DataOS Essentials¶
Overview
This topic introduces DataOS, a data product platform that transforms how organizations work with data. You will learn about its key components that enable technical and business users to turn raw data into powerful, governed, and production-ready data assets.
DataOS is an enterprise-grade data product platform for the development, management, processing, and deployment of Data Products across an organization. It provides the essential building blocks data developers require to create powerful data products that drive significant business outcomes.
Key benefits¶
DataOS empowers organizations to build faster, collaborate smarter, and scale confidently. It provides a modular, composable, and interoperable data infrastructure built on open standards, making it extensible and flexible for integration with existing tools and infrastructure.
-
Modularity: Facilitates flexible integration and scalability, allowing components to be independently developed, deployed, and managed.
-
Composability: Enables building complex data workflows from simple, reusable components.
-
Interoperability: Ensures seamless interaction with various data tools and platforms.
-
Governance and Security: Provides robust access controls and compliance features, ensuring data integrity and adherence to regulatory standards.
-
Self-Service Enablement: Empowers users, including data analysts and business stakeholders, to independently discover, access, and utilize data products through intuitive interfaces such as the Data Product Hub and Lens Studio. This reduces reliance on IT teams and accelerates time-to-insight.
Developing Data Products with DataOS¶
The development of a data product in DataOS follows a structured lifecycle:
-
Design: Define business goals and translate them into a solution architecture.
-
Develop: Build and test the data product based on the design.
-
Deploy: Release the product to users and ensure it operates effectively in a production environment.
-
Iterate: Continuously improve the product through feedback and performance analysis.
-
Deprecate: Gradually retire the data product when it is no longer needed, ensuring users are informed, dependencies are removed, and resources are cleaned up safely.
DataOS building blocks (Resources)¶
DataOS offers a rich set of building blocks, known as Resources, that enable the core capabilities of a modern data stack.
These Resources are organized by the key capabilities they support within DataOS, helping users understand how each contributes to building, managing, and consuming data products.
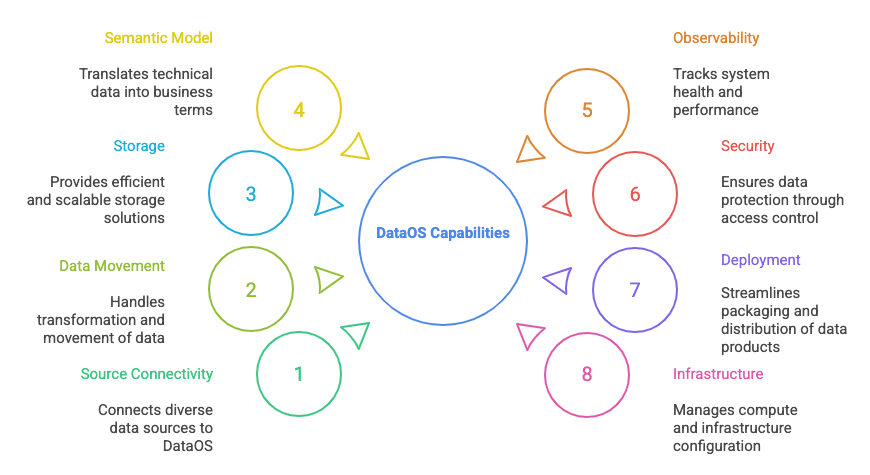
Source connectivity and metadata management¶
These resources connect to various data sources, enable metadata scanning, and support quality checks and data profiling.
-
Depot: Connects diverse data sources to DataOS, abstracting underlying complexities. Depots enable secure and consistent access to raw data while maintaining it in place, enhancing both efficiency and governance. Examples include Databases, warehouses, Object storages such as Postgres, Azure ABFSS, Amazon S3, Kafka, Snowflake, etc.
-
Stacks (e.g. Scanner): Act as execution engines supporting metadata exploration and data validation. They integrate new programming paradigms.
- Scanner: Stack designed for extracting metadata from external source systems and internal DataOS resources. It facilitates the discovery and understanding of data assets by collecting metadata such as schemas, column details, and data lineage. It supports metadata ingestion from databases, dashboards, messaging services, and more.
Data movement and processing¶
These resources handle the transformation and movement of data.
Batch data Resources¶
Support scheduled, large-scale data processing.
- Workflow: Manages batch data processing tasks with dependencies.
- Operator: Standardizes orchestration of external resources, enabling programmatic actions from DataOS.
- Stacks (e.g., Flare, DBT):
- Flare DataOS’s declarative engine built atop Apache Spark, designed for scalable batch, incremental and streaming data processing.
- Soda: Data quality validation Stack utilizing the Soda Checks Language (SodaCL), it allows users to define validation rules to monitor metrics like accuracy, completeness, and uniqueness for your data.
Streaming data Resources¶
Handle real-time processing and continuous ingestion.
- Workflow: Manages stream data tasks using micro-batching.
- Service: Long-running process that acts as an API receiver/provider.
- Worker: Long-running process that performs tasks continuously.
- Stacks (e.g., Flare, Bento): Key engines for streaming workflows.
- Bento: DataOS’s lightweight, stateless engine designed for real-time stream processing. It utilizes a declarative YAML-based configuration, enabling efficient data transformations such as mapping, validation, filtering, and enrichment. Bento is ideal for scenarios requiring low-latency processing, like IoT data ingestion or real-time analytics.
Storage¶
Resources for efficient, scalable storage solutions.
- Volume: Persistent shared storage for Pod containers.
- Lakehouse: Fully managed hybrid of data lake and warehouse for storing processed datasets.
- Database: Managed Postgres database used for transactional data.
- Stacks (e.g., Beacon): Execution engine for storage operations.
Semantic model¶
The semantic modeling layer that translates technical data into business-friendly terms.
- Lens: Empowers users to define and expose metrics, dimensions, and business logic, making data consumable for BI tools, APIs, or direct consumers.
Observability¶
Tracks system health and performance; enables proactive incident management.
- Monitor: observes performance, quality, and SLA compliance. For example, it detects workflow failures and tracks resource status for reliability and performance.
- Pager: Delivers alerts based on stream conditions (e.g., quality check failures or system incidents) to quickly address failures.
Security¶
Ensures data protection through access control and secure handling of credentials.
- Instance-Secret: Stores sensitive information securely at the instance level (e.g., database credentials).
- Secret: Stores credentials, certificates, or tokens securely within a workspace.
- Policy: uses Attribute-Based Access Control (ABAC).
- Access policy: To define and automatically enforce access rules across all channels (API, BI, queries, etc.).
- Data policy: To ensure sensitive data is securely accessed only by authorized users and remains compliant throughout the ecosystem.
- Grant: Maps Subject–Predicate–Object relationships to implement access control.
Deployment¶
Streamlines how data products and applications are packaged, distributed, and executed.
- Bundle: A declarative packaging mechanism for deploying and managing entire data product. Groups related components (e.g., workflows, models, scripts) into a single deployable unit—ensuring consistency, version control, and testability within CI/CD workflows.
- Stacks (e.g., Container, SteamPipe): Execution engines for deploying resources and applications.
Infrastructure Resources¶
Manage compute and infrastructure configuration to run data workloads effectively.
- Cluster: Provides compute environments and configuration for data engineering and analytics.
- Compute: Abstracts node pools of virtual machines, allocating processing power for workloads.
To learn more about all the Resources, refer to DataOS Resources
🧩 Assembling Data Products: A LEGO analogy¶
Building data products in DataOS is like constructing with LEGO bricks—each piece has a purpose, and when combined thoughtfully, they create something powerful and functional. Just as you wouldn’t build a LEGO castle with only one type of brick, you can’t build an effective data product with a single resource. DataOS offers a rich set of modular components that come together to solve complex business problems through well-structured, reusable data products.
How does DataOS support different user roles?¶
-
Data Product Consumer: Discovers, explores, and utilises data products, including integration with BI tools, AI/ML, and data APIs.
-
Data Product Developer: Builds and maintains data products end-to-end. Focuses on translating business goals into data products by designing, sourcing, building pipelines, ensuring quality, modeling semantics, and deploying solutions.
-
DataOS Operator: Oversees credential security, data source connectivity, routine checks, upgrade strategies, configuring alerts, and cluster management.
-
Data Product Owner: Aligns product development with business goals, sets success metrics and priorities defineing the strategic vision for data products.
Trusted & observable by design¶
-
Governance and Security DataOS includes built-in controls to ensure data confidentiality, integrity, and compliance. Through robust access policies, encryption, and automated enforcement, it protects sensitive information across all access channels.
-
Observability DataOS continuously monitors the health and performance of data products. Key metrics like availability, latency, and throughput are tracked in real time, with automated alerts helping teams detect and resolve issues proactively.
Together, governance, security, and observability form the backbone of DataOS’s enterprise-grade reliability. These capabilities aren’t optional add-ons—they’re integral to the platform. This ensures every data product is secure, compliant, and resilient by design, empowering teams to scale operations confidently with trust and control.