Implementing Quality Checks¶
Overview
Ensuring high data quality is critical for delivering trustworthy insights and supporting confident business decisions. As a Data Product developer, you’ll often face challenges like missing values, invalid formats, and inconsistent records. Proactively detecting and addressing these issues is key to building reliable Data Products.
With Soda Stack in DataOS, you can implement robust, flexible quality checks using Soda Checks Language (SodaCL). These checks validate key metrics such as accuracy, completeness, freshness, and uniqueness directly within your workflows.
For example, you can automate checks to ensure customer data integrity by verifying the absence of missing customer numbers and detecting duplicate phone records.
📘 Scenario¶
As a data engineer, you’re working with datasets and exploring them on Workbench and Metis. Before using this data to create a Data Product, you need to validate its quality. Your task is to set up quality checks that verify the data's accuracy, completeness, and consistency, ensuring it meets the necessary standards for consumer use.
Define service level objectives (SLOs)¶
Before you implement checks, define SLOs that reflect the quality expectations for your Data Product.
For example:
- Accuracy: 99% of data points must be accurate.
- Completeness: No more than 1% of records can have missing values.
- Freshness: Data must be updated within the last 24 hours.
- Schema: 100% of records must adhere to the expected schema.
- Uniqueness: 0.5% of records should be duplicated at maximum.
- Validity: 95% of records must meet all domain-specific rules.
Setting up data quality checks¶
With your SLOs in place, define the quality checks in YAML files (e.g., customer.yml, product.yml, purchase.yml). Use SodaCL syntax to build rule-based checks.
For example, if you’re defining quality checks for a 'customer' dataset, you can specify the following checks:
- Schema: The data type of birth year should be an integer.
- Accuracy: The average length of a country is more than 6.
- Completeness: Customer ID should not be zero.
- Validity: Customer ID should not be null.
- Uniqueness: Customer ID should be unique.
Quality checks will be implemented using the Soda framework, leveraging SodaCL—a YAML-based language—to define custom data quality checks for each dataset. The Soda Stack allows you to embed these rules directly into your workflow, enabling validation of key metrics such as accuracy, completeness, and uniqueness.
Configuring quality checks¶
Use Soda Stack within DataOS to establish robust data quality checks.
Step 1: Choose the right DataOS Resource¶
The type of DataOS Resource you choose for a Job depends on the specific use case.
-
Workflow Resource: Ideal for batch workloads and periodic quality checks.
-
Worker Resource: Best suited for long-running, continuous monitoring.
For this example, we use the Workflow Resource to run scheduled data quality checks on a customer dataset.
Step 2: Define the Soda Workflow manifest¶
Create a Workflow manifest to configure Soda Stack for batch quality checks. Ensure that the metadata and Stack properties are properly defined. You can schedule this workflow to run quality checks automatically at regular intervals.
# Important: Replace 'abc' with your initials to personalize and distinguish the resource you’ve created.
name: soda-customer-quality-abc
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Applying quality checks for the customer data
workspace: public
workflow:
# schedule:
# cron: '00 08 * * *'
# # endOn: '2023-12-12T22:00:00Z'
# concurrencyPolicy: Forbid
dag:
- name: soda-customer-quality
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO # WARNING, ERROR, DEBUG
Step 3: Declare the stackSpec section¶
Declaring input dataset address
The dataset attribute allows data developer to specify the data source or dataset that requires data quality evaluations. It is declared in the form of a Uniform Data Link [UDL], in the following format: dataos://[depot]:[collection]/[dataset].
Profile the dataset (Optional)
Enable profiling to gather insights into the dataset’s characteristics and data distribution. Specify the columns to be profiled in the manifest. Wildcard Matching: Use "*" to profile all columns in the dataset.
stackSpec:
inputs:
- dataset: dataos://postgresabc:public/customer_data
options:
engine: minerva
clusterName: miniature
profile:
columns:
- include *
Step 4: Define Soda checks¶
Tailor the checks to address issues identified by your team.
stackSpec:
inputs:
- dataset: dataos://postgresabc:public/customer_data
options:
engine: minerva
clusterName: miniature
profile:
columns:
- include *
checks:
- schema:
name: Data type of birth year should be integer
fail:
when wrong column type:
birth_year: bigint
attributes:
category: Schema
- freshness(created_at) < 7d:
name: If data is older than 7 days
attributes:
category: Freshness
- invalid_count(customer_id) = 1:
name: Customer Id should not be zero
valid min: 1
attributes:
category: Validity
- missing_count(customer_id) = 0:
name: Customer Id should not be zero
attributes:
category: Completeness
- duplicate_count(customer_id) = 0:
name: Customer Id should not be duplicated
attributes:
category: Uniqueness
- avg_length(country) > 2:
name: Average length of country more than 2
attributes:
category: Accuracy
Step 5: Apply the manifest¶
Once the manifest is complete, apply it using the DataOS CLI:
Click here to view the complete manifest file
# Important: Replace 'abc' with your initials to personalize and distinguish the resource you’ve created.
name: soda-customer-quality-abc
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Applying quality checks for the customer data
workspace: <workspace name> # Provide your workspace name
workflow:
dag:
- name: soda-customer-quality
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO
stackSpec:
inputs:
- dataset: dataos://postgresabc:public/customer_data
options:
engine: minerva
clusterName: miniature
profile:
columns:
- include *
checks:
- schema:
name: Data type of birth year should be integer
fail:
when wrong column type:
birth_year: bigint
attributes:
category: Schema
- freshness(created_at) < 7d:
name: If data is older than 7 days
attributes:
category: Freshness
- invalid_count(customer_id) = 1:
name: Customer ID should not be zero
attributes:
category: Validity
- missing_count(customer_id) = 0:
name: Customer ID should not be missing
attributes:
category: Completeness
- duplicate_count(customer_id) = 0:
name: Customer ID should not be duplicated
attributes:
category: Uniqueness
- avg_length(country) > 2:
name: Average length of country should be more than 2
attributes:
category: Accuracy
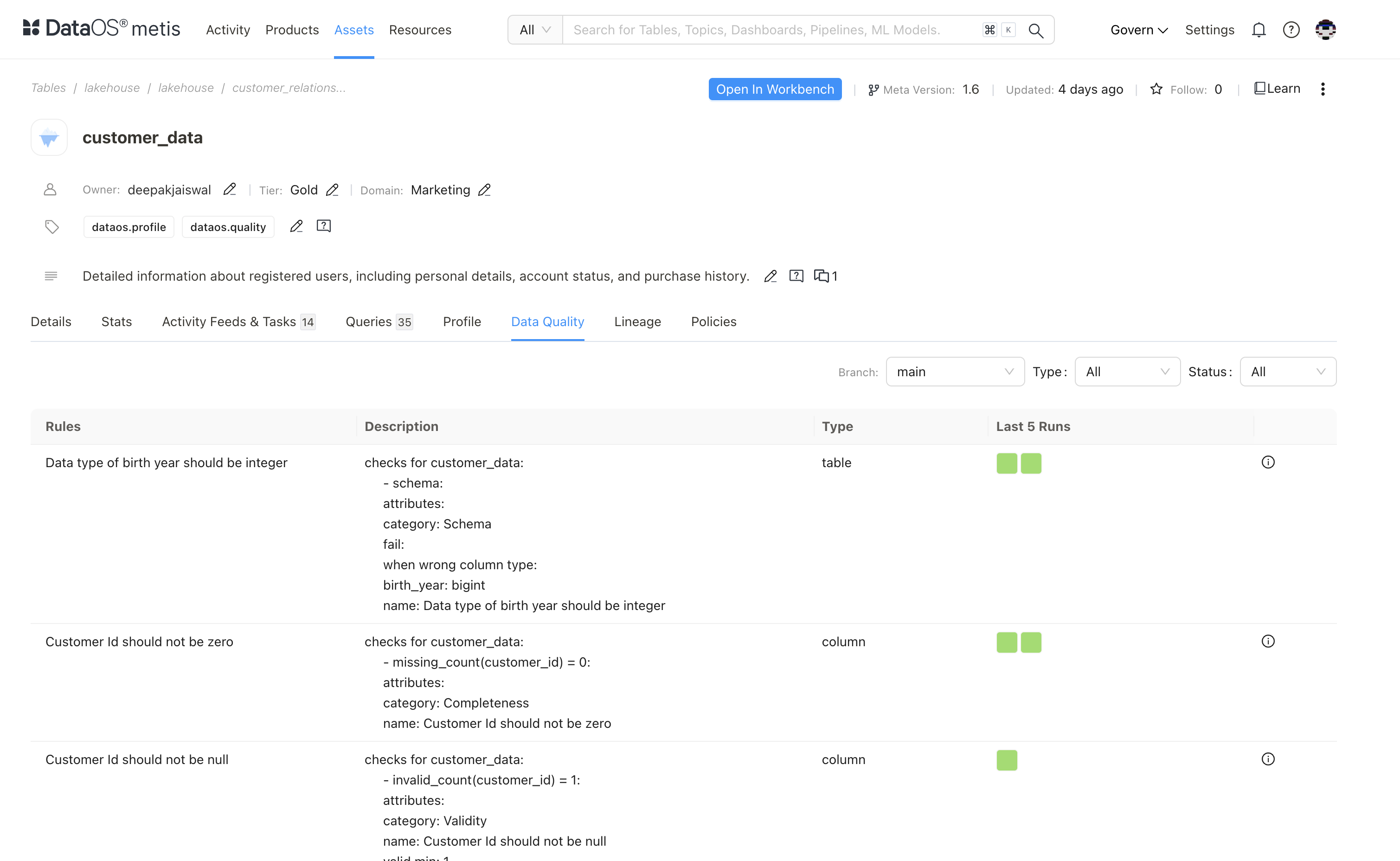
Monitoring results in Metis¶
Once these checks are applied, their results will be displayed on Metis. View results in the Metis app under the Datasets section.
Here, you can monitor the status of the quality checks and ensure they align with your analytical requirements. Each check is categorized as:
-
Accuracy: ✅ Passed, ❌ Failed.
-
Completeness: Alerts for missing values.
-
Uniqueness: ⚠️ Warnings for duplicate records.
Click on a specific check to view detailed trend charts, allowing you to analyze data quality metrics over time.
The quality checks displayed in Metis as defined in the Soda YAML manifest file, including their descriptions, as shown in the image below.
Hands-on exercise¶
Create a similar Soda Workflow for the product dataset.
Click here to view the complete manifest file for Product_data
# Important: Replace 'abc' with your initials to personalize and distinguish the resource you’ve created.
name: soda-product-quality-abc
version: v1
type: workflow
tags:
- workflow
- soda-checks
description: Applying quality checks for the product data
workspace: <workspace name> # Provide your workspace name
workflow:
dag:
- name: soda-product-quality
spec:
stack: soda+python:1.0
compute: runnable-default
resources:
requests:
cpu: 1000m
memory: 250Mi
limits:
cpu: 1000m
memory: 250Mi
logLevel: INFO
stackSpec:
inputs:
- dataset: dataos://postgresabc:public/product_data
options:
engine: minerva
clusterName: miniature
profile:
columns:
- include *
checks:
- schema:
name: Data type of price should be double
fail:
when wrong column type:
price: double
attributes:
category: Schema
- invalid_count(customer_id) = 1:
name: Customer ID should not be null
attributes:
category: Validity
- missing_count(product_id) = 0:
name: Product ID should not be zero
attributes:
category: Completeness
- duplicate_count(product_id) = 0:
name: Product ID should not be duplicated
attributes:
category: Uniqueness
- avg_length(product_name) > 4:
name: Average length of product name should be more than 4
attributes:
category: Accuracy
Next step¶
Set up proactive observability to monitor and alert on workflow or data quality issues.