99] at save at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 19.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 19.0 (TID 19) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4903 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 19.0 (TID 19)]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Job UUID 3fcc59d0-0ba2-410c-a738-e378c0e51ec1 source fs.s3a.committer.uuid]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using committer magic to output data to s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using Committer MagicCommitter{AbstractS3ACommitter{role=Task committer attempt_202412020942433462190319816390828_0019_m_000000_19, name=magic, outputPath=s3a://drop001-uniquehad-dev/filedrop/customer, workPath=s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-3fcc59d0-0ba2-410c-a738-e378c0e51ec1/tasks/attempt_202412020942433462190319816390828_0019_m_000000_19/__base, uuid='3fcc59d0-0ba2-410c-a738-e378c0e51ec1', uuid source=JobUUIDSource{text='fs.s3a.committer.uuid'}}} for s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol][Using output committer class org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Setup Task attempt_202412020942433462190319816390828_0019_m_000000_19]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Setup Task attempt_202412020942433462190319816390828_0019_m_000000_19: duration 0:00.224s]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: file:///home/dataos/customer.csv, range: 0-527, partition values: [empty row]]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: needsTaskCommit task attempt_202412020942433462190319816390828_0019_m_000000_19]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][needsTaskCommit task attempt_202412020942433462190319816390828_0019_m_000000_19: duration 0:00.021s]
[spark][2024 - 12 - 02 09:42:43][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: Commit task attempt_202412020942433462190319816390828_0019_m_000000_19]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Saving work of attempt_202412020942433462190319816390828_0019_m_000000_19 to s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-3fcc59d0-0ba2-410c-a738-e378c0e51ec1/task_202412020942433462190319816390828_0019_m_000000.pendingset]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Task attempt_202412020942433462190319816390828_0019_m_000000_19 committed 0 files]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Commit task attempt_202412020942433462190319816390828_0019_m_000000_19: duration 0:00.175s]
[Stage 19:> (0 + 1) / 1]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.mapred.SparkHadoopMapRedUtil][attempt_202412020942433462190319816390828_0019_m_000000_19: Committed. Elapsed time: 378 ms.]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 19.0 (TID 19). 2455 bytes result sent to driver]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 19.0 (TID 19) in 793 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 19.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 19 (save at NativeMethodAccessorImpl.java:0) finished in 0.809 s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.scheduler.DAGScheduler][Job 19 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 19: Stage finished]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.scheduler.DAGScheduler][Job 19 finished: save at NativeMethodAccessorImpl.java:0, took 0.811221 s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.sql.execution.datasources.FileFormatWriter][Start to commit write Job 3fcc59d0-0ba2-410c-a738-e378c0e51ec1.]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Task committer attempt_202412020942436910169306211933304_0000_m_000000_0: commitJob((no job ID))]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: committing the output of 1 task(s)]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Loading and committing files in pendingset s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-3fcc59d0-0ba2-410c-a738-e378c0e51ec1/task_202412020942433462190319816390828_0019_m_000000.pendingset]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Loading and committing files in pendingset s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-3fcc59d0-0ba2-410c-a738-e378c0e51ec1/task_202412020942433462190319816390828_0019_m_000000.pendingset: duration 0:00.041s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][committing the output of 1 task(s): duration 0:00.051s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.CommitOperations][Starting: Writing success file s3a://drop001-uniquehad-dev/filedrop/customer/_SUCCESS]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.CommitOperations][Writing success file s3a://drop001-uniquehad-dev/filedrop/customer/_SUCCESS: duration 0:00.119s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Cleanup job (no job ID)]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Aborting all pending commits under s3a://drop001-uniquehad-dev/filedrop/customer]
12-02 09:42 - pyflare.sdk.utils.pyflare_logger - INFO - dataos://dropzone01:filedrop/customer written successfully
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Aborting all pending commits under s3a://drop001-uniquehad-dev/filedrop/customer: duration 0:00.017s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Cleanup job (no job ID): duration 0:00.017s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: Deleting magic directory s3a://drop001-uniquehad-dev/filedrop/customer/__magic]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Deleting magic directory s3a://drop001-uniquehad-dev/filedrop/customer/__magic: duration 0:00.130s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Task committer attempt_202412020942436910169306211933304_0000_m_000000_0: commitJob((no job ID)): duration 0:00.337s]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.sql.execution.datasources.FileFormatWriter][Write Job 3fcc59d0-0ba2-410c-a738-e378c0e51ec1 committed. Elapsed time: 353 ms.]
[spark][2024 - 12 - 02 09:42:44][INFO][org.apache.spark.sql.execution.datasources.FileFormatWriter][Finished processing stats for write job 3fcc59d0-0ba2-410c-a738-e378c0e51ec1.]
Step 7 (Alternate): Write the data to the dropzone01 Depot in JSON format¶
In the next cell, run the following code which saves the DataFrame df to a JSON format in the filedrop/customer path of the dropzone01 Depot in DataOS. The overwrite mode ensures any existing data at that location is replaced.
Expected Output
12-02 09:40 - pyflare.sdk.utils.pyflare_logger - INFO - Secrets API status: 200
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<cust_id: string, cust_dob: string, cust_first_name: string, cust_middle_name: string, cust_last_name: string ... 1 more field>]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Job UUID 26b7ee43-1c38-4d5f-bddc-68a1824d0e57 source spark.sql.sources.writeJobUUID]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using committer magic to output data to s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using Committer MagicCommitter{AbstractS3ACommitter{role=Task committer attempt_202412020940467185015020148846239_0000_m_000000_0, name=magic, outputPath=s3a://drop001-uniquehad-dev/filedrop/customer, workPath=s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-26b7ee43-1c38-4d5f-bddc-68a1824d0e57/tasks/attempt_202412020940467185015020148846239_0000_m_000000_0/__base, uuid='26b7ee43-1c38-4d5f-bddc-68a1824d0e57', uuid source=JobUUIDSource{text='spark.sql.sources.writeJobUUID'}}} for s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol][Using output committer class org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: Setup Job (no job ID)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Job 26b7ee43-1c38-4d5f-bddc-68a1824d0e57 setting up]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Job 26b7ee43-1c38-4d5f-bddc-68a1824d0e57 setting up: duration 0:00.134s]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Setup Job (no job ID): duration 0:00.297s]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_30 stored as values in memory (estimated size 358.8 KiB, free 363.2 MiB)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_30_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 363.2 MiB)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_30_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.SparkContext][Created broadcast 30 from save at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.SparkContext][Starting job: save at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 12 (save at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 12 (save at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 12 (MapPartitionsRDD[64] at save at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_31 stored as values in memory (estimated size 210.7 KiB, free 362.9 MiB)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_31_piece0 stored as bytes in memory (estimated size 76.3 KiB, free 362.9 MiB)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_31_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 76.3 KiB, free: 365.9 MiB)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.SparkContext][Created broadcast 31 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 12 (MapPartitionsRDD[64] at save at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 12.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 12.0 (TID 12) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4903 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 12.0 (TID 12)]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Job UUID 26b7ee43-1c38-4d5f-bddc-68a1824d0e57 source fs.s3a.committer.uuid]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using committer magic to output data to s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitterFactory][Using Committer MagicCommitter{AbstractS3ACommitter{role=Task committer attempt_20241202094046264228146450790120_0012_m_000000_12, name=magic, outputPath=s3a://drop001-uniquehad-dev/filedrop/customer, workPath=s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-26b7ee43-1c38-4d5f-bddc-68a1824d0e57/tasks/attempt_20241202094046264228146450790120_0012_m_000000_12/__base, uuid='26b7ee43-1c38-4d5f-bddc-68a1824d0e57', uuid source=JobUUIDSource{text='fs.s3a.committer.uuid'}}} for s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.spark.sql.execution.datasources.SQLHadoopMapReduceCommitProtocol][Using output committer class org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter]
[spark][2024 - 12 - 02 09:40:46][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Setup Task attempt_20241202094046264228146450790120_0012_m_000000_12]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Setup Task attempt_20241202094046264228146450790120_0012_m_000000_12: duration 0:00.234s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: file:///home/dataos/customer.csv, range: 0-527, partition values: [empty row]]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: needsTaskCommit task attempt_20241202094046264228146450790120_0012_m_000000_12]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][needsTaskCommit task attempt_20241202094046264228146450790120_0012_m_000000_12: duration 0:00.024s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: Commit task attempt_20241202094046264228146450790120_0012_m_000000_12]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Saving work of attempt_20241202094046264228146450790120_0012_m_000000_12 to s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-26b7ee43-1c38-4d5f-bddc-68a1824d0e57/task_20241202094046264228146450790120_0012_m_000000.pendingset]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Task attempt_20241202094046264228146450790120_0012_m_000000_12 committed 0 files]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Commit task attempt_20241202094046264228146450790120_0012_m_000000_12: duration 0:00.161s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.mapred.SparkHadoopMapRedUtil][attempt_20241202094046264228146450790120_0012_m_000000_12: Committed. Elapsed time: 361 ms.]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 12.0 (TID 12). 2498 bytes result sent to driver]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 12.0 (TID 12) in 794 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 12.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 12 (save at NativeMethodAccessorImpl.java:0) finished in 0.806 s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.scheduler.DAGScheduler][Job 12 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 12: Stage finished]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.scheduler.DAGScheduler][Job 12 finished: save at NativeMethodAccessorImpl.java:0, took 0.808394 s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.sql.execution.datasources.FileFormatWriter][Start to commit write Job 26b7ee43-1c38-4d5f-bddc-68a1824d0e57.]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Task committer attempt_202412020940467185015020148846239_0000_m_000000_0: commitJob((no job ID))]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: committing the output of 1 task(s)]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Loading and committing files in pendingset s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-26b7ee43-1c38-4d5f-bddc-68a1824d0e57/task_20241202094046264228146450790120_0012_m_000000.pendingset]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Loading and committing files in pendingset s3a://drop001-uniquehad-dev/filedrop/customer/__magic/job-26b7ee43-1c38-4d5f-bddc-68a1824d0e57/task_20241202094046264228146450790120_0012_m_000000.pendingset: duration 0:00.045s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][committing the output of 1 task(s): duration 0:00.051s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.CommitOperations][Starting: Writing success file s3a://drop001-uniquehad-dev/filedrop/customer/_SUCCESS]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.CommitOperations][Writing success file s3a://drop001-uniquehad-dev/filedrop/customer/_SUCCESS: duration 0:00.094s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Cleanup job (no job ID)]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Starting: Aborting all pending commits under s3a://drop001-uniquehad-dev/filedrop/customer]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Aborting all pending commits under s3a://drop001-uniquehad-dev/filedrop/customer: duration 0:00.011s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Cleanup job (no job ID): duration 0:00.011s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Starting: Deleting magic directory s3a://drop001-uniquehad-dev/filedrop/customer/__magic]
12-02 09:40 - pyflare.sdk.utils.pyflare_logger - INFO - dataos://dropzone01:filedrop/customer written successfully
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.magic.MagicS3GuardCommitter][Deleting magic directory s3a://drop001-uniquehad-dev/filedrop/customer/__magic: duration 0:00.125s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.hadoop.fs.s3a.commit.AbstractS3ACommitter][Task committer attempt_202412020940467185015020148846239_0000_m_000000_0: commitJob((no job ID)): duration 0:00.313s]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.sql.execution.datasources.FileFormatWriter][Write Job 26b7ee43-1c38-4d5f-bddc-68a1824d0e57 committed. Elapsed time: 335 ms.]
[spark][2024 - 12 - 02 09:40:47][INFO][org.apache.spark.sql.execution.datasources.FileFormatWriter][Finished processing stats for write job 26b7ee43-1c38-4d5f-bddc-68a1824d0e57.]
Step 8: Verify the data ingestion¶
In the next cell, run the following code to verify the data ingestion in CSV format.
Expected Output
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_42_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 365.9 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_40_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 365.9 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_49_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 5.9 KiB, free: 365.9 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_50_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_52_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 5.8 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_46_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_39_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_41_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 5.8 KiB, free: 366.0 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_48_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_43_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 7.5 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_37_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_45_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 5.5 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_35_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_38_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 5.9 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_44_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_36_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 5.8 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_47_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 75.9 KiB, free: 366.3 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Removed broadcast_51_piece0 on jupyter-iamgroot-2eade-40tmdc-2eio:37789 in memory (size: 34.1 KiB, free: 366.3 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.InMemoryFileIndex][It took 14 ms to list leaf files for 1 paths.]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.InMemoryFileIndex][It took 20 ms to list leaf files for 1 paths.]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: (length(trim(value#525, None)) > 0)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<value: string>]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_53 stored as values in memory (estimated size 358.9 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_53_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_53_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.3 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.SparkContext][Created broadcast 53 from load at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.SparkContext][Starting job: load at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 22 (load at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 22 (load at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 22 (MapPartitionsRDD[116] at load at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_54 stored as values in memory (estimated size 11.8 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_54_piece0 stored as bytes in memory (estimated size 5.9 KiB, free 365.9 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_54_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 5.9 KiB, free: 366.3 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.SparkContext][Created broadcast 54 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 22 (MapPartitionsRDD[116] at load at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 22.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 22.0 (TID 22) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4973 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 22.0 (TID 22)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: s3a://drop001-uniquehad-dev/filedrop/customer/part-00000-bbc7cbf1-4aac-443e-81f2-99b68ae27fa8-c000.csv, range: 0-518, partition values: [empty row]]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 22.0 (TID 22). 1572 bytes result sent to driver]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 22.0 (TID 22) in 41 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 22.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 22 (load at NativeMethodAccessorImpl.java:0) finished in 0.046 s]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Job 22 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 22: Stage finished]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Job 22 finished: load at NativeMethodAccessorImpl.java:0, took 0.047434 s]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<value: string>]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_55 stored as values in memory (estimated size 358.9 KiB, free 365.5 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_55_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 365.5 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_55_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.SparkContext][Created broadcast 55 from load at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<cust_id: string, cust_dob: string, cust_first_name: string, cust_middle_name: string, cust_last_name: string ... 1 more field>]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_56 stored as values in memory (estimated size 358.8 KiB, free 365.2 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_56_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 365.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_56_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.SparkContext][Created broadcast 56 from showString at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.SparkContext][Starting job: showString at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 23 (showString at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 23 (showString at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 23 (MapPartitionsRDD[125] at showString at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_57 stored as values in memory (estimated size 10.7 KiB, free 365.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_57_piece0 stored as bytes in memory (estimated size 5.8 KiB, free 365.1 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_57_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 5.8 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.SparkContext][Created broadcast 57 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 23 (MapPartitionsRDD[125] at showString at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 23.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 23.0 (TID 23) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4973 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 23.0 (TID 23)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: s3a://drop001-uniquehad-dev/filedrop/customer/part-00000-bbc7cbf1-4aac-443e-81f2-99b68ae27fa8-c000.csv, range: 0-518, partition values: [empty row]]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 23.0 (TID 23). 1948 bytes result sent to driver]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 23.0 (TID 23) in 38 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 23.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 23 (showString at NativeMethodAccessorImpl.java:0) finished in 0.042 s]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Job 23 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 23: Stage finished]
[spark][2024 - 12 - 02 09:43:11][INFO][org.apache.spark.scheduler.DAGScheduler][Job 23 finished: showString at NativeMethodAccessorImpl.java:0, took 0.043868 s]
+----------+----------+---------------+----------------+--------------+------------+
| cust_id| cust_dob|cust_first_name|cust_middle_name|cust_last_name|cust_segment|
+----------+----------+---------------+----------------+--------------+------------+
|1000068129|1994-07-07| Yuvraj| null| Shanker| Semi-Urban|
|1000068134|2002-03-22| Prerak| null| Aurora| Urban|
|1000068139|1994-11-09| Divyansh| null| Shere| Rural|
|1000068143|2003-10-26| Krish| null| Gola| Urban|
|1000068147|2001-08-01| Miraya| Biju| Jha| Urban|
|1000068164|1999-04-22| Anya| null| Gandhi| Urban|
|1000068179|2002-06-10| Kanav| null| Badal| Urban|
|1000068185|2001-12-07| Ehsaan| Keya| Sane| Urban|
|1000068193|1993-10-18| Vanya| null| Shere| Semi-Urban|
|1000068199|2002-04-02| Sahil| Aaryahi| Tata| Rural|
+----------+----------+---------------+----------------+--------------+------------+
Similarly, verify the data ingestion in JSON format.
Expected Output
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.sql.execution.datasources.InMemoryFileIndex][It took 12 ms to list leaf files for 1 paths.]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.sql.execution.datasources.InMemoryFileIndex][It took 18 ms to list leaf files for 1 paths.]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<value: string>]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_62 stored as values in memory (estimated size 358.9 KiB, free 365.3 MiB)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_62_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 365.3 MiB)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_62_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.SparkContext][Created broadcast 62 from load at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.SparkContext][Starting job: load at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 26 (load at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 26 (load at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 26 (MapPartitionsRDD[134] at load at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_63 stored as values in memory (estimated size 14.1 KiB, free 365.2 MiB)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_63_piece0 stored as bytes in memory (estimated size 7.5 KiB, free 365.2 MiB)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_63_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 7.5 KiB, free: 366.2 MiB)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.SparkContext][Created broadcast 63 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 26 (MapPartitionsRDD[134] at load at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 26.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 26.0 (TID 26) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4974 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 26.0 (TID 26)]
[spark][2024 - 12 - 02 09:54:56][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: s3a://drop001-uniquehad-dev/filedrop/customer/part-00000-6fc8b70f-1c45-4931-8276-cc8f66d76d66-c000.json, range: 0-1326, partition values: [empty row]]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 26.0 (TID 26). 2074 bytes result sent to driver]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 26.0 (TID 26) in 44 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 26.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 26 (load at NativeMethodAccessorImpl.java:0) finished in 0.049 s]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Job 26 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 26: Stage finished]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Job 26 finished: load at NativeMethodAccessorImpl.java:0, took 0.050813 s]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Pushed Filters: ]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Post-Scan Filters: ]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.sql.execution.datasources.FileSourceStrategy][Output Data Schema: struct<cust_dob: string, cust_first_name: string, cust_id: string, cust_last_name: string, cust_middle_name: string ... 1 more field>]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_64 stored as values in memory (estimated size 358.8 KiB, free 364.9 MiB)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_64_piece0 stored as bytes in memory (estimated size 34.1 KiB, free 364.8 MiB)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_64_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 34.1 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.SparkContext][Created broadcast 64 from showString at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.sql.execution.FileSourceScanExec][Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.SparkContext][Starting job: showString at NativeMethodAccessorImpl.java:0]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Got job 27 (showString at NativeMethodAccessorImpl.java:0) with 1 output partitions]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Final stage: ResultStage 27 (showString at NativeMethodAccessorImpl.java:0)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Parents of final stage: List()]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Missing parents: List()]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting ResultStage 27 (MapPartitionsRDD[137] at showString at NativeMethodAccessorImpl.java:0), which has no missing parents]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_65 stored as values in memory (estimated size 10.1 KiB, free 364.8 MiB)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.storage.memory.MemoryStore][Block broadcast_65_piece0 stored as bytes in memory (estimated size 5.5 KiB, free 364.8 MiB)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.storage.BlockManagerInfo][Added broadcast_65_piece0 in memory on jupyter-iamgroot-2eade-40tmdc-2eio:37789 (size: 5.5 KiB, free: 366.1 MiB)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.SparkContext][Created broadcast 65 from broadcast at DAGScheduler.scala:1513]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Submitting 1 missing tasks from ResultStage 27 (MapPartitionsRDD[137] at showString at NativeMethodAccessorImpl.java:0) (first 15 tasks are for partitions Vector(0))]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Adding task set 27.0 with 1 tasks resource profile 0]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSetManager][Starting task 0.0 in stage 27.0 (TID 27) (jupyter-iamgroot-2eade-40tmdc-2eio, executor driver, partition 0, PROCESS_LOCAL, 4974 bytes) taskResourceAssignments Map()]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.executor.Executor][Running task 0.0 in stage 27.0 (TID 27)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.sql.execution.datasources.FileScanRDD][Reading File path: s3a://drop001-uniquehad-dev/filedrop/customer/part-00000-6fc8b70f-1c45-4931-8276-cc8f66d76d66-c000.json, range: 0-1326, partition values: [empty row]]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.executor.Executor][Finished task 0.0 in stage 27.0 (TID 27). 1979 bytes result sent to driver]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSetManager][Finished task 0.0 in stage 27.0 (TID 27) in 37 ms on jupyter-iamgroot-2eade-40tmdc-2eio (executor driver) (1/1)]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Removed TaskSet 27.0, whose tasks have all completed, from pool ]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][ResultStage 27 (showString at NativeMethodAccessorImpl.java:0) finished in 0.040 s]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Job 27 is finished. Cancelling potential speculative or zombie tasks for this job]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.TaskSchedulerImpl][Killing all running tasks in stage 27: Stage finished]
[spark][2024 - 12 - 02 09:54:57][INFO][org.apache.spark.scheduler.DAGScheduler][Job 27 finished: showString at NativeMethodAccessorImpl.java:0, took 0.042061 s]
+----------+---------------+----------+--------------+----------------+------------+
| cust_dob|cust_first_name| cust_id|cust_last_name|cust_middle_name|cust_segment|
+----------+---------------+----------+--------------+----------------+------------+
|1994-07-07| Yuvraj|1000068129| Shanker| null| Semi-Urban|
|2002-03-22| Prerak|1000068134| Aurora| null| Urban|
|1994-11-09| Divyansh|1000068139| Shere| null| Rural|
|2003-10-26| Krish|1000068143| Gola| null| Urban|
|2001-08-01| Miraya|1000068147| Jha| Biju| Urban|
|1999-04-22| Anya|1000068164| Gandhi| null| Urban|
|2002-06-10| Kanav|1000068179| Badal| null| Urban|
|2001-12-07| Ehsaan|1000068185| Sane| Keya| Urban|
|1993-10-18| Vanya|1000068193| Shere| null| Semi-Urban|
|2002-04-02| Sahil|1000068199| Tata| Aaryahi| Rural|
+----------+---------------+----------+--------------+----------------+------------+