Troubleshooting Guide¶
Overview
Creating Data Products in DataOS can be powerful—but like any platform, the early stages may come with a few challenges. This guide outlines common errors and how to resolve them, helping you troubleshoot faster and build with confidence. It’s not a complete list, but it covers the issues most users face when getting started. For more in-depth information, please refer to the detailed documentation at dataos.info
Depot Related Errors¶
PostgreSQL Issues¶
Problem: Errors while setting up a depot using a local PostgreSQL account.
Solution: Use a cloud-based PostgreSQL instance and seek guidance from the PostgreSQL team if needed.
Remarks: Local setups may have configuration limitations.
S3 Depot Issues¶
Problem: Depot Scan for S3 not working.
Solution: Skip the scanner process and test the ingested data directly on Workbench. Ensure that the created depot is added to the Cluster.
Remarks: Scanners cannot be run on object storage as it primarily stores files rather than structured data. Scanners require metadata structures, which are often unavailable in object storage.
Workbench Related Errors¶
Problem: Not able to query on Workbench.
Solution: Add the newly created Depot to the Cluster before querying. If you lack permission, contact the Administrator.
Flare Ingestion Errors¶
-
Problem: Job finished with error: "Could not alter output datasets for workspace."
Cause: The same workflow name already exists.
Solution: Change the job/workflow name.
-
Problem: Too old resource version.
Solution: Update to the latest version.
-
Problem: Too many data columns.
Cause: A column was added to the schema at the time of ingestion.
Solution: Validate schema changes before ingestion.
-
Problem: Missing Required Data Columns
Cause: The schema is registered with columns
t1, t2, t3, t4, t5, but the user provides data only fort1, t2, t4, t5. solution: Ensure that all required columns are present in the data as per the registered schema.Error Log:
2025-02-05 11:31:49,003 INFO [metrics-prometheus-reporter-1-thread-1] org.apache.spark.banzaicloud.metrics.sink.PrometheusSink: metricsNamespace=Some(flare), sparkAppName=Some(workflow:v1:wf-marketing-data:public:dg-marketing-data), sparkAppId=Some(spark-10d6d52d7f3d4f8ea3cc416f9b658f17), executorId=Some(driver) 2025-02-05 11:31:49,004 INFO [metrics-prometheus-reporter-1-thread-1] org.apache.spark.banzaicloud.metrics.sink.PrometheusSink: role=driver, job=flare 2025-02-05 11:31:49,211 INFO [main] org.apache.iceberg.BaseMetastoreCatalog: Table loaded by catalog: hadoop.customer_relationship_management.marketing007 2025-02-05 11:31:49,289 INFO [main] org.apache.iceberg.hadoop.HadoopTables: Table location loaded: abfss://lake001@dlake0bnoss0dsck0stg.dfs.core.windows.net/lakehouse01/customer_relationship_management/marketing007 2025-02-05 11:31:49,317 ERROR [main] io.dataos.flare.Flare$: =>Flare: Job finished with error build version: 8.0.20; workspace name: public; workflow name: wf-marketing-data; workflow run id: ec55pur8s2kg; run as user: aadityasoni; job name: dg-marketing-data; org.apache.spark.sql.AnalysisException: [INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_FIND_DATA] Cannot write incompatible data for the table `abfss://lake001@dlake0bnoss0dsck0stg`.`dfs`.`core`.`windows`.`net/lakehouse01/customer_relationship_management/marketing007`: Cannot find data for the output column `acceptedcmp3`. at org.apache.spark.sql.errors.QueryCompilationErrors$.incompatibleDataToTableCannotFindDataError(QueryCompilationErrors.scala:2135) at org.apache.spark.sql.catalyst.analysis.TableOutputResolver$.$anonfun$reorderColumnsByName$1(TableOutputResolver.scala:191) at scala.collection.immutable.List.flatMap(List.scala:366) at org.apache.spark.sql.catalyst.analysis.TableOutputResolver$.reorderColumnsByName(TableOutputResolver.scala:180) -
Problem: Adding a New Column while ingesting data to an Existing Schema
Cause: The schema is registered with
t1, t2, t3, t4, t5, and the user attempts to create a new columnt6.Solution: Follow the existing schema structure or update the schema to accommodate the new column before adding data.
2025-02-05 11:41:25,907 INFO [dispatcher-BlockManagerMaster] org.apache.spark.storage.BlockManagerInfo: Removed broadcast_2_piece0 on 10.212.5.241:36997 in memory (size: 38.9 KiB, free: 1020.0 MiB) 2025-02-05 11:41:25,941 INFO [main] org.apache.iceberg.hadoop.HadoopTables: Table location loaded: abfss://lake001@dlake0bnoss0dsck0stg.dfs.core.windows.net/lakehouse01/customer_relationship_management/marketing007 2025-02-05 11:41:26,002 ERROR [main] io.dataos.flare.Flare$: =>Flare: Job finished with error build version: 8.0.20; workspace name: public; workflow name: wf-marketing-data; workflow run id: ec56knam2gw0; run as user: aadityasoni; job name: dg-marketing-data; org.apache.spark.sql.AnalysisException: [INSERT_COLUMN_ARITY_MISMATCH.TOO_MANY_DATA_COLUMNS] Cannot write to `abfss://lake001@dlake0bnoss0dsck0stg`.`dfs`.`core`.`windows`.`net/lakehouse01/customer_relationship_management/marketing007`, the reason is too many data columns: Table columns: `__metadata`, `customer_id`, `acceptedcmp1`, `acceptedcmp2`, `acceptedcmp3`, `acceptedcmp4`, `acceptedcmp5`, `response`. Data columns: `__metadata`, `customer_id`, `acceptedcmp1`, `acceptedcmp2`, `acceptedcmp3`, `acceptedcmp4`, `acceptedcmp5`, `response`, `load_date`. at org.apache.spark.sql.errors.QueryCompilationErrors$.cannotWriteTooManyColumnsToTableError(QueryCompilationErrors.scala:2114) at org.apache.spark.sql.catalyst.analysis.TableOutputResolver$.resolveOutputColumns(TableOutputResolver.scala:52) at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveOutputRelation$$anonfun$apply$50.applyOrElse(Analyzer.scala:3413) at org. -
Problem: Path Not Found Error.
Cause: Input path does not match cloud source.
Solution:
- Check input path.
- Validate the path from Metis→Resources.
- Problem: Label names and value length exceed 47 characters.
Cause: Workflow and DAG names exceed 47 characters.
Solution: Reduce the length of workflow & DAG names.
-
Problem: Invalid Input UDL Name
Cause: Cannot construct instance of
io.dataos.flare.configurations.job.input.Inputdue to an invalid dataset.Solution: Provide the correct UDL name.
Error Log
-
Problem: Invalid File Format
Cause: The input file format is incompatible or incorrect.
Solution: Choose the correct file format.
Error Log:
2022-11-18 07:57:27,726 ERROR [main] i.d.f.Flare$: =>Flare: Job finished with error build version: 6.0.91-dev; workspace name: public; workflow name: test-03-dataset; workflow run id: 3bdc1dcb-5130-49a5-97e9-e332e238396a; run as user: piyushjoshi; job name: sample-123; job run id: 3b0c3db5-ea06-4727-96ff-8f493ff80257; java.lang.ClassNotFoundException: Failed to find data source: csvbb. -
Problem: Exceeding Character Limit in Workflow Config
Cause: Workflow name exceeds the allowed limit.
Solution: Ensure the workflow name does not exceed 48 characters.
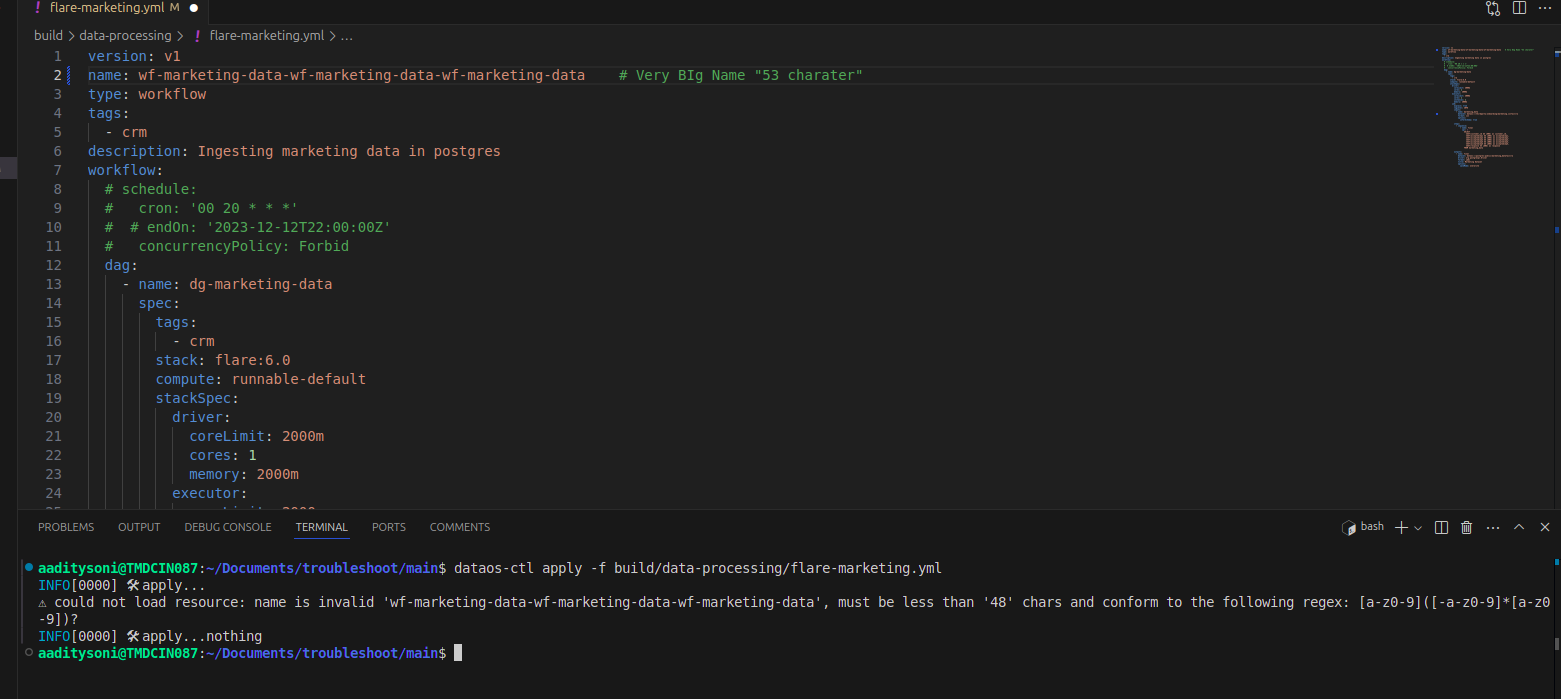
-
Problem: Exceeding Character Limit in DAG Config
Cause: Job name exceeds the allowed limit.
Solution: Ensure the Job name does not exceed 48 characters.
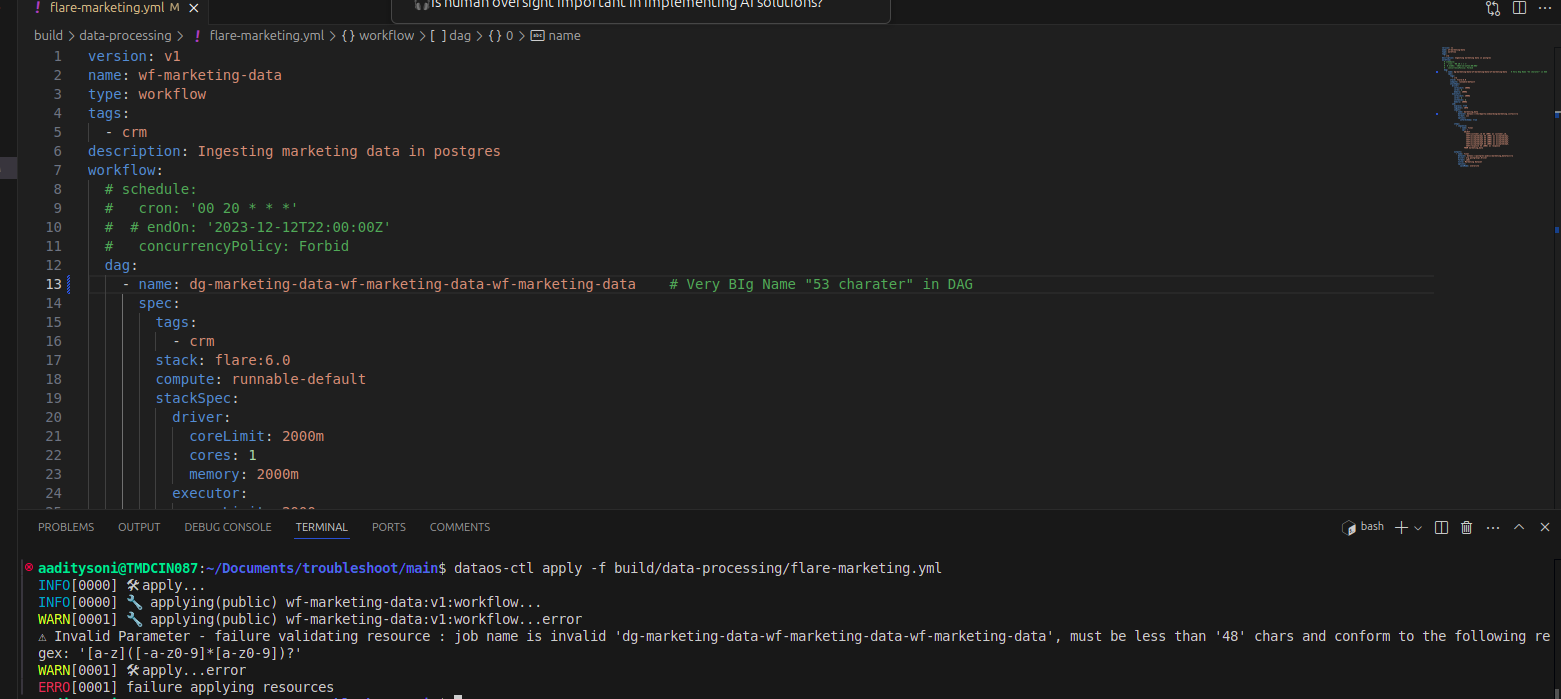
-
Problem: Incorrect Depot Name in Workflow Cause: The workflow fails due to an incorrect depot name. Solution: a. Verify that the depot name is correctly spelled. b. Ensure the depot exists in the system before use.
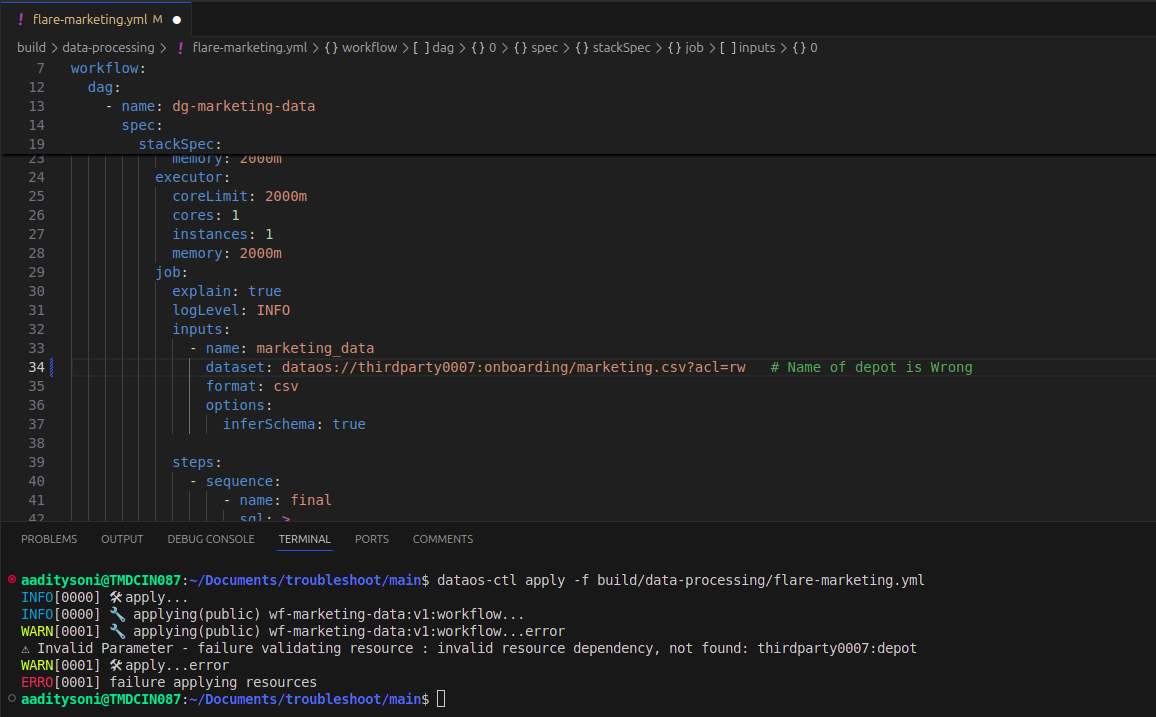
-
Problem: Incorrect Depot Path in Workflow
Issue: If an incorrect depot path is provided, the workflow does not generate an explicit error or warning but fails.
Solution:
- Check that the depot path is correct.
- Verify workflow success by checking the logs.
Error logs:
2025-02-05 13:39:30,412 INFO [main] org.elasticsearch.hadoop.util.Version: Elasticsearch Hadoop v8.13.4 [e636b381de] 2025-02-05 13:39:30,491 INFO [main] org.opensearch.hadoop.util.Version: OpenSearch Hadoop v1.2.0 [2a4148055f] 2025-02-05 13:39:30,765 ERROR [main] io.dataos.flare.Flare$: =>Flare: Job finished with error build version: 8.0.20; workspace name: public; workflow name: wf-marketing-data; workflow run id: ec5h44caa4n4; run as user: aadityasoni; job name: dg-marketing-data; org.apache.spark.sql.AnalysisException: [PATH_NOT_FOUND] Path does not exist: abfss://dropzone001@mockdataos.dfs.core.windows.net/large_dataset_20200511/onboarding001/marketing.csv. at org.apache.spark.sql.errors.QueryCompilationErrors$.dataPathNotExistError(QueryCompilationErrors.scala:1499) at org.apache.spark.sql.execution.datasources.DataSource$.$anonfun$checkAndGlobPathIfNecessary$4(DataSource.scala:757) at org.apache.spark.sql.execution.datasources.DataSource$.$anonfun$checkAndGlobPathIfNecessary$4$adapted(DataSource.scala:754) at org.apache.spa -
Missing Driver in Output Configuration
Issue: If the driver is not specified in the output configuration, the workflow fails.
Solution: Ensure the
driveris properly defined in the configuration.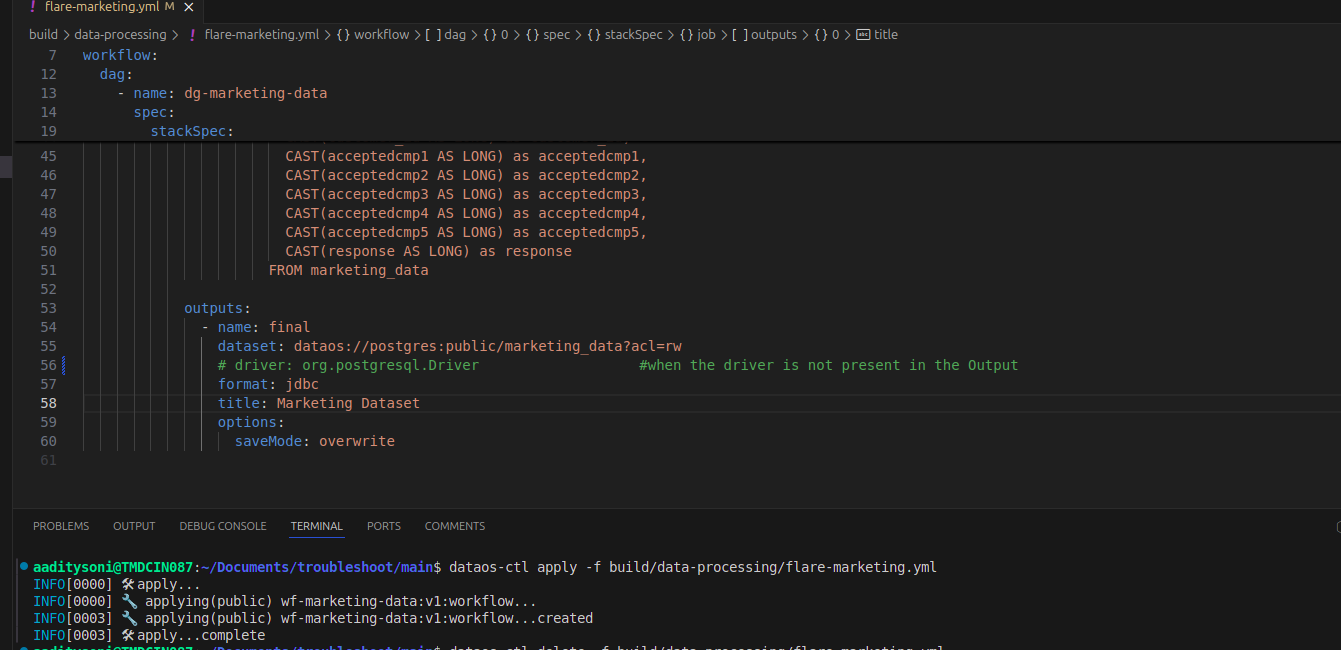
Error Log:
2025-02-05 10:52:53,640 INFO [main] io.dataos.flare.step.Step: calculating sequence final 2025-02-05 10:52:53,970 ERROR [main] io.dataos.flare.Flare$: =>Flare: Job finished with error build version: 8.0.20; workspace name: public; workflow name: wf-marketing-data; workflow run id: ec528v2hj01s; run as user: aadityasoni; job name: dg-marketing-data; java.lang.IllegalArgumentException: requirement failed: JDBCDatasourceOutput: `driver` must be defined at scala.Predef$.require(Predef.scala:281) at io.dataos.flare.configurations.job.output.datasource.JDBCDatasourceOutput.<init>(JDBCDatasourceOutput.scala:16) at io.dataos.flare.output.WriterFactory$.toJDBCDatasourceOutput(WriterFactory.scala:140) at io.dataos.flare.output.WriterFactory$.buildDatasourceOutput(WriterFactory.scala:74) at io.dataos.flare.output.WriterFactory$.getDatasetOutputWriter(WriterFactory.scala:42) -
Missing Driver in Input Configuration (PostgreSQL)
Issue: If the
driveris not provided in the input configuration, the workflow fails.Solution: Add the required
driverproperty in the dataset input options.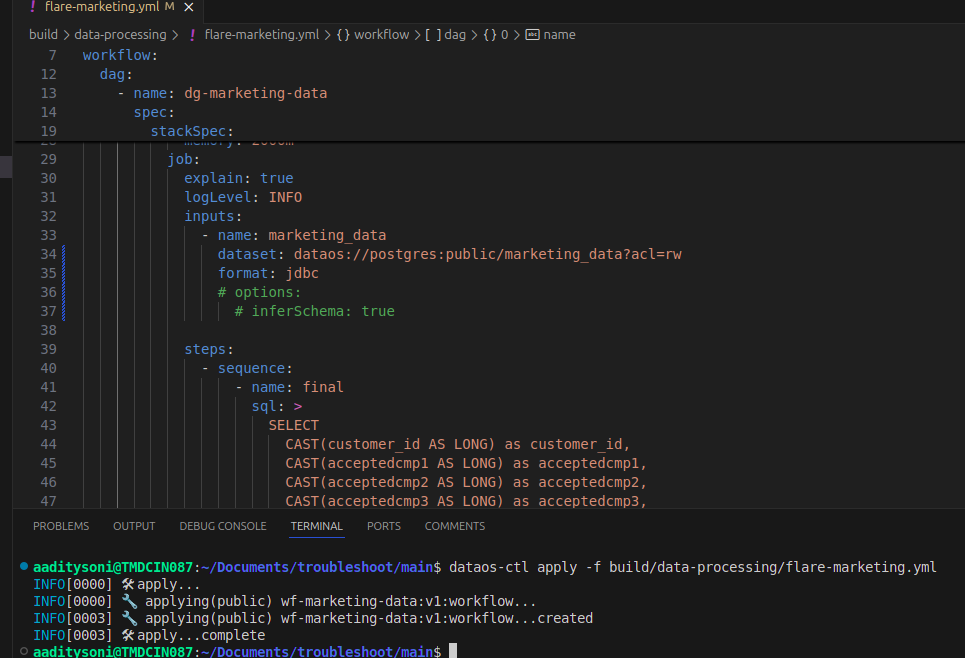
Error Log:
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1132) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala) Caused by: io.dataos.flare.exceptions.FlareException: please provide `driver` property in options for dataset name: marketing_data at io.dataos.flare.input.ReaderFactory$.buildJDBCDatasourceReader(ReaderFactory.scala:345) at io.dataos.flare.input.ReaderFactory$.buildJDBCInputDatasourceReader(ReaderFactory.scala:339) at io.dataos.flare.input.ReaderFactory$.getDatasetInputReader(ReaderFactory.scala:81) at io.dataos.flare.
Flare Transformation Error¶
Problem: "Cannot write incompatible data to table."
Cause: Data type mismatch
Solution:
- Cast the date/time column as a timestamp.
- Convert date/time column to timestamp.
Resource Allocation Errors¶
Problem: Insufficient resources leading to memory allocation errors.
Cause: The allocated memory for Driver and Executor is insufficient.
Solution: Increase memory allocation.
Streaming Errors¶
Problem: Job finished with error: "Checkpoint Location must be specified either through option ('checkpointlocation')."
Cause: Checkpoint location won't work if isstream is set to false.
Solution: Check the isstream mode and set it to true if needed.
Resource Naming Errors¶
Problem: Invalid Parameter - failure validating resource.
Cause: The DNS name of the workflow/service/job contains non-alphanumeric characters.
Solution: Ensure the DNS name conforms to the regex [a-z]([-a-z0-9]*[a-z0-9]).
Rules:
- Use only lowercase letters (a-z), digits (0-9), and hyphens (-).
- Hyphens cannot be at the start or end of the string.
- No uppercase letters or other special characters.
For Cluster & Depot names, only lowercase letters (a-z) and digits (0-9) are allowed.
Scanner Errors¶
-
Problem: ERROR 403 while running a job.
Solution: Run the job as
Metisuser (runAsUser: metis). -
Problem: PostgreSQL database metadata scan failure due to missing login access.
Solution: Ensure the user has both
CONNECTandSELECTprivileges.Check Privileges Query:¶
-
Problem: Scanner error due to invalid enumeration member or extra fields.
Cause: Mistyped property name in the YAML file.
Solution: Correct the property names in the scanner section of the YAML file.
-
Problem: Snowflake scanning error due to missing warehouse configuration.
Solution: Reach out to the DataOS administrator to update the Depot configuration YAML file with the correct warehouse name.
DP Access Errors¶
Problem: Missing ODBC drivers error while downloading the .pbip file to connect with Power BI.
Solution: Fix by adding a unique API key and using the correct username case.
Semantic Layer Related Errors¶
-
Problem: "Can't Find Join Path."
Cause: A query includes members from Lens that cannot be joined.
Solution: Verify that all necessary joins are defined correctly.
-
Problem: "Can't parse timestamp."
Cause: The data source cannot interpret the value of a time dimension as a valid timestamp.
Solution: Convert date and time to timestamp format.
-
Problem: "Primary key is required."
Cause: A Lens with joins has been defined without specifying a primary key.
Solution: Ensure that a primary key is set for any Lens that includes joins.