Creating semantic model¶
In this topic, you’ll learn how to design a conceptual semantic model that transforms business needs into structured data. As a Data Engineer, your role is to create a model that aligns with business goals, supports key metrics, and drives insights for decision-making.
Scenario¶
You're building a semantic model for a retail business to analyze purchase patterns and product affinity. The model needs to combine data from various tables in the source such as customer purchase history, product catalogs, and sales data—into a unified view. You want to ensure that your semantic model effectively captures customer behavior and accurately reflects relationships between different products that customers tend to purchase together. For it, you transform conceptual design into a functional data model. This enables you to structure and organize the data effectively, ensuring it meets analytical and business needs.
Folder structure¶
You begin by understanding the structure of the semantic model and organize your data in the following structure in your code editor:
semantic_model/model
├── sqls
│ ├── customer.sql
│ ├── product.sql
│ └── purchase.sql
├── tables
│ ├── customer.yml
│ ├── product.yml
│ └── purchase.yml
└── views
│ ├── total_spend.yml
│ ├── purchase_frequency.yml
│ └── cross_sell_opportunities.yml
└── user_groups.yml
In the semantic model folder structure, you define and organize the artifacts according to the key steps in building the semantic model: loading data, defining tables, adding dimensions and measures, creating views, and managing user groups.
The data used to demonstrate the process of creating a semantic model includes the physical tables
customer_dataandProduct_data, stored in the Lakehouse, andpurchase data, sourced from PostgreSQL.
Sqls¶
Here you load the data from the source by creating the SQL folder, where you write SQL scripts to select relevant columns from the source tables for each entity: customer, product, and purchase data. You focus on choosing only the necessary columns to prevent performance issues while ensuring essential data is available for analysis.
Here are the .sql files you use for each entity:
customer.sql
SELECT
customer_id,
birth_year,
education,
marital_status,
income,
country
FROM
lakehouse.customer_relationship_management.customer_data
product.sql
select
customer_id as product_customer_id,
product_id,
product_category,
product_name,
price
FROM
lakehouse.customer_relationship_management.product_data
This can be a simple extraction or include more complex transformations, such as:
purchase.sql
SELECT
customer_id as p_customer_id,
cast(purchase_date as timestamp) as purchase_date,
recency as recency_in_days,
mntwines,
mntmeatproducts,
mntfishproducts,
mntsweetproducts,
mntgoldprods,
mntfruits,
numdealspurchases,
numwebpurchases,
numcatalogpurchases,
numstorepurchases,
numwebvisitsmonth,
numwebpurchases + numcatalogpurchases + numstorepurchases + numstorepurchases as purchases,
(mntwines+mntmeatproducts+mntfishproducts+mntsweetproducts+mntgoldprods+mntfruits) as spend
FROM
postgres.public.purchase_data
Tables¶
Next, you move to the tables folder. Here, you define a manifest to load the selected columns from the SQL files into tables in YAML. Here, you define the base table for all entities.
1. Table definition section¶
This is the foundational section where you define the core table properties.
-
name: Specifies the table name.
-
sql: Points to the SQL defined in the
/sqlfolder. for example:customer.sql -
description: Provides context about the table.
-
public: Indicates whether the table is publicly accessible.
table:
- name: customer
sql: {{ load_sql('customer') }}
description: Table containing information about customers.
After defining the base table, you define measures, dimensions, joins and segments to provide meaningful analysis. Each section serves a specific purpose to ensure a well-structured and accessible data model.
2. Joins section¶
Defines relationships between tables, enabling connected data insights. The relationship could be one-to-one, one-to-many.
-
name: The name of the table being joined.
-
relationship: Specifies the relationship type (e.g., one-to-many).
-
sql: Defines the join condition in SQL syntax.
joins:
- name: purchase_data
relationship: one_to_many
sql: "{TABLE.customer_id}= {purchase_data.p_customer_id}"
3. Dimensions section¶
The Dimension section captures the attributes or fields of the table, detailing metadata and properties for each dimension. These attributes provide critical context and usability for downstream analysis. Here, you add (attributes like customer_id, product_id).
-
name: Specifies the name of the dimension.
-
type: Defines the data type of the dimension (e.g., number, string).
-
column: Maps the dimension to the corresponding database column.
-
description: Provides a brief explanation of the dimension.
-
primary_key: Indicates whether the dimension is a primary key.
-
public: Specifies if the dimension is publicly accessible.
-
meta.secure: Ensures sensitive data is masked for specified user groups.
-
sql: Custom SQL logic to create derived dimensions.
dimensions:
- name: customer_id
type: number
column: customer_id
description: "The unique identifier for each customer."
primary_key: true
public: true
4. Measures section¶
The Measure section defines aggregated metrics derived from the table data such as total_customers, total_products. These measures provide quantitative insights and often include policies to protect sensitive information.
-
name: Specifies the measure name.
-
sql: Contains the aggregation logic.
-
type: Indicates the data type of the measure (e.g., number, string).
-
description: Provides additional details about the measure.
-
secure: Highlights measures that include data policy logic to protect sensitive information. For instance, in the
customertable a data policy is applied to secure the maritial_status column of theproducttable. The applied data policy redacts the data from the users in the ‘dataconsumer’ group.
measures:
- name: total_customers
sql: "COUNT(DISTINCT {customer_id})"
type: number
description: "The total number of unique customers in the dataset, providing an overview of customer base size."
5. Segments section¶
The Segments section defines filters or conditions that segment data based on specific criteria, enabling the creation of subsets of the dataset for more granular analysis. Segments are often used to focus on specific groups of data that meet certain conditions, like customers from a particular region or products from a certain category.
In the YAML manifest, each segment is defined by:
-
name: Specifies the segment's name, which serves as an identifier for the condition or subset of data.
-
sql: Contains the SQL logic or condition that defines the segment. The SQL condition is used to filter the data, ensuring that only the records that meet the condition are included in the segment. In the provided YAML example, the condition is {TABLE}.state = 'Illinois', which means only rows where the state column equals "Illinois" will be included in this segment.
Following are the yaml manifest files of the table of each entity:
Manifest file for customer table
tables:
- name: customer
sql: {{ load_sql('customer') }}
description: "This table stores key details about the customers, including their personal information, income, and classification into different risk segments. It serves as the central reference point for customer-related insights."
public: true
joins:
- name: purchase_data
relationship: one_to_many
sql: "{TABLE.customer_id}= {purchase_data.p_customer_id}"
dimensions:
- name: customer_id
type: number
column: customer_id
description: "The unique identifier for each customer."
primary_key: true
public: true
- name: birth_year
type: number
column: birth_year
description: "The birth year of the customer, used for demographic analysis and customer segmentation."
- name: education
type: string
column: education
description: "The educational level of the customer, which could be used for profiling and targeted campaigns."
- name: marital_status
type: string
column: marital_status
description: "The marital status of the customer, which may provide insights into purchasing behavior and lifestyle preferences."
meta:
secure:
func: redact
user_groups:
includes: "*"
excludes:
- dataconsumer
- name: income
type: number
column: income
description: "The annual income of the customer in the local currency, which is often a key factor in market segmentation and purchasing power analysis."
- name: country
type: string
column: country
description: "The country where the customer resides, providing geographic segmentation and analysis opportunities."
- name: customer_segments
type: string
sql: >
CASE
WHEN random() < 0.33 THEN 'High Risk'
WHEN random() < 0.66 THEN 'Moderate Risk'
ELSE 'Low Risk'
END AS
description: "Risk-based customer segments derived from the customer_id, used to categorize customers into high, moderate, and low risk groups for targeted campaigns or analysis."
measures:
- name: total_customers
sql: "COUNT({customer_id})"
type: number
description: "The total number of customers in the dataset, used as a basic measure of customer volume."
Manifest file for product table
tables:
- name: product
sql: {{ load_sql('product') }}
description: "This table stores the product information."
public: true
dimensions:
- name: product_customer_id
type: string
column: product_customer_id
description: "The unique identifier representing the combination of a customer and a product."
public: true
- name: product_id
type: string
column: product_id
description: "The unique identifier for the product associated with a customer."
primary_key: true
- name: product_category
type: string
column: product_category
description: "The category of the product, such as Wines, Meats, Fish, etc."
- name: product_name
type: string
column: product_name
description: "The name of the product associated with the customer."
- name: price
type: number
column: price
description: "The price of the product assigned to the customer, in monetary units."
meta:
secure:
func: redact
user_groups:
includes: "*"
excludes:
- default
- name: product_affinity_score
sql: ROUND(50 + random() * 50, 2)
type: number
description: "Customer who purchases one product category will also purchase another category."
- name: purchase_channel
type: string
sql: >
CASE
WHEN random() < 0.33 THEN 'Web'
WHEN random() < 0.66 THEN 'Store'
ELSE 'Catalog'
END
description: "Describes how the purchase was made (e.g., Web, Store, Catalog)."
measures:
- name: total_products
sql: product_id
type: count
description: "The number of products."
Manifest file for purchase table
tables:
- name: purchase_data
sql: {{ load_sql('purchase') }}
description: "This table captures detailed purchase behavior of customers, including their transaction frequency, product category spends, and web interaction history. It serves as the foundation for customer segmentation, recency analysis, and churn prediction."
public: true
joins:
- name: product
relationship: many_to_one
sql: "{TABLE.p_customer_id} = {product.product_customer_id}"
dimensions:
- name: p_customer_id
type: number
column: p_customer_id
description: "The unique identifier for a customer."
primary_key: true
public: false
- name: purchase_date
type: time
column: purchase_date
description: "The date when the customer made their last purchase."
- name: recency_in_days
type: number
column: recency_in_days
description: "The number of days since the customer’s last purchase."
public: false
- name: mntwines
type: number
column: mntwines
description: "The total amount spent by the customer on wine products."
public: false
- name: mntmeatproducts
type: number
column: mntmeatproducts
description: "The total amount spent by the customer on meat products."
public: false
- name: mntfishproducts
type: number
column: mntfishproducts
description: "The total amount spent by the customer on fish products."
public: false
- name: mntsweetproducts
type: number
column: mntsweetproducts
description: "The total amount spent by the customer on sweet products."
public: false
- name: mntgoldprods
type: number
column: mntgoldprods
description: "The total amount spent by the customer on gold products."
public: false
- name: mntfruits
type: number
column: mntfruits
description: "The total amount spent by the customer on fruit products."
public: false
- name: numdealspurchases
type: number
column: numdealspurchases
description: "The number of purchases made by the customer using deals or discounts."
public: false
- name: numwebpurchases
type: number
column: numwebpurchases
description: "The number of purchases made by the customer through the web."
public: false
- name: numcatalogpurchases
type: number
column: numcatalogpurchases
description: "The number of purchases made by the customer through catalogs."
public: false
- name: numstorepurchases
type: number
column: numstorepurchases
description: "The number of purchases made by the customer in physical stores."
public: false
- name: numwebvisitsmont
type: number
column: numwebvisitsmont
description: "The number of times the customer visited the website in the last month."
public: false
- name: purchases
type: number
column: purchases
public: false
- name: spend
type: number
column: spend
public: false
- name: country_name
type: string
sql: "{customer.country}"
description: "The name of the country where the customer is located."
measures:
- name: recency
sql: datediff(current_date,date(purchase_date))
type: min
description: Number of days since the customers last purchase.
Views¶
Finally, in the views folder, you create metrics (a type of view) that build on these tables to support the given use case and summarize complex data into meaningful metrics, such as total_spend, purchase_frequency, and cross_sell_opportunities, providing actionable insights for the organization.
1. Meta section¶
The Meta section provides essential metadata for the metric, which includes the title and tags. This section helps categorize the metric within specific domains (such as sales, marketing) and use cases (e.g., customer segmentation, product recommendation). It also includes a tier to specify the approval level or validation status (e.g., DataCOE Approved).
-
Title: A descriptive name for the metric, providing clarity on what the metric measures (e.g., Cross-Sell Opportunity Score).
-
Tags: A set of keywords or labels that help categorize the metric into specific domains, use cases, and approval tiers, making it easier to search and filter across Data Product Hub.
The following tags are typically used in the Meta section:
-
DPDomain: Denotes the domain or business area the metric pertains to, such as Sales, Marketing, Finance, etc. It is important to categorize the metric within a specific domain, as this helps stakeholders understand the business context and relevance of the metric.
-
DPUsecase: Specifies the intended use case or application of the metric, such as Customer Segmentation, Product Recommendation, etc.
-
DPTier: Specifies the approval level or validation status of the metric, e.g., DataCOE Approved, Experimental, etc.
This tags are populated within the Data Product Hub (DPH) and are essential for efficiently categorizing and discovering Data Products. These tags enable users to filter and search for metrics or Data Products that are aligned with their specific business requirements, domains, and use cases. By clearly providing the value to these tags, users can easily navigate through the available metrics, making the DPH an organized and easily accessible repository for Data Products.
meta:
title: Cross-Sell Opportunity Score
tags:
- DPDomain.Sales
- DPDomain.Marketing
- DPUsecase.Customer Segmentation
- DPUsecase.Product Recommendation
- DPTier.DataCOE Approved
For instance, in this case, the Cross-Sell Opportunity Score metric is tagged with both the Customer Segmentation and Product Recommendation use-cases. As a result, the metric will appear in both of these categories in the Data Product Hub interface as shown in the below image.
| Metric visibility in the customer segmentation use-case | Metric visibility in the product recommendation use-case |
|---|---|
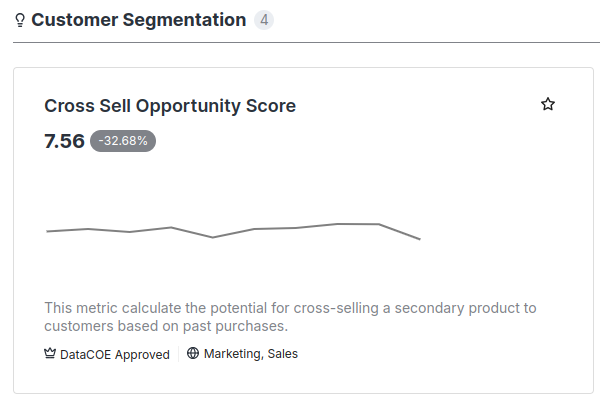 |
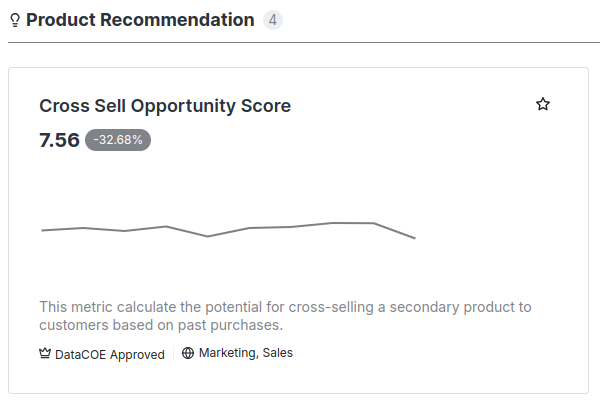 |
Additionally, because of the Sales and Marketing domain tags, as well as the DataCOE Approved tier tag, the metric will also be visible in the Sales and Marketing domains and can be filtered under the DataCOE Approved tier. This means users can easily find the metric by filtering it through these categories and tiers.
2. Metric Section¶
The Metric section defines the actual measure being tracked and the rules for how it is calculated. This includes the expression, time window, and any exclusions.
- Expression: The SQL expression or formula that defines how the metric is calculated (e.g., aggregation of values over a period of time).
- Timezone: Specifies the timezone for the metric calculation (e.g., UTC).
- Window: Defines the time period over which the metric is measured (e.g., daily, weekly, monthly). This is crucial for time-based metrics.
- Excludes: Defines any data to be excluded from the calculation of the metric (e.g., certain product categories or purchase channels).
metric:
expression: "*/45 * * * *"
timezone: "UTC"
window: "day"
excludes:
- mntwines
- mntmeatproducts
- mntfishproducts
- mntsweetproducts
- mntgoldprods
- mntfruits
- numwebpurchases
- numcatalogpurchases
- numstorepurchases
3. Tables Section¶
The Tables section defines the data sources and the structure for the metric. It specifies the join paths, the relationships between different tables, and which columns should be included in the metric calculation.
- Join Path: Defines the data tables to be joined to create a comprehensive view of the metric.
- Prefix: Indicates whether the data from this table should be prefixed in the resulting output, which can help avoid column name conflicts when combining data from multiple sources.
- Includes: Specifies the fields or columns that should be included from each table to calculate the metric (e.g., purchase_date, product_category, customer_id).
tables:
- join_path: purchase_data
prefix: true
includes:
- cross_sell_opportunity_score
- mntwines
- mntmeatproducts
- mntfishproducts
- mntsweetproducts
- mntgoldprods
- mntfruits
- numwebpurchases
- numcatalogpurchases
- numstorepurchases
- customer_id
- purchase_date
- join_path: product
prefix: true
includes:
- product_category
- product_name
Here are the complete manifest files for your reference:
Manifest file for cross-sell-oppurtunity-score metrics
views:
- name: cross_sell_opportunity_score
description: This metric calculate the potential for cross-selling a secondary product to customers based on past purchases.
public: true
meta:
title: Cross-Sell Opportunity Score
tags:
- DPDomain.Sales
- DPDomain.Marketing
- DPUsecase.Customer Segmentation
- DPUsecase.Product Recommendation
- DPTier.DataCOE Approved
metric:
expression: "*/45 * * * *"
timezone: "UTC"
window: "day"
excludes:
- mntwines
- mntmeatproducts
- mntfishproducts
- mntsweetproducts
- mntgoldprods
- mntfruits
- numwebpurchases
- numcatalogpurchases
- numstorepurchases
tables:
- join_path: purchase_data
prefix: true
includes:
- cross_sell_opportunity_score
- mntwines
- mntmeatproducts
- mntfishproducts
- mntsweetproducts
- mntgoldprods
- mntfruits
- numwebpurchases
- numcatalogpurchases
- numstorepurchases
- customer_id
- purchase_date
- join_path: product
prefix: true
includes:
- product_category
- product_name
Manifest file for purchase_frequency metrics
views:
- name: purchase_frequency
description: "This metric calculates the average number of times a product is purchased by customers within a given time period."
public: true
meta:
title: Product Purchase Frequency
tags:
- DPDomain.Sales
- DPDomain.Marketing
- DPUsecase.Customer Segmentation
- DPUsecase.Product Recommendation
- DPTier.DataCOE Approved
metric:
expression: "*/45 * * * *"
timezone: "UTC"
window: "day"
excludes:
- purchases
tables:
- join_path: purchase_data
prefix: true
includes:
- purchase_date
- customer_id
- purchase_frequency
- purchases
- join_path: product
prefix: true
includes:
- product_category
- product_name
Manifest file for total_spend metrics
views:
- name: total_spend
description: "This metric calculates the total amount spent by customers in a given time period."
public: true
meta:
title: Total Spend
tags:
- DPDomain.Sales
- DPDomain.Marketing
- DPUsecase.Customer Segmentation
- DPUsecase.Product Recommendation
- DPTier.DataCOE Approved
metric:
expression: "*/45 * * * *"
timezone: "UTC"
window: "day"
excludes:
- purchases
tables:
- join_path: purchase_data
prefix: true
includes:
- purchase_date
- customer_id
- purchase_frequency
- purchases
- join_path: product
prefix: true
includes:
- product_category
- product_name
User groups¶
After defining the Views, you define user groups to manage access to data effectively. You categorize users based on their roles and responsibilities within the organization, ensuring each group has appropriate access to relevant data while maintaining security.
-
name: The name of the user group. It should be unique and descriptive to identify the group's purpose or role, such as data analyst or developer. Maintain consistent naming conventions across all groups, using underscores or hyphens consistently (e.g., data_analyst or data-analyst). Avoid unclear abbreviations or acronyms.
-
description: A brief description explaining the user group’s purpose and the type of users it contains. For example: "This group contains data analysts who are responsible for reporting and data visualization tasks."
-
api_scopes: A list of API scopes that the user group members are allowed to access. Follow the principle of least privilege by granting users the minimum level of access required. Supported scopes include:
-
meta: Access to metadata-related endpoints.
-
data: Access to data endpoints for retrieval and analysis.
-
graphql: Access to GraphQL endpoints.
-
-
includes: A list of users to include in the group, which can be specific user IDs or patterns like "*" to include all users. If the number of users is small, prefer explicit identifiers (e.g.,
users:id:johndoe). -
excludes: A list of users to exclude from the group, which can be specific user IDs or patterns.
For instance, in the following example, you create a group dataconsumer for data analsysts, business users who require access to detailed data for analysis and reporting. This group can view comprehensive datasets, including sensitive information, which aids in generating insights and making data-driven decisions. Next, you create a default group that includes everyone.
Example user_groups.yml
user_groups:
- name: dataconsumer
api_scopes:
- meta
- data
- graphql
- jobs
- source
includes: users:id:iamgroot
- name: default
api_scopes:
- meta
- data
- graphql
- jobs
- source
includes: "*"
After defining user groups, the next step is to apply data policies to regulate access at a more granular level. Discover how to define and configure data policies here.
Best practices¶
Best practices to follow when creating a semantic model. Key practices include:
-
Naming conventions: Names should begin with a letter and may contain letters, numbers, and underscores (_). Use snake_case for consistency. Examples:
orders,stripe_invoices,base_payments. -
SQL expressions and source dialects: When defining tables with SQL snippets, ensure the expressions match the SQL dialect of your data source. For example, use the
LISTAGGfunction to aggregate a list of strings in Snowflake; Similarly, useSTRING_AGGfunction in bigquery. -
Case sensitivity: If your database uses case-sensitive identifiers, ensure you properly quote table and column names.
-
Partitioning: Keep partitions small for faster processing. Start with a large partition (e.g., yearly) and adjust as needed. Minimize partition queueing by using infrequent refresh keys.
-
References: To create reusable data models, reference table members (e.g., measures, dimensions, columns) using the following syntax:
- Column references: Prefix columns with the table name or use the
TABLEconstant for the current table. Example:TABLE.status. - Member references ({member}): Wrap member names in curly braces when referencing other members of the same table. In the example below, the full_name dimension references the name and surname dimensions of the same table.
- Qualify column and member names with the table name to remove ambiguity when tables are joined and reference members of other tables. Example:
- Use the
{TABLE}variable to reference the current table, avoiding the need to repeat its name. Example:
- Column references: Prefix columns with the table name or use the
-
Non SQL references: Outside of the sql parameter, columns are treated as members (not actual columns). This means you can refer to them by their name directly, without using curly braces. Example:
To know more about the best practices and do's and dont's of modeling click here.