Observability¶
This documentation provides a comprehensive guide that explains how to set up and use Observability in DataOS to keep track of how different Resources are working. It helps users understand how to monitor performance, check system health, and get alerts when something goes wrong with the Resources used to build the Data Products. Each section focuses on a specific layer, monitoring, logging, and alerting, and includes instructions, usage examples, and pre-built dashboard integrations.
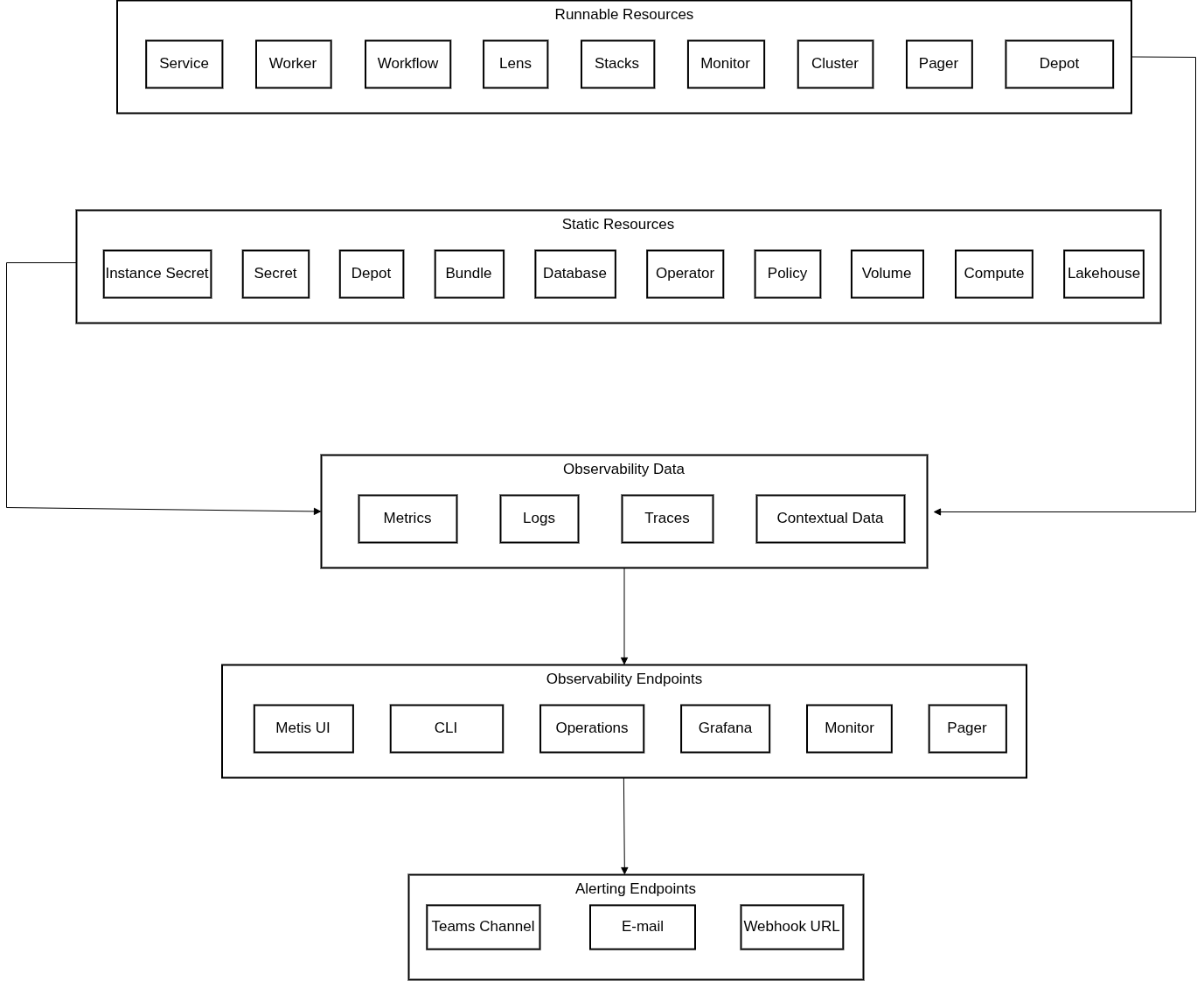
Key Concepts¶
This section introduces the key concepts that power monitoring, logging, alerting, and analysis of observability data in DataOS. Understanding these concepts will help users better track Resource health, investigate issues, and design effective observability setups across different DataOS Resources.
Monitoring¶
Monitoring in DataOS helps users track the health, performance, and behavior of system components using collected metrics. It allows users to detect trends, identify issues early, get alerts, and understand how different resources are running over time.
View Resource health¶
This section describes how users can view the status and runtime of DataOS Resources through the DataOS CLI, Metis Catalog, or Operations App.
- Monitor the status of Instance Secret
- Monitor the status of Secrets
- Monitor the Status of Volume
- Monitor the Status of Lakehouse
- Monitor the Status and Runtime of the Depot
- Monitor the Status and Runtime of the Workflow
- Monitor the Status and Runtime of the Cluster
- Monitor the Status and Runtime of the Service
- Monitor the Status and Runtime of the Worker
- Monitor the Status and Runtime of the Lens
- Monitor the Status of the Compute
- Monitor the Status of the Bundle
CPU and memory usage¶
This section outlines how users can track CPU and memory usage across various DataOS Resources such as Workflows, Clusters, Services, Workers, and Lenses. It highlights multiple ways to observe these metrics using tools like Grafana, Metis Catalog, and the Operations App. Monitoring resource consumption helps teams ensure performance, detect bottlenecks, and optimize workloads effectively.
- Monitor the CPU and memory usage of a Workflow
- Monitor the CPU and memory usage of a Cluster
- Monitor the CPU and memory usage of a Service
- Monitor the CPU and memory usage of a Worker
- Monitor the CPU and memory usage of a Lens
- Monitor the CPU and memory usage of a Depot
Grafana dashboards¶
System metrics for DataOS Resources can be explored through Grafana dashboards. These dashboards offer detailed insights into CPU, memory, and runtime behavior across clusters, pods, and services. Users can navigate these dashboards to quickly assess resource health, analyze trends, and troubleshoot issues using visual cues.
Logging¶
This section focuses on how users can explore and analyze logs generated by various DataOS Resources such as Workflows, Clusters, Services, and more. Logs help in understanding execution details, identifying errors, and troubleshooting issues. Users can access logs through the CLI, Metis UI, Grafana, or the Operations App, depending on the Resource type and preferred interface.
- Monitor the logs of a Workflow
- Monitor the logs of a Cluster
- Monitor the logs of a Service
- Monitor the logs of a Worker
- Monitor the logs of a Lens
- Monitor the logs of a Depot
Alerting¶
This section explains how alerts are set up when issues occur in DataOS Resources. By using Monitor and Pager Resources, users can define conditions for incidents and configure notifications for channels like email, Microsoft Teams, or webhooks. This enables faster response to failures, improves system reliability, and supports proactive monitoring.
CPU alerts¶
This section explains how users can configure alerts when the CPU usage of a Resource exceeds a defined threshold. Monitoring CPU consumption helps teams detect performance bottlenecks early and prevent resource exhaustion.
Memory alerts¶
This section shows how to set alerts for cases where memory usage crosses safe operational limits. By observing memory trends and configuring alerts, users can identify memory leaks, optimize workloads, and avoid service crashes or slowdowns.
Runtime failure alerts¶
This section describes how to detect when a Resource fails to complete successfully. Users can configure monitors to trigger alerts on specific failure statuses, enabling faster response and recovery from disruptions.
Alerts for Resource Runtime Failure
Status change alerts¶
This section guides users on how to monitor the operational status of DataOS Resources. It includes steps to configure alerts for conditions like inactive or stalled components, helping teams stay aware of changes in system behavior and availability.
Alerts for Resource Status Change
Use cases¶
This section provides practical scenarios demonstrating how to leverage DataOS observability features to enhance monitoring, alerting, and overall system management. It covers common use cases involving monitoring Resource health, detecting anomalies, triggering alerts, and optimizing performance.
FAQs¶
-
How do we decide the CPU request and limit for a Resource?
Set the CPU request based on the minimum expected usage under normal load, ensuring stable scheduling. For critical Resources that should never fail, avoid setting CPU limits entirely. If uncertain about requirements, start without limits and observe actual usage patterns. Once you have reasonable assumptions about CPU needs from testing and observation, you can define appropriate limits if necessary. There is no precise way for determining accurate limits; continuous monitoring via the Operations App helps establish optimal configurations.
-
What happens when the DataOS Resources hit CPU limits?
When a Resource exceeds its CPU limit, workloads begin to fail or become unresponsive. This can cause job timeouts, degraded performance, and alert triggers if configured. Immediate remediation involves raising the limit in the YAML config and reapplying the Resource.
-
How do I get alerted when a DataOS Resource crosses its resource limits?
You must configure a Monitor Resource with threshold-based conditions (e.g., CPU usage > 80%) and associate it with a Pager Resource that sends alerts to Teams or other endpoints. The alert condition uses a Prometheus expression to evaluate usage and push incidents to the Pager.
-
How do I debug if I didn't receive an alert?
Check:
- The condition logic in the Monitor.
- The Pager filter
.valueJqFilterandvalue. - The logs of the Pager API pod in the Operations App.
Use
dataos-ctl resource get -t pagerto verify deployment. -
Can I send alerts to both Teams and Email?
Yes. In the
pager.outputsection of the manifest includes bothemailTargetsandmsTeams.webHookUrlas shown below. The same incident can trigger notifications across all configured channels.version: v1alpha type: pager description: Hurry up! mycluster CPU usage have reached the 80% of its limits workspace: public pager: conditions: - valueJqFilter: .properties.name operator: equals value: cpualerts output: msTeams: webHookUrl: https://rubikdatasolutions.webhook.office.com/webhookb2/092-92a8-4d59-9621-9217305bf6ed@2e22bdde-3ec2-43f5-bf92-78e9f35a44fb/IncomingWebhook/92dcd2acdac129e48f/631bd149-c8d3b-8979-8e364f62b419/V23AwNxCZx9JkwfToWpqDSYeRkQefDZ-cPn74pY601 email: - iamgroot@tmdc.io -
How do I test my alert before production?
Use a test Monitor with safe dummy thresholds and a Pager pointed to a test Teams channel or email. Use
dataos-ctl resource apply -f monitor.yamlto deploy and simulate metric spikes if needed. -
How do I query resource usage in real time?
Use Grafana dashboards backed by Prometheus/Thanos data sources. Panels like CPU Usage, Memory Pressure, and Disk Utilization provide real-time insight. You can also execute PromQL queries directly to validate thresholds.