Operator¶
Operator is a DataOS Resource that provides a standardized interface for orchestrating resources situated outside the DataOS cluster, empowering data developers with the capability to invoke actions programmatically upon these external resources directly from interfaces of DataOS.
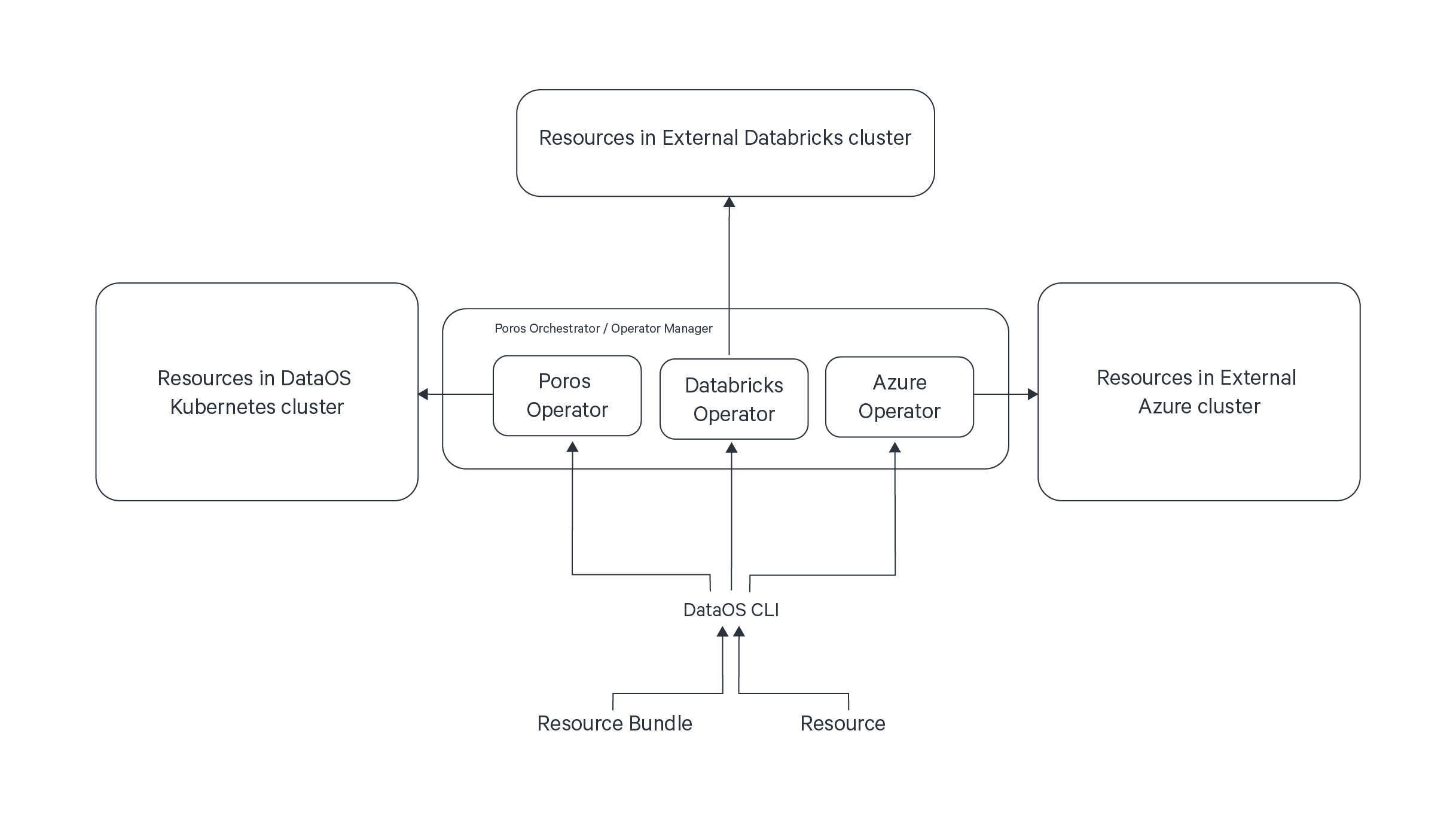
At its core, an Operator empowers the DataOS orchestrator, referred to as Poros, to manage these external resources using custom-built Operators.
Key Features of Operator¶
Extensibility
The Operator augments DataOS capabilities by facilitating integration with external tools and data developer platforms such as Azure Data Factory, Databricks, Snowflake, and more. The external platform could be any platform, application, or service. It doesn't have to be Kubernetes-based, it could be anything that the Operator Pattern supports.
Common Management Plane
The Operator establishes a common management plane to orchestrate external resources. This not only enables CRUD operations but also provides comprehensive monitoring and logging, streamlining Root Cause Analyses (RCAs) and enhancing operational efficiency.
Scalability and Speed
In collaboration with the Bundle Resource within the DataOS, the Operator automates processes, thus accelerating both the scale and speed of data product creation.
Collaboration
The Operator alleviates collaboration hurdles arising from the diversity of technologies, each with its own frameworks, protocols, and languages. It achieves this by enabling cross-functional collaboration through a unified interface.
Integration Burden
The Operator enhances the developer experience and enhances productivity by offering a unified and consistent interface across all external resources. While it does not simplify the underlying architecture, it significantly streamlines interaction with the infrastructure.
How to create an Operator?¶
Let’s take a scenario in which a data developer wants to trigger a pipeline run in Azure Data Factory (external platform) and synchronize the metadata from ADF back into DataOS for observability. But before proceeding ahead, make sure you have the following prerequisites.
Prerequisites¶
Azure Connection Fields¶
To set up your Azure Data Factory Operator, ensure you have the following four fields readily available:
AZURE_SUBSCRIPTION_IDAZURE_CLIENT_IDAZURE_CLIENT_SECRETAZURE_TENANT_ID
Pipeline Run-specific Fields¶
For programmatic triggering, gather information regarding the various fields required for initiating a pipeline run. Refer to the official Azure Data Factory Pipeline Run API documentation for details.
Steps¶
Creating your operator involves a series of logical steps, as outlined below:
- Implementing the Operator Interfaces
a. Reconciler Interface
b. OController Interface
c. Message Handler Interface - Dockerize the Code
- Create manifest file for an Operator
- Apply the Operator manifest
- Verify Operator creation
- Manifest for Resource (external Resource)
- Apply the Resource manifest
- Get Status of Resource
- Check Status on Azure Data Factory UI
- Metadata Synchronization in DataOS
Implementing the Operator Interfaces¶
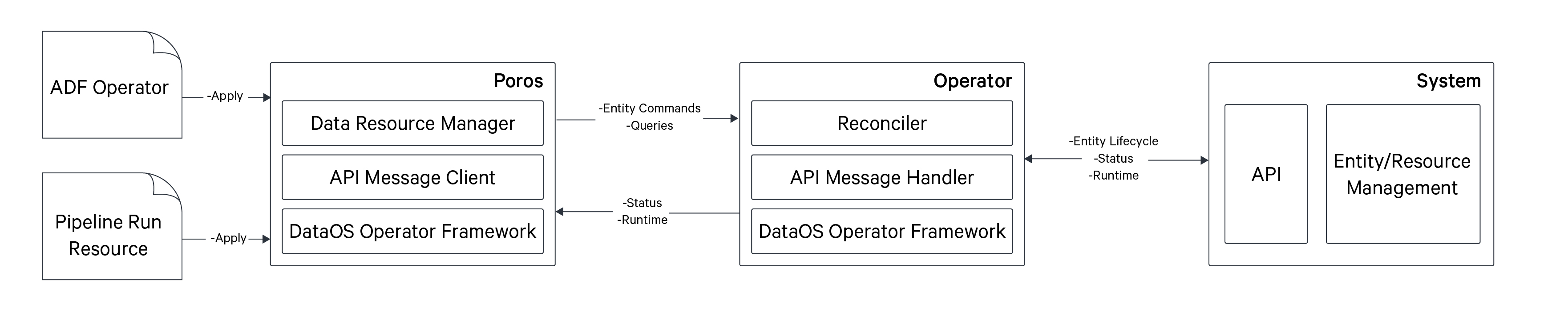
The first step in creating an Operator is implementing three key interfaces: Reconciler, OController, and Message Handler Interface using the the DataOS SDK-Go.
Reconciler Interface
The Reconciler Interface is responsible for reconciling resources based on state changes.
type Reconciler interface {
Id() string
Init(OController)
Reconcile(ReconcileRequest, context.Context) (ReconcileResult, error)
}
OController Interface
OController, the Operator Controller Interface, manages the entity status. The SDK incorporates an entity store, extendable to Redis or a database if required.
type OController interface {
GetEntity(key string, typ EntityOfInterestType) (*Entity, error)
GetEntityStatus(key string, typ EntityOfInterestType) (*EntityStatus, error)
UpdateEntityStatus(es *EntityStatus) error
}
The SDK's controller object implements the OController interface, and the reconciler implementation is integrated into this controller.
Message Handler Interface
The Message Handler Interface deals with communication from the DataOS Orchestrator, Poros.
type MessageHandler interface {
// HandleCommand is the way that upstream controllers can request this
// operator to create, update and delete entities of interest.
HandleCommand(
me *models.MessageEnvelope,
es state.EntityStore,
ess state.EntityStatusStore,
node *snowflake.Node,
) error
// HandleQuery is the way that upstream controllers
// can request information about entities of interest and their status.
HandleQuery(
me *models.MessageEnvelope,
es state.EntityStore,
ess state.EntityStatusStore,
node *snowflake.Node,
) (*models.MessageEnvelope, error)
}
The message handler implementation is employed to create an instance of Messaging API, which manages the communication interface with the NATS Cluster. The state is subsequently captured within the Poros orchestrator using the query interface.
Sample Implementation for the interfaces can be found here.
Dockerize the Code¶
After implementing the required interfaces, dockerize your code and move the image to a docker container registry.
Create a Manifest for Operator¶
Once you have done that proceed to create a YAML manifest for your Operator. An Operator Resource YAML manifest can be structurally broken down into following sections:
Resource Meta section
An Operator is classified as a Resource-type within DataOS. The YAML configuration file of an Operator Resource includes a Resource Meta section that encompasses metadata attributes shared among all Resource-types. For in-depth information about the attributes of Resource Meta section, please consult the Attributes of Resource Meta section.
Operator-specific section
The Operator-specific section is further divided into four distinct sections: Computational components, Resource definition, NATS Cluster configuration, Enabled Workspaces. Each of these sections should be appropriately configured when crafting an Operator YAML.
- Computational Components: Computational Components encapsulate the logic for managing the interactions with resources within the external platform/application/service (external resource), handling the entire lifecycle of associated resources. These components are responsible for reconciling resource states and translating them back to the DataOS orchestrator, Poros. The
componentssection in the Operator-specific section is a list of mappings allowing you to define multiple computational components. Each component is either a Worker or a Service Resource. These components can be customized with unique Docker images, secret configuration, and environment variables to facilitate their execution. - Resource Definition: The Resource definition encompasses specifications for external resources to be orchestrated through DataOS. This definition acts as a comprehensive blueprint, providing all necessary information about the resource and the schema it must adhere to. The resource definition is flexible and can be tailored to suit the specific requirements of the external resource you intend to orchestrate. Multiple resources can be defined to interact with different external platforms as needed.
- NATS Cluster Configuration: NATS is a lightweight pub-sub system. It is used to implement a Command Query Responsibility Segregation (CQRS)-based communication channel between the Operator Runtime, which lives in Poros, and the computational components mentioned above. It's a 2-way communication channel. The operator components have the specific knowledge regarding the management of the resources. They listen for commands and queries on the NATS Cluster. The Operator runtime communicates with the operator components using the specific commands for a Resource-type. Poros Operator takes care of manifesting the NATS Cluster.
- Enabled Workspaces: The
enabledWorkspacesattribute is a list of strings for selectively specifying the Operator within specific workspaces.
The following YAML manifest illustrates the attributes specified within the Operator YAML:
# Resource meta section
name: ${{azure-data-factory}}
version: v1alpha
type: operator
layer: user
description: ${{provides management of azure data factory resources lifecycle}}
tags:
- ${{operator}}
- ${{adf}}
- ${{azure-data-factory}}
# Operator-specific section
operator:
# NATS Cluster configuration
natsClusterConfig:
name: ${{adf-nats}}
compute: ${{runnable-default}}
runAsUser: ${{minerva-cluster}}
# Computational Components
components:
- name: ${{adf-controller}}
type: ${{worker}}
compute: ${{runnable-default}}
runAsUser: ${{minerva-cluster}}
image: ${{docker.io/rubiklabs/azure-operator:0.1.5-dev}}
imagePullSecret: ${{dataos-container-registry}}
command:
- ${{/opt/tmdc-io/azure-operator}}
arguments:
- ${{operator}}
- adf
- --electionStateFile
- /opt/tmdc-io/leader-election.log
replicas: 2
environmentVars:
LOG_LEVEL: info
METRIC_PORT: 30001
ELECTION_CLUSTER_NAME: azure-operators
ELECTION_CLUSTER_SIZE: 1
OPERATOR_MAX_WORKERS: 1
OPERATOR_RECONCILE_WORKERS_INTERVAL: 10s
OPERATOR_MAINTENANCE_INTERVAL: 1m
OPERATOR_PURGE_STATE_STORE_BEFORE: 5m
OPERATOR_STATE_STORE_TYPE: jetstream_kv
MESSAGE_DURABILITY: true
# NATS Cluster specific environment variables
ENTITY_OF_INTEREST_MESSAGE_QUEUE: azure-entities-adf-52323
ENTITY_OF_INTEREST_MESSAGE_STREAM: dataos-azure-entities
ENTITY_OF_INTEREST_MESSAGE_COMMAND_SUBJECT: adf.pipeline.run
ENTITY_OF_INTEREST_MESSAGE_QUERY_SUBJECT: adf.pipeline.run.query
ENTITY_OF_INTEREST_MESSAGE_QUERY_REPLY_SUBJECT: dataos.operator.adf.reply
# Azure Data Factory specific environment variables
AZURE_TENANT_ID: 191b8015-c70b-4cc7-afb0-818de32c05df
AZURE_CLIENT_ID: 769f7469-eaed-4210-8ab7-obc4549d85a1
AZURE_CLIENT_SECRET: LGz8Q-NcuMf~GcPwjAjpJINM6n(iLFiuBsrPubAz
AZURE_SUBSCRIPTION_ID: 79d26b17-3fbf-4c85-a88b-10a4480fac77
ports:
- name: metrics
servicePort: 30001
targetPort: 30001
# Resource Definition
resources:
- name: pipeline-run
isRunnable: true
specSchema:
jsonSchema: |
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://dataos.io/v1.0/azure-data-factory/pipeline-run",
"title": "pipeline-run",
"type": "object",
"properties": {
"factoryName": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"resourceGroupName": {
"type": "string"
},
"parameters": {
"type": "object",
"additionalProperties": true
},
"referencePipelineRunID": {
"type": "string",
"nullable": true
},
"startActivityName": {
"type": "string",
"nullable": true
},
"startFromFailure": {
"type": "boolean",
"nullable": true
}
},
"required": [
"factoryName",
"pipelineName",
"resourceGroupName"
],"additionalProperties": false
}
natsApi:
command:
stream: dataos-zure-entities
subject: adf.pipeline.run
query:
subject: adf.pipeline.run.query
replySubject: dataos.operator.adf.reply
# Enabled Workspaces
enabledWorkspaces:
- public
- sandbox
You can also pass the Azure-specific Secrets separately.
How to pass Secrets as a Resource and refer them in a separate Resource?
Create a Secret Resource manifestname: ${{adf-operator}}
version: v1
description: ${{the secrets for adf operator}}
secret:
type: key-value-properties
acl: rw
data:
AZURE_TENANT_ID: ${{azure tenant id}}
AZURE_CLIENT_ID: ${{azure client id}}
AZURE_CLIENT_SECRET: ${{azure client secret}}
AZURE_SUBSCRIPTION_ID: ${{azure subscription id}}
# Resource meta section
name: ${{azure-data-factory}}
version: v1alpha
type: operator
layer: user
description: ${{provides management of azure data factory resources lifecycle}}
tags:
- ${{operator}}
- ${{adf}}
- ${{azure-data-factory}}
# Operator-specific section
operator:
# NATS Cluster configuration
natsClusterConfig:
name: ${{adf-nats}}
compute: ${{runnable-default}}
runAsUser: ${{minerva-cluster}}
# Computational Components
components:
- name: ${{adf-controller}}
type: ${{worker}}
compute: ${{runnable-default}}
runAsUser: ${{minerva-cluster}}
image: ${{docker.io/rubiklabs/azure-operator:0.1.5-dev}}
imagePullSecret: ${{dataos-container-registry}}
command:
- ${{/opt/tmdc-io/azure-operator}}
arguments:
- ${{operator}}
- adf
- --electionStateFile
- /opt/tmdc-io/leader-election.log
replicas: 2
environmentVars:
LOG_LEVEL: info
METRIC_PORT: 30001
ELECTION_CLUSTER_NAME: azure-operators
ELECTION_CLUSTER_SIZE: 1
OPERATOR_MAX_WORKERS: 1
OPERATOR_RECONCILE_WORKERS_INTERVAL: 10s
OPERATOR_MAINTENANCE_INTERVAL: 1m
OPERATOR_PURGE_STATE_STORE_BEFORE: 5m
OPERATOR_STATE_STORE_TYPE: jetstream_kv
MESSAGE_DURABILITY: true
# NATS specific stuff (not exposing to the user)
ENTITY_OF_INTEREST_MESSAGE_QUEUE: azure-entities-adf-52323
ENTITY_OF_INTEREST_MESSAGE_STREAM: dataos-azure-entities
ENTITY_OF_INTEREST_MESSAGE_COMMAND_SUBJECT: adf.pipeline.run
ENTITY_OF_INTEREST_MESSAGE_QUERY_SUBJECT: adf.pipeline.run.query
ENTITY_OF_INTEREST_MESSAGE_QUERY_REPLY_SUBJECT: dataos.operator.adf.reply
# Passed as Secret Resource
dataosSecrets:
- name: adf-operator
workspace: user-system
allKeys: true
consumptionType: envVars
ports:
- name: metrics
servicePort: 30001
targetPort: 30001
resources: # Resources is a list of Resources that we want to manage
- name: pipeline-run
isRunnable: true
specSchema:
jsonSchema: |
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://dataos.io/v1.0/azure-data-factory/pipeline-run",
"title": "pipeline-run",
"type": "object",
"properties": {
"factoryName": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"resourceGroupName": {
"type": "string"
},
"parameters": {
"type": "object",
"additionalProperties": true
},
"referencePipelineRunID": {
"type": "string",
"nullable": true
},
"startActivityName": {
"type": "string",
"nullable": true
},
"startFromFailure": {
"type": "boolean",
"nullable": true
}
},
"required": [
"factoryName",
"pipelineName",
"resourceGroupName"
],"additionalProperties": false
}
natsApi:
command:
stream: dataos-zure-entities
subject: adf.pipeline.run
query:
subject: adf.pipeline.run.query
replySubject: dataos.operator.adf.reply
enabledWorkspaces:
- public
- sandbox
The table below summarizes the attributes of the Operator-specific section:
| Attribute | Data Type | Default Value | Possible Value | Requirement |
|---|---|---|---|---|
operator |
mapping | none | none | mandatory |
components |
list of mappings | none | none | mandatory |
name |
string | none | none | mandatory |
type |
string | none | service/worker | mandatory |
compute |
string | none | runnable-default or any other custom Compute Resource name | mandatory |
runAsApiKey |
string | Apikey of user | valid DataOS Apikey | mandatory |
runAsUser |
string | none | user-id of Use Case Assignee | optional |
image |
string | none | valid image name | mandatory |
imagePullSecret |
string | none | valid Secret Resource for pulling images from the Private Container Registry | optional |
command |
list of strings | none | valid command | optional |
arguments |
list of strings | none | valid arguments | optional |
replicas |
integer | none | any integer | mandatory |
environmentVars |
mapping | none | list of available environment variables given here | optional |
secrets |
mapping | none | none | optional |
name |
string | none | valid Secret Resource name | mandatory |
workspace |
string | none | valid Workspace name | mandatory |
ports |
list of mappings | none | none | optional |
name |
string | none | valid string | mandatory |
servicePort |
integer | none | valid port | mandatory |
targetPort |
integer | none | valid port | mandatory |
resources |
mapping | none | none | mandatory |
name |
string | none | valid resources name | mandatory |
nameJqFilter |
string | none | valid string | optional |
isRunnable |
boolean | false | true/false | mandatory |
specSchema |
mapping | none | none | optional |
jsonSchema |
string | none | none | mandatory |
natsApi |
mapping | none | none | optional |
command |
mapping | none | none | mandatory |
stream |
string | none | valid stream | mandatory |
subject |
string | none | valid subject | mandatory |
query |
mapping | none | none | mandatory |
subject |
string | none | valid subject | mandatory |
replySubject |
string | none | valid replySubject | mandatory |
natsClusterConfig |
mapping | none | none | mandatory |
name |
string | none | valid name | mandatory |
compute |
string | none | runnable-default or any other custom Compute Resource name | mandatory |
runAsUser |
string | none | user-id of Use Case Assignee | optional |
runAsApiKey |
string | Apikey of user | valid DataOS Apikey (if not provided it takes the user’s default apikey) | mandatory |
enabledWorkspaces |
list of strings | none | valid DataOS Workspace | mandatory |
For in-depth information about the attributes of the Operator-specific section, please consult the Attributes of Operator-specific section.
Apply the Operator manifest¶
After creating the YAML configuration file for the Operator Resource, it's time to apply it to instantiate the Resource-instance in the DataOS environment. To apply the Operator YAML file, utilize the apply command.
Verify Operator Creation¶
To ensure that your Operator has been successfully created, you can verify it in two ways:
Check the name of the newly created Operator in the list of Operators where you are named as the owner:
dataos-ctl get -t operator
# Expected Output
INFO[0000] 🔍 get...
INFO[0000] 🔍 get...complete
NAME | VERSION | TYPE | WORKSPACE | STATUS | RUNTIME | OWNER
---------------|---------|----------|-----------|--------|---------|-------------------
adf-operator | v1alpha | operator | | active | | iamgroot
Alternatively, retrieve the list of all Operators created in your organization:
You can also access the details of any created Operator through the DataOS GUI in the Operations App.
Manifest for a Resource¶
Now once we have created an Operator, we would need to create a Resource (external Resource) which is an Azure Data Factory pipeline that would be managed by this Operator. In DataOS, the process of creating external Resources involves utilizing a specific type of Resource called, aptly, "Resource." These Resources are categorized as second-class Resources, distinct from the first-class Resources like Workflow, Service, and Policy.
Resource as a Resource, in essence, serves as a means to interact with Operators. While Workflow, Service, and Policy Resources are first-class and can be independently managed, Resources created through the Resource are specifically designed for use with Operators. Below is the Resource YAML for the external ADF pipeline Resource:
# Resource meta section
name: ${{pipeline-run-1}}
version: v1alpha
type: resource
tags:
- ${{adf-pipeline}}
- ${{adf-operator}}
description: ${{adf pipeline run}}
owner: iamgroot
# Resource-specific section
resource:
operator: ${{adf-operator}}
type: ${{pipeline-run}}
spec:
factoryName: ${{datafactoryoz3un3trdpaa}}
pipelineName: ${{ArmtemplateSampleCopyPipeline}}
resourceGroupName: ${{Engineering}}
When creating Resources with this approach, the Operator's JSON Schema plays a vital role in validation. The spec provided in the Resource YAML is validated against this schema, ensuring that the Resource conforms to the predefined structure.
Apply the Resource manifest¶
To trigger a pipeline run, you can apply the Resource YAML using the following command:
dataos-ctl apply -f ${{resource-yaml-file-path}} -w ${{workspace}}
# Sample
dataos-ctl apply -f ./resources/adf-operator/resource.yaml -w public
Get Status of Pipeline Run¶
dataos-ctl get -t resource -w ${{workspace}}
# Sample
dataos-ctl get -t resource -w public
# Expected Output
INFO[0000] 🔍 get...
INFO[0000] 🔍 get...complete
NAME | VERSION | TYPE | WORKSPACE | STATUS | RUNTIME | OWNER
-----------------|---------|----------|-----------|--------|------------|-------------------
pipeline-run-1 | v1alpha | resource | public | active | inprogress | iamgroot
Check the Status on Azure Data Factory UI¶
Once we apply we can go over on the Azure Data Factory UI.
Before Pipeline run
After Pipeline run
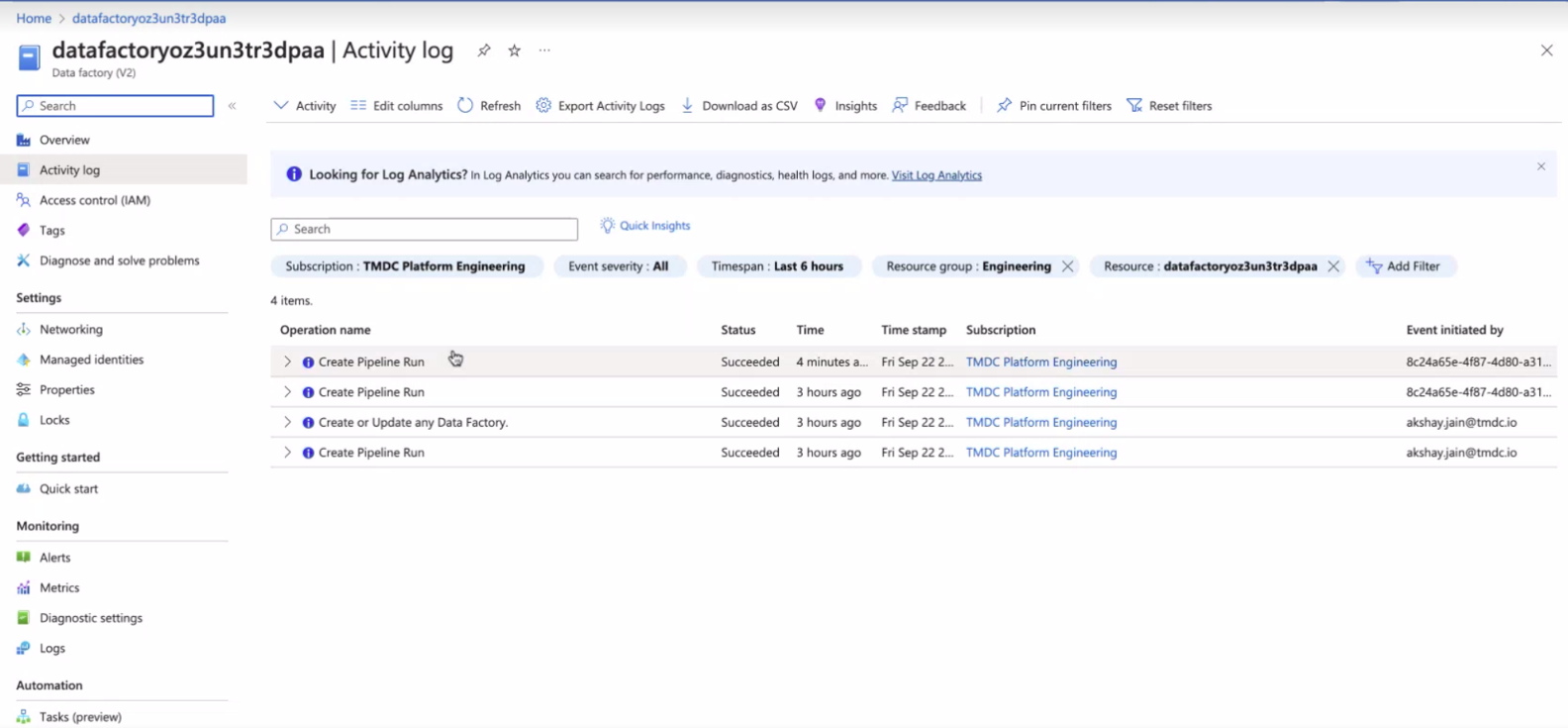
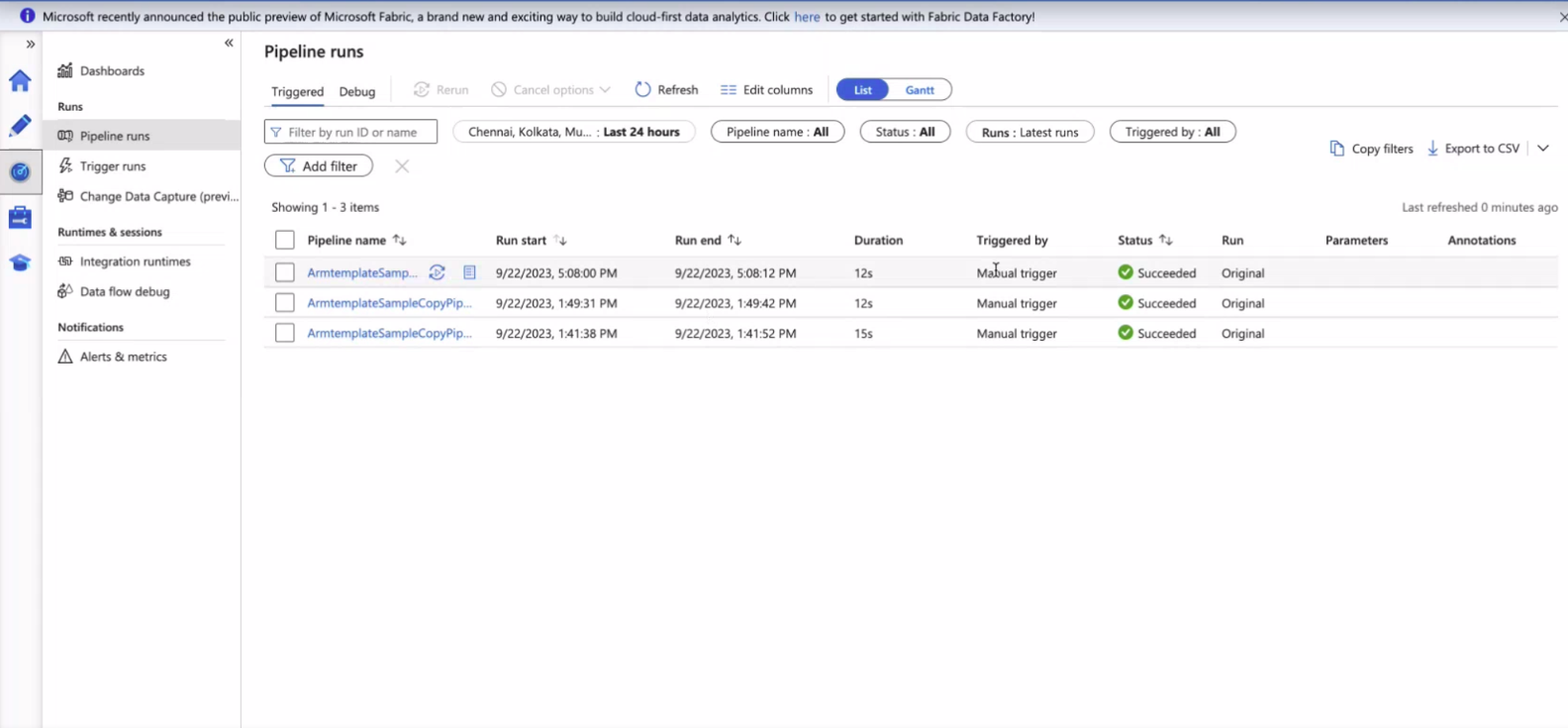
Metadata Synchronization in DataOS¶
While the pipeline is in progress, you have the capability to capture metadata from Azure Data Factory back into DataOS Metis. The process of metadata capture is orchestrated through the Operator Component and NATS Cluster. While coding the Operator, you have the complete complete control over determining which specific state information from the external cluster, in this case, Azure Cluster, should be retrieved and synchronized with DataOS. To get information about which information is being synchronized, utilize the following command:
Here, ${{external-resource-name}} should be replaced with the relevant identifier, such as the name of the specific external resource (Resource) run:
Delete Operator¶
If you need to delete an operator, you first need to delete all the workloads or Resources that are dependent on it. Once it's done, use the delete command to remove the specific operator from the DataOS instance:
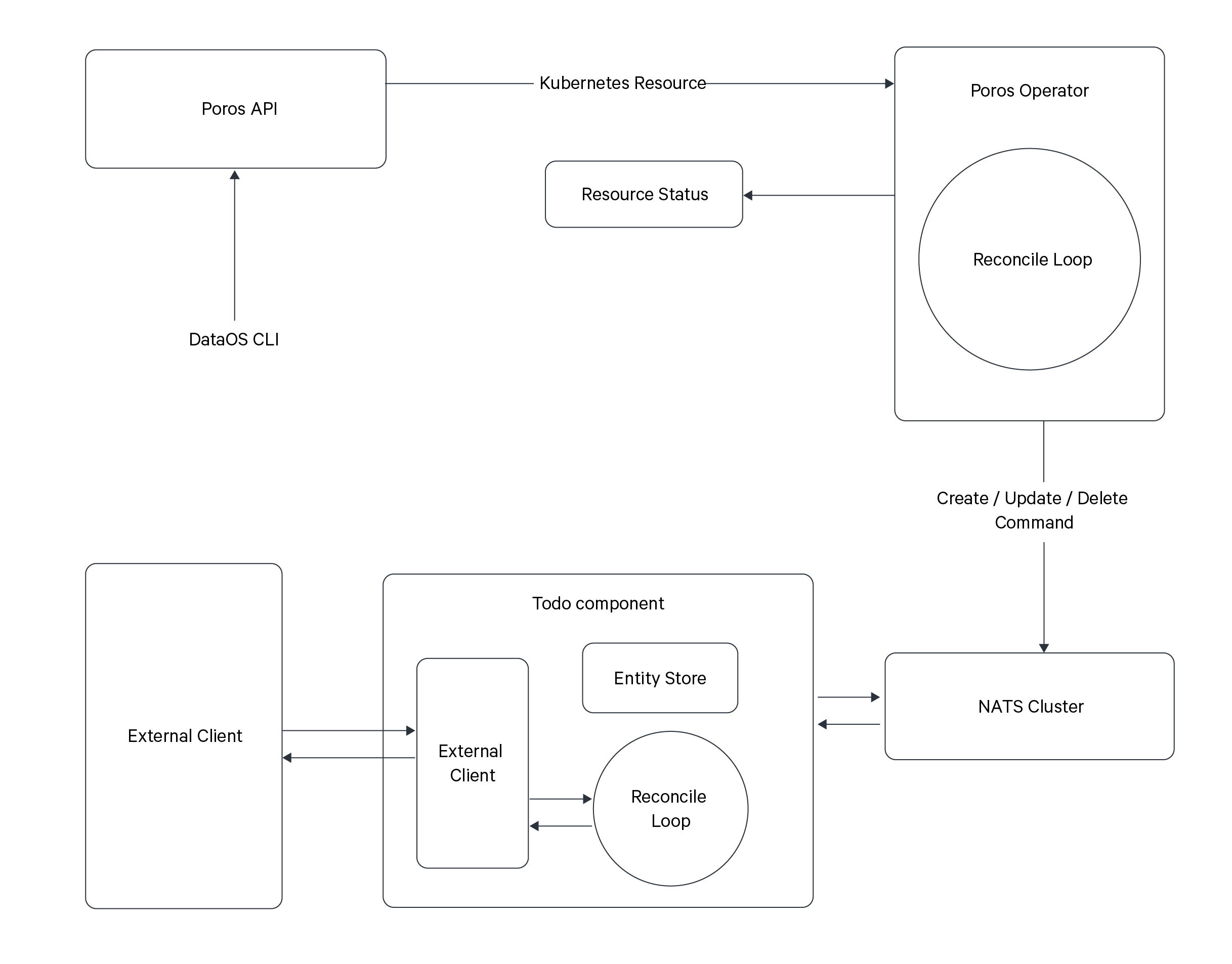
How does the Operator Work?¶
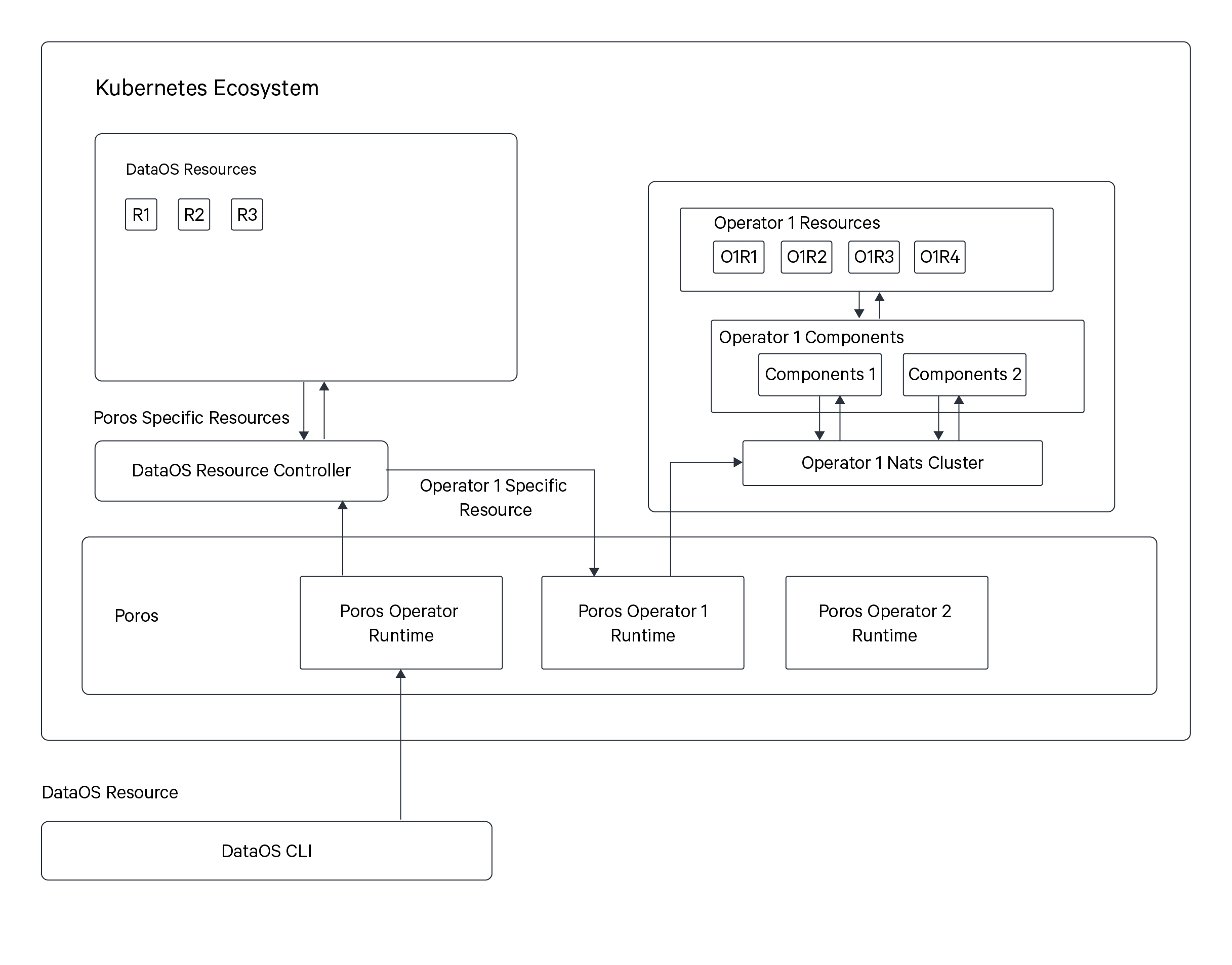
The diagram illustrates the workings of the DataOS Kubernetes Cluster and the process that unfolds when applying an Operator YAML via the DataOS Command Line Interface (CLI).
- Applying YAML Manifest: When a user applies an Operator YAML through the CLI, the Resource API takes this information to the DataOS Orchestrator, known as Poros.
- Poros Orchestrator: Poros serves as an Operator Manager, housing multiple Operators within it. One of these Operators is the Poros Operator, responsible for managing DataOS-specific Resources within the Kubernetes cluster.
- Custom Operator Runtime: The Operator YAML creates a custom Operator runtime within Poros. This runtime is responsible for overseeing the operation of an external Resource.
- NATS Cluster Creation: The Operator YAML also includes NATS Cluster configuration. The Operator Runtime establishes a pub-sub communication with the NATS Cluster.
- Operator Component: This is the Worker or Service Resource that contains the docker image, and secret configurations for interfacing with external third-party services, platforms, or ecosystems. It could involve services like Databricks Workspace, Azure Data Factory, or others. The Operator Component interacts with these external resources via their REST APIs, enabling CRUD (Create, Read, Update, Delete) operations and other specific functionalities.
- NATS Cluster Communication: The Operator Component communicates with the NATS Cluster, which acts as the communication channel between the Operator Component and the Operator Runtime.
- JSON Schema and Resource Definition: The creation of the Operator YAML also involves providing a JSON schema for the external Resource.
- Resource YAML Application: Additionally, a secondary YAML is created, defining a new Resource-type called "Resource." Within this Resource, a reference to the specific Operator responsible for managing it is specified. The Resource spec is validated against the Operator's JSON schema. When the Resource YAML is applied, it informs the DataOS Orchestrator that this Resource will be managed by the custom Operator runtime created earlier.
- Command Query Responsibility Segregation (CQRS) Pattern: The Operator adheres to the Command Query Responsibility Segregation (CQRS) Pattern, ensuring a clear separation of commands and queries.
- Command: When executing commands such as creating, updating, or deleting, the system forwards these actions to the NATS Cluster. The NATS Cluster then communicates with the compute component associated with the Operator, which subsequently dispatches the pertinent information to the external platform or service.
- Query: Simultaneously, the system offers a querying mechanism for retrieving information about the status and details of the service. Executing the
dataos-ctl getcommand initiates a query operation, which traverses through the NATS Cluster. The query is then directed to the entity store within the computational component, which maintains the desired state information.