Product affinity Data Product¶
This section outlines the process for creating and activating a Data Product using an example.
Define use cases¶
An online retail company has set a goal to increase sales in the next year. The business team engaged the Product Manager to develop a Data Product for their use case. The use case aims to determine the likelihood that customers who purchase one product category will also purchase another, focusing on identifying cross-sell opportunities through product affinity analysis. Key business metrics are defined, including the following:
- Cross-sell opportunity score: Measures the likelihood of customers purchasing additional product categories.
- Purchase frequency: Tracks how often customers make purchases over a specific period.
- Total spending: Calculates the overall amount customers spend across all purchases.
Discovering the Data Product¶
The Product Manager used the Data Product Hub to determine if any existing Data Products addressed the use case or could be leveraged to develop a Data Product that meets the requirements. Since no suitable Products were found, it was decided to create a new Data Product from scratch.
Designing the Data Product¶
After defining the use case and key metrics, the Product Manager proceeds to the design phase of the Data Product.
Identify the data source¶
The required dimensions and measures for the Data Product are determined by the Product Manager. The company’s data warehouse is accessed, where the crm_raw_data dataset is found to contain all necessary measures and dimensions for solving the use case with the help of Workbench.
Understanding the data¶
As the crm_raw_data dataset contains more than necessary fields, it is transformed into three datasets customer, product, and purchase. Creating the customer dataset requires transformations. These include selecting the necessary measures and dimensions, renaming the column id to customer_id, year_birth to birth_year, and _income_ to income.
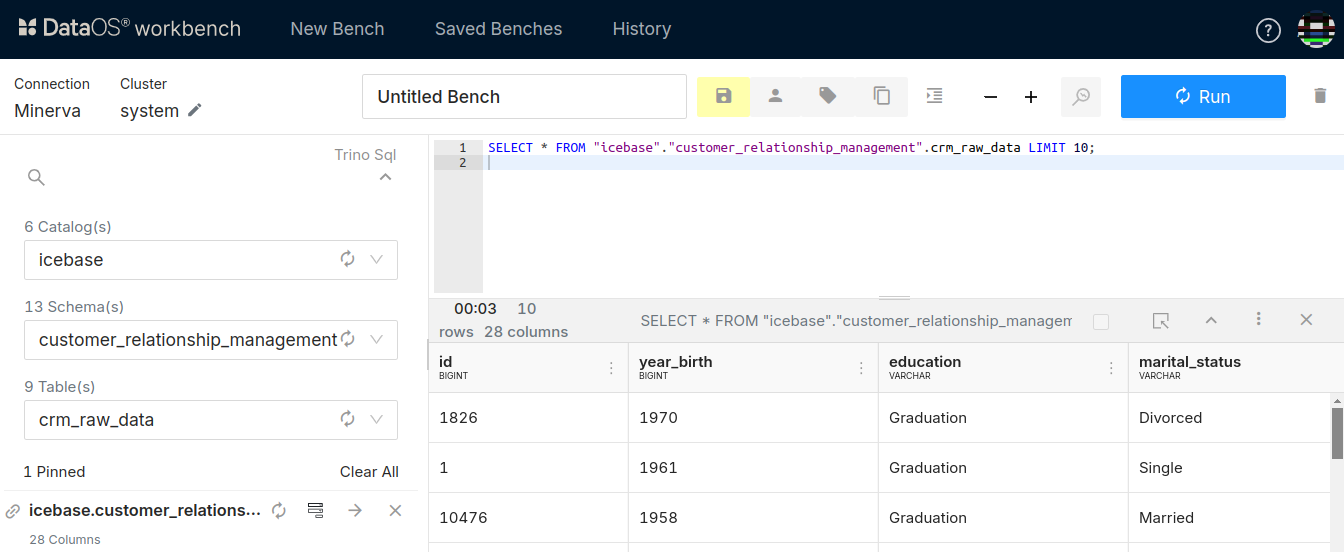
Similarly, for the purchase and product dataset, the necessary measures and dimensions need to be selected, and the column id must be renamed to customer_id.
Defining quality checks¶
After analyzing the data using Workbench, several quality checks are established to ensure adherence to data quality standards:
- Completeness: No missing (null or blank) values are allowed in the
customer_idcolumn, and every row must contain a valid, non-nullcustomer_id. - Schema: The schema must be validated to ensure that column data types align with the defined structure.
- Freshness: Purchase data must be kept up to date.
- Uniqueness: Each
customer_idmust be unique, with no duplicates permitted. - Validity: The
mntwinesattribute must conform to specified criteria, ensuring the data falls within a valid range of 0 to 1. Any occurrence where the invalid count (invalid_count(mntwines)) exceeds 0 highlights a data quality issue that requires attention.
Explore the full range of Soda quality checks available for implementation here.
Defining model¶
The data model is defined in collaboration with the development team. It incorporates three key metrics derived from the customer, product, and purchase tables: cross-sell opportunity score, purchase frequency, and total spending.
Defining metadata of the Data Product¶
In this step, the name, tier, domain, use case, inputs, outputs, and consumption ports of the Data Product are determined.
Building the Data Product¶
After the design phase, the development team initiates building the Data Product according to the specifications defined during the design phase.
Create the Flare job for data transformation¶
The process begins with transforming the crm_raw_data dataset by splitting it into customer, product, and purchase datasets, along with applying the transformations specified in the design phase using a Flare job.
Flare manifest file for customer table
version: v1 # v1
name: wf-customer-data
type: workflow
tags:
- crm
description: Ingesting customer data from crm
workflow:
dag:
- name: dg-customer-data
spec:
tags:
- crm
stack: flare:4.0
compute: runnable-default
flare:
driver:
coreLimit: 2000m
cores: 2
memory: 3000m
executor:
coreLimit: 3000m
cores: 2
instances: 2
memory: 4000m
job:
explain: true
inputs:
- name: customer_data
dataset: dataos://lakehouse:customer_relationship_management/crm_raw_data?acl=rw
format: iceberg
logLevel: INFO
outputs:
- name: final
dataset: dataos://lakehouse:customer_relationship_management/customer?acl=rw
format: Iceberg
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
steps:
- sequence:
- name: final
sql: >
SELECT
id as customer_id,
year_birth as birth_year,
education,
marital_status,
_income_ as income,
country
from customer_data
Flare manifest file for product table
version: v1 # v1
name: wf-product-data
type: workflow
tags:
- crm
description: Ingesting product data from crm
workflow:
dag:
- name: dg-product-data
spec:
tags:
- crm
stack: flare:4.0
compute: runnable-default
flare:
driver:
coreLimit: 2000m
cores: 2
memory: 3000m
executor:
coreLimit: 3000m
cores: 2
instances: 2
memory: 4000m
job:
explain: true
inputs:
- name: raw_data
dataset: dataos://lakehouse:customer_relationship_management/crm_raw_data?acl=rw
format: iceberg
logLevel: INFO
outputs:
- name: final
dataset: dataos://lakehouse:customer_relationship_management/product?acl=rw
format: Iceberg
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
steps:
- sequence:
- name: final
sql: >
SELECT
id as customer_id,
CONCAT(CAST(id AS STRING), '-', CAST(CAST(RAND() * 10000 AS INT) AS STRING)) AS product_id,
CASE
WHEN RAND() < 0.2 THEN 'Wines'
WHEN RAND() < 0.4 THEN 'Meats'
WHEN RAND() < 0.6 THEN 'Fish'
WHEN RAND() < 0.8 THEN 'Sweet Products'
ELSE 'Fruits'
END AS product_category,
CASE
WHEN RAND() < 0.2 THEN 'Red Wine'
WHEN RAND() < 0.4 THEN 'Steak Meat'
WHEN RAND() < 0.6 THEN 'Salmon Fish'
WHEN RAND() < 0.8 THEN 'Chocolate'
ELSE 'Apple'
END AS product_name,
ROUND(10 + RAND() * 90, 2) AS price
from raw_data
Flare manifest file for purchase table
version: v1 # v1
name: wf-purchase-data
type: workflow
tags:
- crm
description: Ingesting purchase data from crm
workflow:
dag:
- name: dg-purchase-data
spec:
tags:
- crm
stack: flare:4.0
compute: runnable-default
flare:
driver:
coreLimit: 2000m
cores: 2
memory: 3000m
executor:
coreLimit: 3000m
cores: 2
instances: 2
memory: 4000m
job:
explain: true
inputs:
- name: purchase_data
dataset: dataos://lakehouse:customer_relationship_management/crm_raw_data?acl=rw
format: iceberg
logLevel: INFO
outputs:
- name: final
dataset: dataos://lakehouse:customer_relationship_management/purchase?acl=rw
format: Iceberg
options:
saveMode: overwrite
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
steps:
- sequence:
- name: final
sql: >
SELECT
id as customer_id,
date_sub(CURRENT_DATE, CAST(recency AS INT)) AS purchase_date,
recency ,
mntwines,
mntmeatproducts,
mntfishproducts,
mntsweetproducts,
mntgoldprods,
mntfruits,
numdealspurchases,
numwebpurchases,
numcatalogpurchases,
numstorepurchases,
numwebvisitsmonth
from purchase_data
Applying the Flare job:
Create the Soda Workflow for quality checks¶
After data ingestion, the next step is to create and apply quality checks on the input datasets using Soda Stack. This requires creating a manifest file for each dataset, as shown below.
Customer table manifest file
name: soda-customer-quality
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Applying quality checks for the customer data
workspace: public
workflow:
dag:
- name: soda-customer-quality
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO # WARNING, ERROR, DEBUG
stackSpec:
inputs:
- dataset: dataos://lakehouse:customer_relationship_management/customer
options:
engine: minerva
clusterName: system
profile:
columns:
- include *
checks:
- schema:
name: Data type of birth year should be integer
fail:
when wrong column type:
birth_year: string
attributes:
category: Schema
- missing_count(customer_id) = 0:
name: Customer Id should not be zero
attributes:
category: Completeness
- duplicate_count(customer_id) = 0:
name: Customer Id should not be duplicated
attributes:
category: Uniqueness
Product table manifest file
name: soda-produtc-quality
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Applying quality checks for the produtc data
workspace: public
workflow:
dag:
- name: soda-product-quality-job
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO # WARNING, ERROR, DEBUG
stackSpec:
inputs:
- dataset: dataos://lakehouse:customer_relationship_management/product
options:
engine: minerva
clusterName: system
profile:
columns:
- include *
checks:
- schema:
name: Response should be in integer format
fail:
when wrong column type:
response: string
attributes:
category: Schema
Purchase table manifest file
name: soda-purchase-quality
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Applying quality checks for the purchase data
workspace: public
workflow:
dag:
- name: soda-purchase-quality-job
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO # WARNING, ERROR, DEBUG
stackSpec:
inputs:
- dataset: dataos://lakehouse:customer_relationship_management/purchase
options:
engine: minerva
clusterName: system
profile:
columns:
- include *
checks:
- freshness(purchase_date) < 2d:
name: If data is older than 2 days
attributes:
category: Freshness
- schema:
name: Data type of recency should be integer
fail:
when wrong column type:
recency: string
attributes:
category: Schema
Applying each manifest file using the following command:
Create the Lens model¶
Following the successful data transformation, the next step is modeling using Lens.
The developer adheres to the steps outlined in the Lens documentation to create the data model. The Lens repository includes a model folder and a deployment manifest file, as illustrated below.

Lens deployment manifest file
version: v1alpha
name: "cross-sell-affinity"
layer: user
type: lens
tags:
- lens
description: This data model provides comprehensive insights for cross-sell and product affinity analysis.
lens:
compute: runnable-default
secrets:
- name: bitbucket-cred
allKeys: true
source:
type: minerva
name: system
catalog: lakehouse
repo:
url: https://bitbucket.org/tmdc/product-affinity-cross-sell
lensBaseDir: product-affinity-cross-sell/resources/lens2/model
syncFlags:
- --ref=main
api: # optional
replicas: 1 # optional
logLevel: info # optional
# envs:
# LENS2_SCHEDULED_REFRESH_TIMEZONES: "UTC,America/Vancouver,America/Toronto"
resources: # optional
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 1000m
memory: 1048Mi
worker: # optional
replicas: 1 # optional
logLevel: debug # optional
# envs:
# LENS2_SCHEDULED_REFRESH_TIMEZONES: "UTC,America/Vancouver,America/Toronto"
resources: # optional
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 1000m
memory: 1248Mi
router: # optional
logLevel: info # optional
# envs:
# LENS2_SCHEDULED_REFRESH_TIMEZONES: "UTC,America/Vancouver,America/Toronto"
resources: # optional
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 1000m
memory: 2548Mi
metric:
logLevel: info
-
The model folder contains three subfolders:
sqls,tables, andviews, and a manifest file for defining the user groups. The user group manifest file is shown below.
model -
The
sqlsfolder contains three sql files as shown below.customer.sql
SELECT customer_id, birth_year, education, marital_status, income, country FROM lakehouse.customer_relationship_management.customerproduct.sql
select customer_id as product_customer_id, product_id, product_category, product_name, price FROM lakehouse.customer_relationship_management.productpurchase.sql
SELECT customer_id as p_customer_id, cast(purchase_date as timestamp) as purchase_date, recency as recency_in_days, mntwines, mntmeatproducts, mntfishproducts, mntsweetproducts, mntgoldprods, mntfruits, numdealspurchases, numwebpurchases, numcatalogpurchases, numstorepurchases, numwebvisitsmonth, numwebpurchases + numcatalogpurchases + numstorepurchases + numstorepurchases as purchases, (mntwines+mntmeatproducts+mntfishproducts+mntsweetproducts+mntgoldprods+mntfruits) as spend FROM lakehouse.customer_relationship_management.purchase -
The
tablesfolder contains three manifest files as shown below.
Customer table manifest file
tables:
- name: customer
sql: {{ load_sql('customer') }}
description: "This table stores key details about the customers, including their personal information, income, and classification into different risk segments. It serves as the central reference point for customer-related insights."
public: true
joins:
- name: purchase_data
relationship: one_to_many
sql: "{TABLE.customer_id}= {purchase_data.p_customer_id}"
dimensions:
- name: customer_id
type: number
column: customer_id
description: "The unique identifier for each customer."
primary_key: true
public: true
- name: birth_year
type: number
column: birth_year
description: "The birth year of the customer, used for demographic analysis and customer segmentation."
- name: education
type: string
column: education
description: "The educational level of the customer, which could be used for profiling and targeted campaigns."
- name: marital_status
type: string
column: marital_status
description: "The marital status of the customer, which may provide insights into purchasing behavior and lifestyle preferences."
- name: income
type: number
column: income
description: "The annual income of the customer in the local currency, which is often a key factor in market segmentation and purchasing power analysis."
- name: country
type: string
column: country
description: "The country where the customer resides, providing geographic segmentation and analysis opportunities."
- name: customer_segments
type: string
sql: >
CASE
WHEN random() < 0.33 THEN 'High Risk'
WHEN random() < 0.66 THEN 'Moderate Risk'
ELSE 'Low Risk'
END AS
description: "Risk-based customer segments derived from the customer_id, used to categorize customers into high, moderate, and low risk groups for targeted campaigns or analysis."
measures:
- name: total_customers
sql: "COUNT({customer_id})"
type: number
description: "The total number of customers in the dataset, used as a basic measure of customer volume."
Product table manifest file
tables:
- name: product
sql: {{ load_sql('product') }}
description: "This table stores the product information."
public: true
dimensions:
- name: product_customer_id
type: string
column: product_customer_id
description: "The unique identifier representing the combination of a customer and a product."
public: false
- name: product_id
type: string
column: product_id
description: "The unique identifier for the product associated with a customer."
primary_key: true
- name: product_category
type: string
column: product_category
description: "The category of the product, such as Wines, Meats, Fish, etc."
- name: product_name
type: string
column: product_name
description: "The name of the product associated with the customer."
- name: price
type: number
column: price
description: "The price of the product assigned to the customer, in monetary units."
- name: product_affinity_score
sql: ROUND(50 + random() * 50, 2)
type: number
description: "customer who purchases one product category will also purchase another category. "
- name: purchase_channel
type: string
sql: >
CASE
WHEN random() < 0.33 THEN 'Web'
WHEN random() < 0.66 THEN 'Store'
ELSE 'Catalog'
END
description: "Describes how the purchase was made (e.g., Web, Store, Catalog)."
measures:
- name: total_products
sql: product_id
type: count
description: "The number of products."
Purchase table manifest file
tables:
- name: purchase_data
sql: {{ load_sql('purchase') }}
description: "This table captures detailed purchase behavior of customers, including their transaction frequency, product category spends, and web interaction history. It serves as the foundation for customer segmentation, recency analysis, and churn prediction."
public: true
joins:
- name: product
relationship: many_to_one
sql: "{TABLE.p_customer_id} = {product.product_customer_id} "
dimensions:
- name: p_customer_id
type: number
column: p_customer_id
description: "The unique identifier for a customer."
primary_key: true
public: false
- name: purchase_date
type: time
column: purchase_date
description: "The date when the customer made their last purchase."
- name: recency_in_days
type: number
column: recency_in_days
description: "The number of days since the customer’s last purchase."
public: false
- name: mntwines
type: number
column: mntwines
description: "The total amount spent by the customer on wine products."
public: false
- name: mntmeatproducts
type: number
column: mntmeatproducts
description: "The total amount spent by the customer on meat products."
public: false
- name: mntfishproducts
type: number
column: mntfishproducts
description: "The total amount spent by the customer on fish products."
public: false
- name: mntsweetproducts
type: number
column: mntsweetproducts
description: "The total amount spent by the customer on sweet products."
public: false
- name: mntgoldprods
type: number
column: mntgoldprods
description: "The total amount spent by the customer on gold products."
public: false
- name: mntfruits
type: number
column: mntfruits
description: "The total amount spent by the customer on fruit products."
public: false
- name: numdealspurchases
type: number
column: numdealspurchases
description: "The number of purchases made by the customer using deals or discounts."
public: false
- name: numwebpurchases
type: number
column: numwebpurchases
description: "The number of purchases made by the customer through the web."
public: false
- name: numcatalogpurchases
type: number
column: numcatalogpurchases
description: "The number of purchases made by the customer through catalogs."
public: false
- name: numstorepurchases
type: number
column: numstorepurchases
description: "The number of purchases made by the customer in physical stores."
public: false
- name: numwebvisitsmont
type: number
column: numwebvisitsmont
description: "The number of times the customer visited the website in the last month."
public: false
- name: purchases
type: number
column: purchases
public: false
- name: spend
type: number
column: spend
public: false
- name: country_name
type: string
sql: "{customer.country}"
description: "The name of the country where the customer is located."
measures:
- name: recency
sql: datediff(current_date,date(purchase_date))
type: min
description: Number of days since the customers last purchase.
- name: purchase_frequency
sql: purchases
type: sum
description: The number of purchases made by the customer in a specific period.
- name: total_spend
sql: spend
type: sum
description: The total amount a customer has spent across all purchases.
- name: average_spend
sql: sum(spend)/nullif(sum(purchases),0)
type: number
description: The average amount spent per transaction by the customer.
- name: churn_probability
sql: "CASE WHEN {recency} < 30 AND {total_spend} > 500 THEN 0.9 WHEN {recency} BETWEEN 30 AND 90 AND {total_spend} BETWEEN 100 AND 500 THEN 0.5 WHEN {recency} > 90 OR {total_spend} < 100 THEN 0.2 ELSE 0.1 END"
type: number
description: "The predicted likelihood that a customer will churn, based on purchase behavior and recency."
- name: cross_sell_opportunity_score
sql: >
sum((mntwines * 0.25 + mntmeatproducts * 0.2 + mntfishproducts * 0.15 + mntsweetproducts * 0.1 + mntgoldprods * 0.3 + mntfruits * 0.2))
/sum(numwebpurchases + numcatalogpurchases + numstorepurchases + 1)
description: "The potential for cross-selling a secondary product based on previous purchase patterns."
type: number
-
The views folder contains three manifest files, each defining a Metric as shown below.
cross-sell-opp.yaml
views: - name: cross_sell_opportunity_score description: This metric calculate the potential for cross-selling a secondary product to customers based on past purchases. public: true meta: title: Cross-Sell Opportunity Score tags: - DPDomain.Sales - DPDomain.Marketing - DPUsecase.Customer Segmentation - DPUsecase.Product Recommendation - DPTier.DataCOE Approved metric: expression: "*/45 * * * *" timezone: "UTC" window: "day" excludes: - mntwines - mntmeatproducts - mntfishproducts - mntsweetproducts - mntgoldprods - mntfruits - numwebpurchases - numcatalogpurchases - numstorepurchases tables: - join_path: purchase_data prefix: true includes: - cross_sell_opportunity_score - mntwines - mntmeatproducts - mntfishproducts - mntsweetproducts - mntgoldprods - mntfruits - numwebpurchases - numcatalogpurchases - numstorepurchases - customer_id - purchase_date - join_path: product prefix: true includes: - product_category - product_namepurchase-freq.yaml
views: - name: purchase_frequency description: This metric calculates the average number of times a product is purchased by customers within a given time period public: true meta: title: Product Purchase Frequency tags: - DPDomain.Sales - DPDomain.Marketing - DPUsecase.Customer Segmentation - DPUsecase.Product Recommendation - DPTier.DataCOE Approved metric: expression: "*/45 * * * *" timezone: "UTC" window: "day" excludes: - purchases tables: - join_path: purchase_data prefix: true includes: - purchase_date - customer_id - purchase_frequency - purchases - join_path: product prefix: true includes: - product_category - product_nametotal-spend.yaml
views: - name: total_spending description: This metric measures how many marketing campaigns a customer has engaged with. public: true meta: title: Customer Spending by Product Category tags: - DPDomain.Sales - DPDomain.Marketing - DPUsecase.Customer Segmentation - DPUsecase.Product Recommendation - DPTier.DataCOE Approved metric: expression: "*/45 * * * *" timezone: "UTC" window: "day" excludes: - spend tables: - join_path: purchase_data prefix: true includes: - purchase_date - customer_id - total_spend - spend - join_path: product prefix: true includes: - product_category - product_name
Create the Bundle Resource for applying the Resources¶
Now to apply the Lens Service, a Bundle Resource is created.
name: product-affinity-bundle
version: v1beta
type: bundle
tags:
- dataproduct
description: This bundle resource is for the cross-sell Data Product.
layer: "user"
bundle:
workspaces:
- name: public
description: "This workspace runs bundle resources"
tags:
- dataproduct
- bundleResource
labels:
name: "dataproductBundleResources"
layer: "user"
resources:
- id: lens
file: resources/lens2/deployment.yaml
workspace: public
Apply the Bundle manifest file:
Create a Data Product manifest file¶
After each Resource is created, it is time to create the Data Product manifest file as shown below:
name: product-affinity-cross-sell
version: v1beta
entity: product
type: data
tags:
- DPDomain.Sales
- DPDomain.Marketing
- DPUsecase.Customer Segmentation
- DPUsecase.Product Recommendation
- DPTier.DataCOE Approved
description: Leverages product affinity analysis to identify cross-sell opportunities, enabling businesses to enhance customer recommendations and drive additional sales by understanding the relationships between products purchased together
refs:
- title: 'Workspace Info'
href: https://dataos.info/interfaces/cli/command_reference/#workspace
v1beta:
data:
meta:
title: Product Affinity & Cross-Sell Opportunity
sourceCodeUrl: https://bitbucket.org/tmdc/product-affinity-cross-sell/src/main/
trackerUrl: https://rubikai.atlassian.net/browse/DPRB-65
collaborators:
- name: iamgroot
description: developer
- name: thisisthor
description: consumer
resource:
refType: dataos
ref: bundle:v1beta:product-affinity-bundle
inputs:
- refType: dataos
ref: dataset:lakehouse:customer_relationship_management:customer
- refType: dataos
ref: dataset:lakehouse:customer_relationship_management:purchase
- refType: dataos
ref: dataset:lakehouse:customer_relationship_management:product
outputs:
- refType: dataos
ref: dataset:lakehouse:customer_relationship_management:product_affinity_matrix
- refType: dataos
ref: dataset:lakehouse:customer_relationship_management:cross_sell_recommendations
ports:
lens:
ref: lens:v1alpha:cross-sell-affinity:public
refType: dataos
Apply the Data Product manifest file¶
The Data Product manifest file is applied using the following command:
The Data Product is created successfully!
Deploy the Data Product¶
To deploy the Data Product on the Data Product Hub to make it discoverable and consumable, the Scanner Workflow is created, as given below.
version: v1
name: scan-data-product-dp
type: workflow
tags:
- scanner
- data-product
description: The job scans Data Product from poros
workflow:
dag:
- name: scan-data-product-job
description: The job scans data-product from poros and register data to metis
spec:
tags:
- scanner2
stack: scanner:2.0
compute: runnable-default
stackSpec:
type: data-product
sourceConfig:
config:
type: DataProduct
markDeletedDataProducts: true
dataProductFilterPattern:
includes:
- product-affinity-cross-sell
To apply the Scanner Workflow following command is executed:
Done!
The Data Product is now available on the Data Product Hub and ready for consumption.
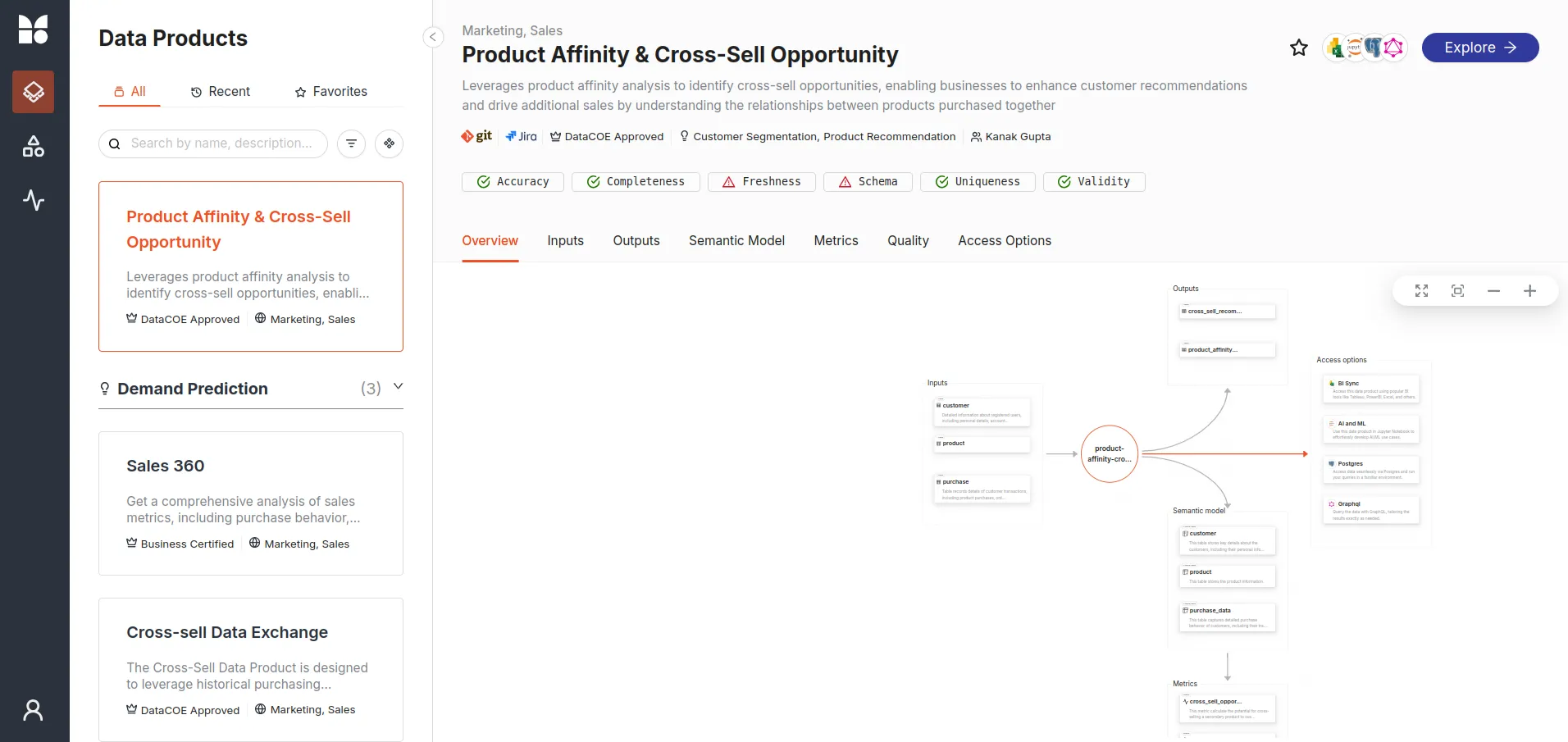
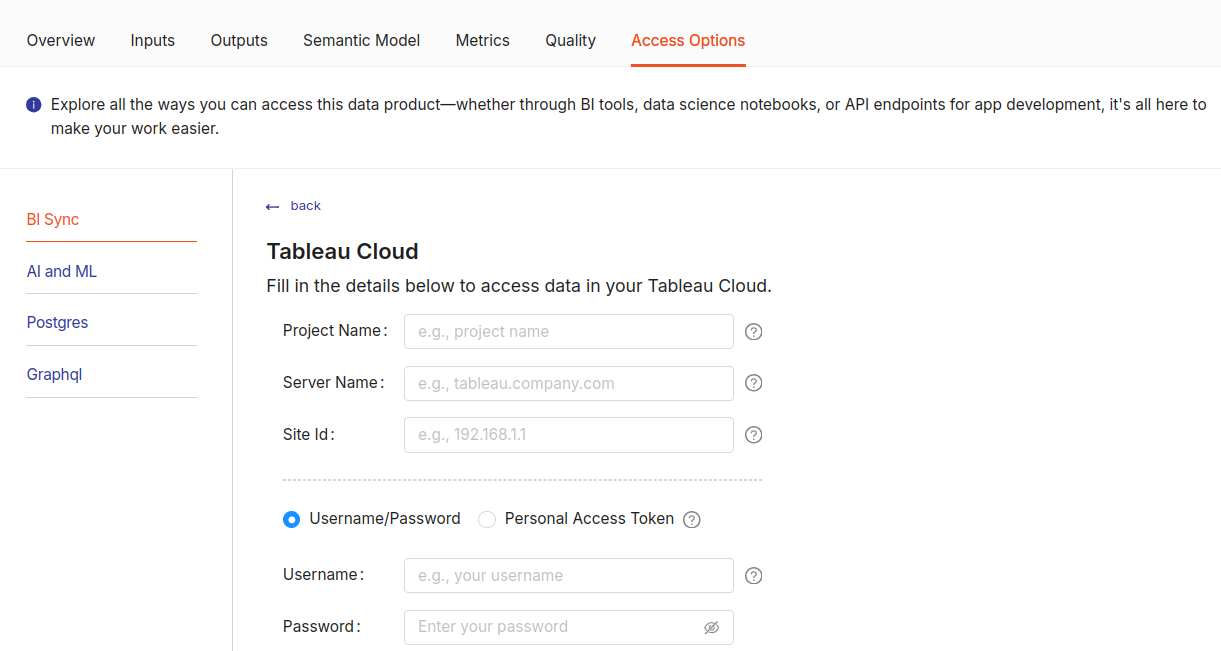
Activate the Data Product via Tableau Cloud¶
Tableau Cloud is used to create the dashboard, enabling the business team to make timely decisions.
Steps followed to create a dashboard on Tableau Cloud:
-
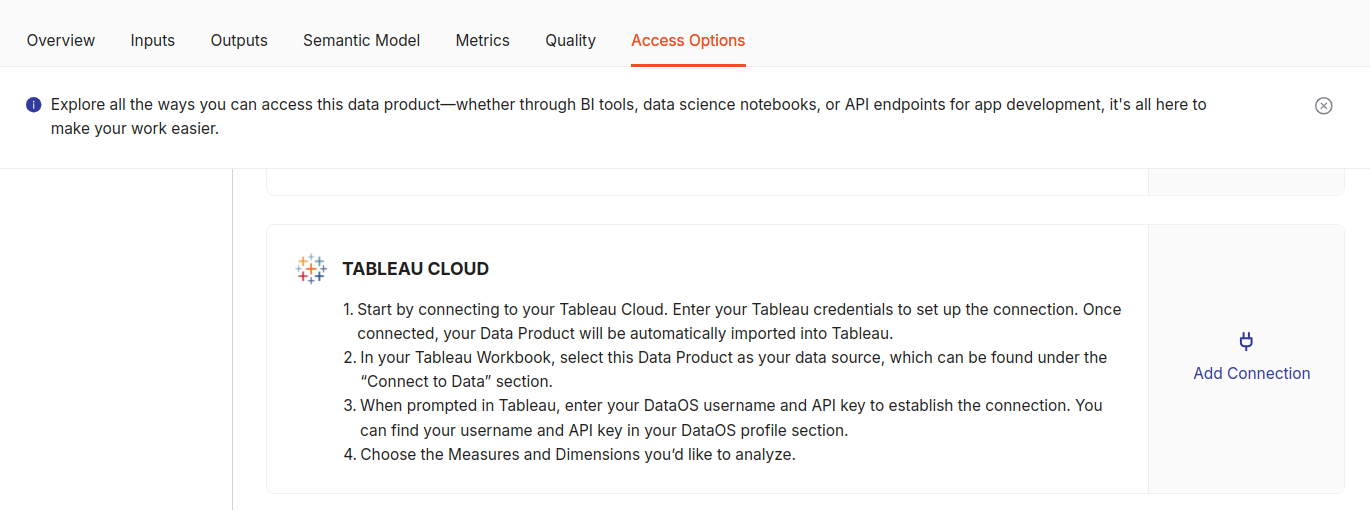
In Data Product Hub, navigate to the ‘Product Affinity & Cross-Sell Opportunity’ Data Product and then ‘Access Options’.
Data Product Hub -
Click on the ‘Add Connection’ option under the ‘TABLEAU CLOUD’ section fill in the required details and click on ‘Activate’.
Data Product Hub -
Now, a dashboard can be created on Tableau Cloud.