Create customer 360 using Standalone 1.0¶
Now it's time for you to solve a Customer 360 on your own with a set of guided instructions. This section will help you to develop a better understanding of Flare standalone capabilities giving you a hands-on experience.
After you have successfully installed Flare and run the sample workflow, you are ready to dive into the assignment and achieve a Customer 360 with guided steps. If you don’t know how to get the Flare Standalone running, navigate to the below link
A Customer 360 can be understood as an ‘insight’ a company discovers about its customers after integrating disparate datasets and loading them into one table. This helps in churning data-driven business decisions.
The following use case aims to empower a business analyst with accurate data helping him create a flawless Customer 360 using the commands discussed in this document.
Problem Statement¶
For instance, a Marketing Manager (MM) wishes to run a campaign for a targeted group of customers whose buying patterns and related details can be abstracted from Customer 360. For this campaign, the MM needs the following information:
- The average order value is more than $20.
- The total order count is more than 10.
- The total order value is more than $50.
Desired Output¶
In this case, you have to prepare Customer 360 data by aggregating data from the various datasets using Flare Standalone. Then, you can use this Customer 360 data in multiple scenarios.
A complete step-by-step run-through with the defined problem statement and the user journey to the desired output.
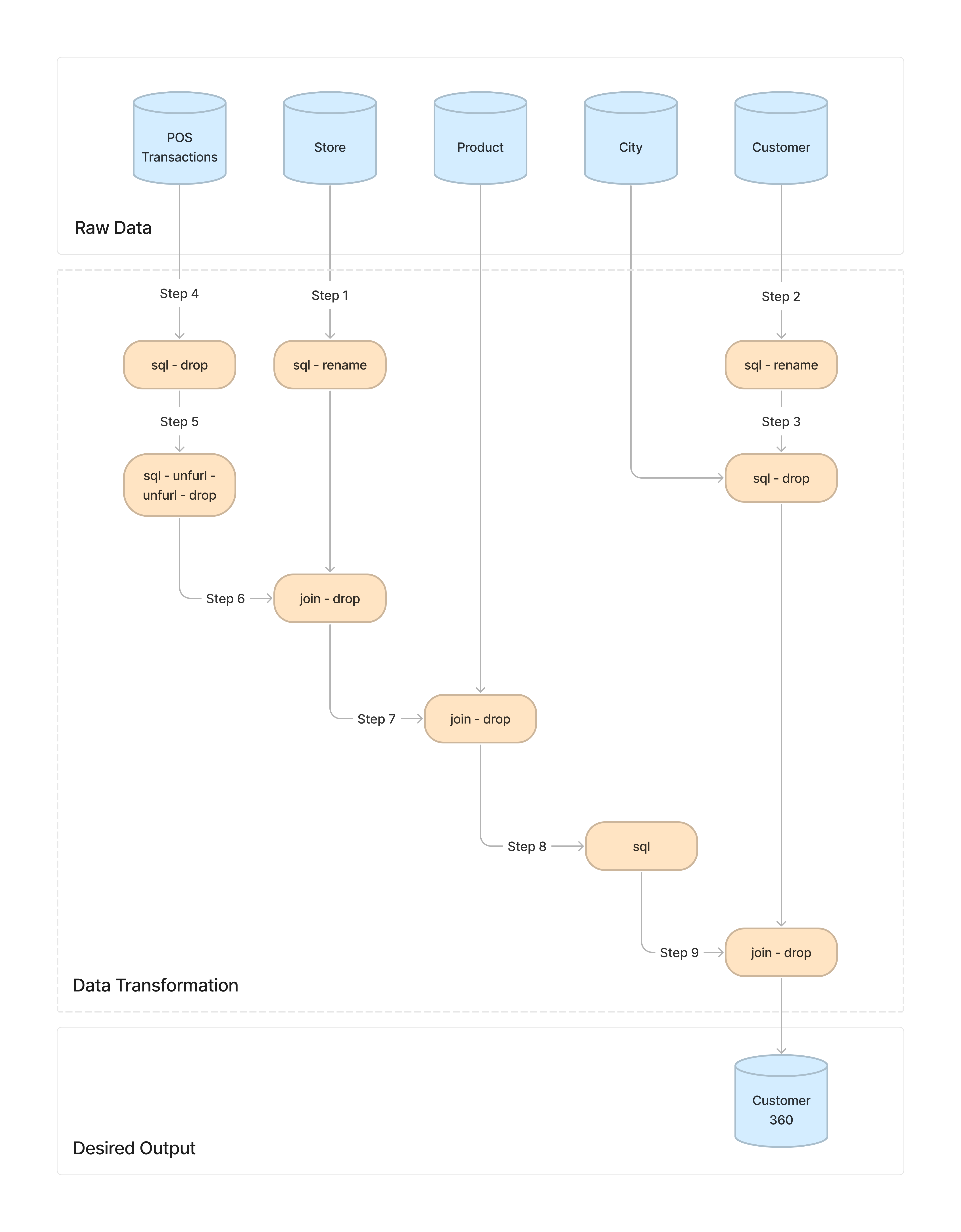
Steps to Perform¶
This tutorial helps you perform the steps you need to transform the given data into the Customer 360 data using Flare standalone capabilities.
Download Resources¶
- Download the
assignment.zipgiven below
-
Extract the assignment zip file. This file contains the following:
flareconfigfolder withconfig.yaml.datafolder containing sample data files.config_template.yamlfile for your hands-on with Flare standalone capabilities.config_solution.yamlfile containing complete queries for transformations.
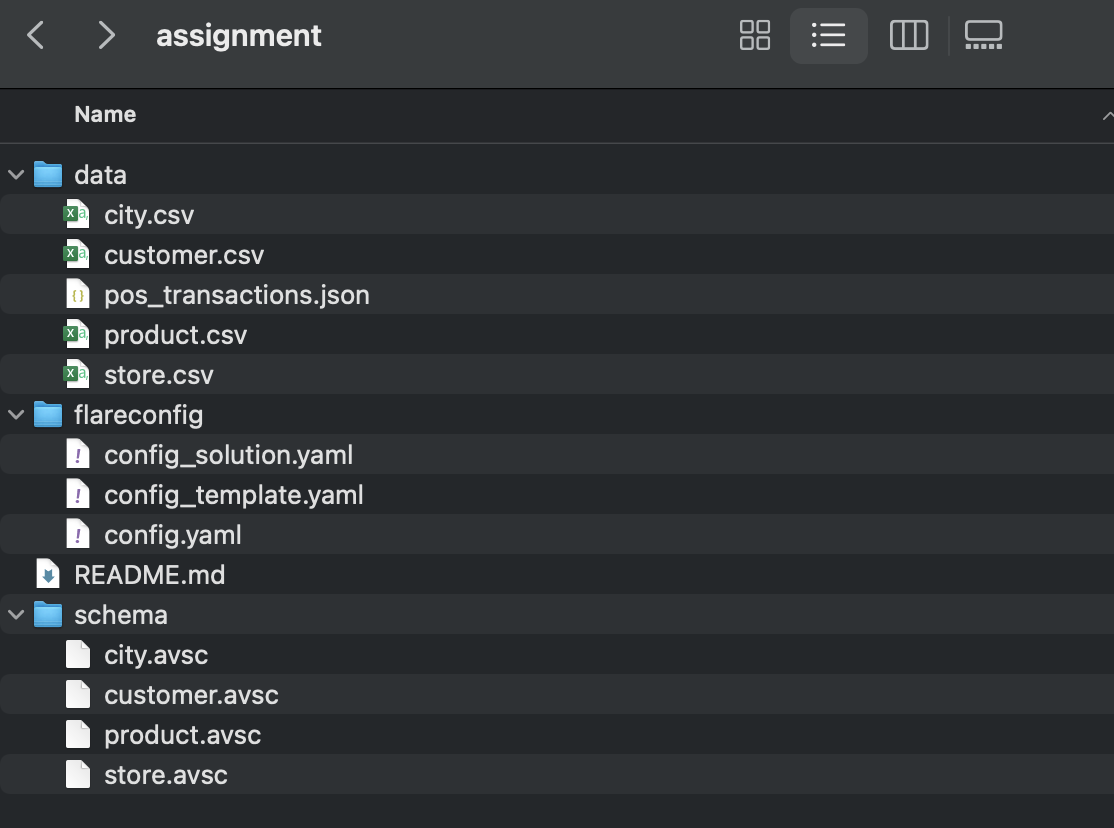
assignment data folder
Create Datasets¶
The inputs section of the config.yaml contains the input files.
inputs: # data sources to read from
- name: input_cities
format: csv # data format
dataset: /datadir/data/city.csv **# city data**
schemaPath: /datadir/schema/city.avsc # city Schema
- name: products
format: csv
dataset: /datadir/data/product.csv. **# product data**
schemaPath: /datadir/schema/product.avsc
- name: input_stores
format: csv
dataset: /datadir/data/store.csv **# store data**
schemaPath: /datadir/schema/store.avsc
- name: input_transactions
format: json
dataset: /datadir/data/pos_transactions.json. **# transactions data**
- name: input_customer
format: csv
dataset: /datadir/data/customer.csv. **# customer data**
schemaPath: /datadir/schema/customer.avsc
When you run this config file, data will be ingested, and datasets will be created in Flare standalone for the Customer 360 use case.
Follow the steps given below:
- Open the terminal and navigate to the directory where use case data and configuration .yaml are present.
- You can use the below command to run the
config.yaml.
Following any error, if you are not able to run the above command, kindly run the below command.
docker run --rm -it \
-v $PWD/flareconfig:/etc/standalone \
-v $PWD:/datadir \
-v $PWD/dataout:/dataout \
-e DATAOS_WORKSPACE=public \
-e DATAOS_RUN_AS_USER=tmdc \
rubiklabs/flare2:5.9.2 start
Expected Output
docker run --rm -it \
-v $PWD/flareconfig:/etc/standalone \
-v $PWD:/datadir \
-v $PWD/dataout:/dataout \
-e DATAOS_WORKSPACE=public \
-e DATAOS_RUN_AS_USER=tmdc \
rubiklabs/flare2:5.9.2 start
++ id -u
+ myuid=0
++ id -g
+ mygid=0
+ set +e
++ getent passwd 0
+ uidentry=root:x:0:0:root:/root:/bin/bash
+ set -e
+ '[' -z root:x:0:0:root:/root:/bin/bash ']'
+ SPARK_CLASSPATH=':/opt/spark/jars/*'
+ env
+ grep SPARK_JAVA_OPT_
+ sort -t_ -k4 -n
+ sed 's/[^=]*=\(.*\)/\1/g'
+ readarray -t SPARK_EXECUTOR_JAVA_OPTS
+ '[' -n '' ']'
+ '[' -z ']'
+ '[' -z ']'
+ '[' -n '' ']'
+ '[' -z ']'
+ '[' -z ']'
+ '[' -z x ']'
+ SPARK_CLASSPATH='/opt/spark/conf::/opt/spark/jars/*'
+ case "$1" in
+ echo 'Non-spark-on-k8s command provided, proceeding in pass-through mode...'
Non-spark-on-k8s command provided, proceeding in pass-through mode...
+ CMD=("$@")
+ exec /usr/bin/tini -s -- start
2022-11-07 07:22:29,886 INFO [main] o.a.spark.util.SignalUtils: Registering signal handler for INT
2022-11-07 07:22:34,520 INFO [main] o.a.h.hive.conf.HiveConf: Found configuration file null
2022-11-07 07:22:34,614 INFO [main] o.a.spark.SparkContext: Running Spark version 3.2.1
2022-11-07 07:22:34,678 WARN [main] o.a.h.u.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2022-11-07 07:22:34,760 INFO [main] o.a.s.r.ResourceUtils: ==============================================================
2022-11-07 07:22:34,760 INFO [main] o.a.s.r.ResourceUtils: No custom resources configured for spark.driver.
2022-11-07 07:22:34,760 INFO [main] o.a.s.r.ResourceUtils: ==============================================================
2022-11-07 07:22:34,761 INFO [main] o.a.spark.SparkContext: Submitted application: Spark shell
2022-11-07 07:22:34,777 INFO [main] o.a.s.r.ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
2022-11-07 07:22:34,784 INFO [main] o.a.s.r.ResourceProfile: Limiting resource is cpu
2022-11-07 07:22:34,785 INFO [main] o.a.s.r.ResourceProfileManager: Added ResourceProfile id: 0
2022-11-07 07:22:34,831 INFO [main] o.a.spark.SecurityManager: Changing view acls to: root
2022-11-07 07:22:34,831 INFO [main] o.a.spark.SecurityManager: Changing modify acls to: root
2022-11-07 07:22:34,831 INFO [main] o.a.spark.SecurityManager: Changing view acls groups to:
2022-11-07 07:22:34,832 INFO [main] o.a.spark.SecurityManager: Changing modify acls groups to:
2022-11-07 07:22:34,832 INFO [main] o.a.spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
2022-11-07 07:22:35,031 INFO [main] o.apache.spark.util.Utils: Successfully started service 'sparkDriver' on port 46431.
2022-11-07 07:22:35,052 INFO [main] org.apache.spark.SparkEnv: Registering MapOutputTracker
2022-11-07 07:22:35,071 INFO [main] org.apache.spark.SparkEnv: Registering BlockManagerMaster
2022-11-07 07:22:35,089 INFO [main] o.a.s.s.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2022-11-07 07:22:35,089 INFO [main] o.a.s.s.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
2022-11-07 07:22:35,093 INFO [main] org.apache.spark.SparkEnv: Registering BlockManagerMasterHeartbeat
2022-11-07 07:22:35,113 INFO [main] o.a.s.s.DiskBlockManager: Created local directory at /tmp/blockmgr-7d9d5baa-3f20-4d8c-8fdc-75536c47b503
2022-11-07 07:22:35,130 INFO [main] o.a.s.s.memory.MemoryStore: MemoryStore started with capacity 366.3 MiB
2022-11-07 07:22:35,143 INFO [main] org.apache.spark.SparkEnv: Registering OutputCommitCoordinator
2022-11-07 07:22:35,216 INFO [main] o.s.jetty.util.log: Logging initialized @6438ms to org.sparkproject.jetty.util.log.Slf4jLog
2022-11-07 07:22:35,277 INFO [main] o.s.jetty.server.Server: jetty-9.4.43.v20210629; built: 2021-06-30T11:07:22.254Z; git: 526006ecfa3af7f1a27ef3a288e2bef7ea9dd7e8; jvm 1.8.0_262-b19
2022-11-07 07:22:35,298 INFO [main] o.s.jetty.server.Server: Started @6522ms
2022-11-07 07:22:35,330 INFO [main] o.s.j.s.AbstractConnector: Started ServerConnector@6eb5b9e7{HTTP/1.1, (http/1.1)}{0.0.0.0:4040}
2022-11-07 07:22:35,330 INFO [main] o.apache.spark.util.Utils: Successfully started service 'SparkUI' on port 4040.
2022-11-07 07:22:35,357 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@1791e231{/jobs,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,360 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@4c02899{/jobs/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,361 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@74231642{/jobs/job,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,362 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@5e055ce1{/jobs/job/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,362 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@545f0b6{/stages,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,363 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@4888425d{/stages/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,363 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@166ddfb7{/stages/stage,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,365 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@291cbe70{/stages/stage/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,365 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@225ddf5f{/stages/pool,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,366 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@1d654b5f{/stages/pool/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,367 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@1b36d248{/storage,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,367 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@499c4d61{/storage/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,368 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@59b3f754{/storage/rdd,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,368 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@2a510e0e{/storage/rdd/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,369 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@4efe014f{/environment,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,369 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@7c5ac0{/environment/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,370 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@3cf70afa{/executors,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,371 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@495e8a3{/executors/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,371 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@6eded11a{/executors/threadDump,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,375 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@4b511e61{/executors/threadDump/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,386 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@6c6919ff{/static,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,387 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@2759749{/,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,388 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@4ac0ed65{/api,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,389 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@3856d0cb{/jobs/job/kill,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,390 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@d190639{/stages/stage/kill,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,392 INFO [main] o.apache.spark.ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://af3584e5001f:4040
2022-11-07 07:22:35,527 INFO [main] o.a.s.executor.Executor: Starting executor ID driver on host af3584e5001f
2022-11-07 07:22:35,534 INFO [main] o.a.s.executor.Executor: Using REPL class URI: spark://af3584e5001f:46431/classes
2022-11-07 07:22:35,552 INFO [main] o.apache.spark.util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 43721.
2022-11-07 07:22:35,552 INFO [main] o.a.s.n.n.NettyBlockTransferService: Server created on af3584e5001f:43721
2022-11-07 07:22:35,554 INFO [main] o.a.s.storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2022-11-07 07:22:35,560 INFO [main] o.a.s.s.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, af3584e5001f, 43721, None)
2022-11-07 07:22:35,563 INFO [dispatcher-BlockManagerMaster] o.a.s.s.BlockManagerMasterEndpoint: Registering block manager af3584e5001f:43721 with 366.3 MiB RAM, BlockManagerId(driver, af3584e5001f, 43721, None)
2022-11-07 07:22:35,566 INFO [main] o.a.s.s.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, af3584e5001f, 43721, None)
2022-11-07 07:22:35,567 INFO [main] o.a.s.storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, af3584e5001f, 43721, None)
2022-11-07 07:22:35,692 INFO [main] o.s.j.s.h.ContextHandler: Started o.s.j.s.ServletContextHandler@69c227fd{/metrics/json,null,AVAILABLE,@Spark}
2022-11-07 07:22:35,769 INFO [main] org.apache.spark.repl.Main: Created Spark session with Hive support
Spark context Web UI available at http://af3584e5001f:4040
Spark context available as 'sc' (master = local[*], app id = local-1667805755451).
Spark session available as 'spark'.
Flare session is available as flare.
Welcome to
______ _
| ____| | |
| |__ | | __ _ _ __ ___
| __| | | / _` | | '__| / _ \
| | | | | (_| | | | | __/
|_| |_| \__,_| |_| \___| version 1.1.0
Powered by Apache Spark 3.2.1
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_262)
Type in expressions to have them evaluated.
Type :help for more information.
Note: Refer to the additional flag for your docker command if you are using an M1 Mac machine.
The Scala interactive shell appears. The Flare workflow in the config.yaml creates the datasets from the given input files.
- You can run the
tables**command in Scala interactive shell to check the created tables.
scala> tables
# Expected Output
+---------+------------------+-----------+
|namespace|tableName |isTemporary|
+---------+------------------+-----------+
| |input_cities |true |
| |input_customer |true |
| |input_stores |true |
| |input_transactions|true |
| |products |true |
| |stores |true |
+---------+------------------+-----------+
Apply Transformations¶
To create Customer 360 data, you must apply a series of transformations. First, place the SQL statements and column names with the help of the given instructions.
Note: Under the flareconfig folder, open the
config_template.yaml. In the ‘sequence’ section, you must fill in the SQL commands and column names wherever placeholders are given.
- Select all columns from the
input_storesdata frame and rename thestore_idcolumn tos_id. Here you will use the Flare function ‘rename_all’ This snippet shows how you can apply the Flare functions by providing the function name and required columns that will be passed as parameters to the process. The Flare function is used after the SQL query is executed.
The query result is saved as a data frame with the name provided, ‘stores’ in this example.
- name: stores
doc: select all columns from input_stores data frame, and rename store_id column to s_id
sql: select * from input_stores # select all columns form input_stores, replace {SQL_statement} with sql statement
functions:
- name: rename_all # this function renames a column
columns:
store_id: s_id
You can run the SQL query on the Scala prompt to check the transformation. In the following image, you can see the renamed column
s_id.
Expected Output
+--------+--------------------+--------------------+-------------+-------------+--------------+----------------+-----------+-------------+
|store_id| store_name| store_address|store_zipcode| store_city| store_county|store_state_code|store_state|store_country|
+--------+--------------------+--------------------+-------------+-------------+--------------+----------------+-----------+-------------+
| 1|Modern Company, V...|315 Candlestick P...| 36091| Verbena|Autauga County| AL| Alabama| US|
| 2|Modern Company, P...| 751 Burnett Gardens| 36758|Plantersville|Autauga County| AL| Alabama| US|
| 3|Modern Company, B...|1041 Hollywood St...| 36006| Billingsley|Autauga County| AL| Alabama| US|
| 4|Modern Company, P...| 1216 Topaz Bend| 36067| Prattville|Autauga County| AL| Alabama| US|
| 5|Modern Company, S...| 850 Habitat Path| 36701| Selma|Autauga County| AL| Alabama| US|
+--------+--------------------+--------------------+-------------+-------------+--------------+----------------+-----------+-------------+
only showing top 5 rows
- name: customers
doc: Select all columns from the input_customer data frame and rename customer_index to cust_index
sql: {SQL_statement} # select all columns from input_customer, replace {SQL_statement} with sql statement
functions:
- name: rename_all
columns:
{old_column_name}: {new_column_name} #Replace {old_column_name} and {new_column_name} eg: customer_index: cust_ind ex
scala> spark.sql("select * from customers").show(5)
# Expected Output
+----------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+
|cust_index| Id|salutation|first_name|last_name|gender| phone_number| email_id| birthdate|age| education_level| marital_status|number_of_children| occupation|annual_income| employment_status| hobbies|home_ownership|degree_of_loyalty|benefits_sought| personality| user_status| social_class|lifestyle|customer_city_id| mailing_street|
+----------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+
| 1|fa472f08-16a8-cd8...| Mrs.| Tatum| Norton|FEMALE| 895.368.6078|rushland2027@live...|1987-05-04| 33| Associate's Degree| Divorced| 4|Choreographer| $35k-$50k|Employed Part-Time| Juggling| own| Switchers| Functionality| Easygoing| Potential Users| Middle Class| Explorer| CITY36885| 511 Recycle Run|
| 2|8b5ce542-270c-4d1...| B.E.| Hyman| Riley| MALE| 1-493-661-9142|boutade2068@gmail...|1969-05-01| 51|Postgraduate Degree|Domestic Partner| 5| Fruiterer| $150k-$200k| Self-Employed|Handicraft| own| Switchers| Functionality|Determined and Am...|First-Time Users| Middle Class|Succeeder| CITY29232| 703 Leese Townline|
| 3|3525d90e-8a7c-6e1...| Ms.| Robbyn| Blair|FEMALE|+1-(543)-288-7392|differences1851@l...|1993-03-17| 27| Associate's Degree| Unknown| 4| Polisher| <$15k|Seeking Employment| Excercise| own| Hard Core Loyals| Cost Advantage|Determined and Am...| Potential Users|Working Class| Reformer| CITY10442| 83 Northwood Trace|
| 4|89df6007-9a82-4b6...| Miss| Tracy| Webster| OTHER| (738) 757-4620|whitier2026@proto...|1991-11-23| 28|High School Diploma| Separated| 1| Rent Offcer| $150k-$200k|Employed Full-Time| Cycling| own| Soft Core Loyals| Cost Advantage| Easygoing| Ex-Users| Middle Class| Explorer| CITY9608| 369 Royal Crescent|
| 5|09773ce4-d931-74c...| Mr.| Claud| Mcneil| MALE| 792.521.1724|alligators1863@pr...|1977-02-05| 43| Graduate Degree| Unknown| 5| Childminder| $25k-$35k| Self-Employed| Writing| rent| Switchers|Self-Expression|Determined and Am...| Non-Users|Working Class| Reformer| CITY45320|792 De Forest Gar...|
+----------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+
only showing top 5 rows
- Add city information to
customersdata frame and drop thecity_idcolumn. Use the ‘drop’ function. As we have performed the ‘join’ operation, there would be city columns from both the data frames so one can be dropped.
- name: customer_city
doc: Add city information to customers data frame and drop the city_id column.
sql: select * from customers left join input_cities on customers.customer_city_id = input_cities.city_id
functions:
- name: drop # this function drop columns a column
columns:
- city_id # Columns to drop
Expected Output
+----------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+--------+---------+----------------+----------+-------------+
|cust_index| Id|salutation|first_name|last_name|gender| phone_number| email_id| birthdate|age| education_level| marital_status|number_of_children| occupation|annual_income| employment_status| hobbies|home_ownership|degree_of_loyalty|benefits_sought| personality| user_status| social_class|lifestyle|customer_city_id| mailing_street|zip_code|city_name| county_name|state_code| state_name|
+----------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+--------+---------+----------------+----------+-------------+
| 1|fa472f08-16a8-cd8...| Mrs.| Tatum| Norton|FEMALE| 895.368.6078|rushland2027@live...|1987-05-04| 33| Associate's Degree| Divorced| 4|Choreographer| $35k-$50k|Employed Part-Time| Juggling| own| Switchers| Functionality| Easygoing| Potential Users| Middle Class| Explorer| CITY36885| 511 Recycle Run| 45853| Kalida| Putnam County| OH| Ohio|
| 2|8b5ce542-270c-4d1...| B.E.| Hyman| Riley| MALE| 1-493-661-9142|boutade2068@gmail...|1969-05-01| 51|Postgraduate Degree|Domestic Partner| 5| Fruiterer| $150k-$200k| Self-Employed|Handicraft| own| Switchers| Functionality|Determined and Am...|First-Time Users| Middle Class|Succeeder| CITY29232| 703 Leese Townline| 3233| Elkins|Merrimack County| NH|New Hampshire|
| 3|3525d90e-8a7c-6e1...| Ms.| Robbyn| Blair|FEMALE|+1-(543)-288-7392|differences1851@l...|1993-03-17| 27| Associate's Degree| Unknown| 4| Polisher| <$15k|Seeking Employment| Excercise| own| Hard Core Loyals| Cost Advantage|Determined and Am...| Potential Users|Working Class| Reformer| CITY10442| 83 Northwood Trace| 83338| Jerome| Gooding County| ID| Idaho|
| 4|89df6007-9a82-4b6...| Miss| Tracy| Webster| OTHER| (738) 757-4620|whitier2026@proto...|1991-11-23| 28|High School Diploma| Separated| 1| Rent Offcer| $150k-$200k|Employed Full-Time| Cycling| own| Soft Core Loyals| Cost Advantage| Easygoing| Ex-Users| Middle Class| Explorer| CITY9608| 369 Royal Crescent| 39837| Colquitt| Miller County| GA| Georgia|
| 5|09773ce4-d931-74c...| Mr.| Claud| Mcneil| MALE| 792.521.1724|alligators1863@pr...|1977-02-05| 43| Graduate Degree| Unknown| 5| Childminder| $25k-$35k| Self-Employed| Writing| rent| Switchers|Self-Expression|Determined and Am...| Non-Users|Working Class| Reformer| CITY45320|792 De Forest Gar...| 76524| Eddy| Falls County| TX| Texas|
+----------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+--------+---------+----------------+----------+-------------+
only showing top 5 rows
- Use the Spark SQL function ‘Explode’ for the
transaction_line_itemcolumn in theinput_transactionstable asline_itemsto extract the line item information. This column contains JSON array objects.
scala> spark.sql("select customer_index, transaction_line_item from input_transactions").show(5)
# Expected Output
+--------------+---------------------+
|customer_index|transaction_line_item|
+--------------+---------------------+
| 1971| [{580, null, null...|
| 1516| [{297, null, null...|
| 1374| [{279, null, null...|
| 1165| [{837, null, null...|
| 1747| [{891, null, null...|
+--------------+---------------------+
only showing top 5 rows
- Explode function create the rows for each array item in a new column. After running this transformation, you will have a new column renamed
line_itemso you can apply the ‘drop’ command for the original column with the JSON array object.
- name: transaction_explode_lineitem
doc: Use the Spark SQL function '**Explode'** for the transaction_line_item column in the input_transactions table as line_items to extract the line item information.
sql: {SQL_statement} # replace {SQL_statement} with sql statement
functions:
- name: drop
columns:
- {column_to_drop} # replace this with column name
scala> spark.sql("select * from transaction_explode_lineitem").show(5)
# Expected Output
+--------------+--------------------+---------+--------------------+--------------------+--------------------+
|customer_index| discount| tax| tender| transaction_header| line_items|
+--------------+--------------------+---------+--------------------+--------------------+--------------------+
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...|{27626, 2019-10-0...|{580, null, null,...|
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...|{27626, 2019-10-0...|{648, null, null,...|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...|{06112, 2020-05-1...|{297, null, null,...|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...|{06112, 2020-05-1...|{279, null, null,...|
| 1374|[{null, null, 1, ...|{88, 5.7}|[{null, 1624, 1, ...|{33237, 2020-10-1...|{279, null, null,...|
+--------------+--------------------+---------+--------------------+--------------------+--------------------+
only showing top 5 rows
- The following snippet shows how you can extract columns from
line_itemsandtransaction_headernested JSON attribute columns in thetransaction_explode_lineitemdata frame. Drop both columns from the data frame. Here ‘unfurl’ function will help you to extract all the columns present in the line_items and transaction_header. You can drop multiple columns using the ‘drop’ function. You will get theflatten_transactiondata frame. to pull columns from within the nested json attribute
Note: You can run the SQL command
tableson the Scala prompt to check the created data frames.
- name: flatten_transaction
doc: Extract all columns from line_items and transaction_header columns from transaction_explode_lineitem and drop both columns from the new data frame.
sql: select * from transaction_explode_lineitem
functions:
- name: unfurl # function to extract columns
expression: "line_items.*". # to extract all values, mention *
- name: unfurl
expression: "transaction_header.*"
- name: drop
columns: # multiple columns can be dropped
- line_items
- transaction_header
Expected Output
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+
|customer_index| discount| tax| tender|line_item_extended_amount|line_item_original_sequence_number|line_item_original_timestamp|line_item_original_transaction_id|line_item_product_id|line_item_quantity|line_item_return_flag|line_item_sale_amount|line_item_sequence_number|store_id| timestamp|total_sales_amount|transaction_id|
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...| 580| null| null| null| SKU1365| 2| N| 580| 1| 27626|2019-10-04 01:04:...| 1298| 10000000001|
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...| 648| null| null| null| SKU5268| 2| N| 648| 2| 27626|2019-10-04 01:04:...| 1298| 10000000001|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...| 297| null| null| null| SKU3108| 1| N| 252| 1| 06112|2020-05-19 20:29:...| 561| 10000000002|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...| 279| null| null| null| SKU1736| 1| N| 279| 2| 06112|2020-05-19 20:29:...| 561| 10000000002|
| 1374|[{null, null, 1, ...|{88, 5.7}|[{null, 1624, 1, ...| 279| null| null| null| SKU577| 1| N| 279| 1| 33237|2020-10-12 02:50:...| 1624| 10000000003|
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+
only showing top 5 rows
- Join
storesdata with theflatten_transactiondata frame created in the last operation and ‘drop’ thes_idcolumn. This code snippet shows you a way to perform SQL join operations in a declarative way. You must provide the join type, join expression, and input data frames. Make sure to provide the appropriate values for the placeholders.
- name: store_flatten_transaction
doc: Join stores data with the flatten_transaction data frame created in the last operation and ‘**drop**’ the s_id column.
classpath: io.dataos.flare.step.codes.Joiner # flare declarative way of performing join
params:
join: LEFT
inputs: "flatten_transaction, stores" # left and right dataframe
joinExpr: "flatten_transaction.store_id=stores.s_id" # join expression
functions:
- name: {function_name} # drop function name
columns:
- {column_to_drop} # replace this with column name
Expected Output
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+--------------------+--------------------+-------------+----------+---------------+----------------+--------------+-------------+
|customer_index| discount| tax| tender|line_item_extended_amount|line_item_original_sequence_number|line_item_original_timestamp|line_item_original_transaction_id|line_item_product_id|line_item_quantity|line_item_return_flag|line_item_sale_amount|line_item_sequence_number|store_id| timestamp|total_sales_amount|transaction_id| store_name| store_address|store_zipcode|store_city| store_county|store_state_code| store_state|store_country|
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+--------------------+--------------------+-------------+----------+---------------+----------------+--------------+-------------+
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...| 580| null| null| null| SKU1365| 2| N| 580| 1| 27626|2019-10-04 01:04:...| 1298| 10000000001|Modern Company, C...|648 Mabini Boulevard| 59217| Crane|Richland County| MT| Montana| US|
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...| 648| null| null| null| SKU5268| 2| N| 648| 2| 27626|2019-10-04 01:04:...| 1298| 10000000001|Modern Company, C...|648 Mabini Boulevard| 59217| Crane|Richland County| MT| Montana| US|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...| 297| null| null| null| SKU3108| 1| N| 252| 1| 06112|2020-05-19 20:29:...| 561| 10000000002|Modern Company, M...|561 Frank Norris ...| 80543| Milliken| Weld County| CO| Colorado| US|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...| 279| null| null| null| SKU1736| 1| N| 279| 2| 06112|2020-05-19 20:29:...| 561| 10000000002|Modern Company, M...|561 Frank Norris ...| 80543| Milliken| Weld County| CO| Colorado| US|
| 1374|[{null, null, 1, ...|{88, 5.7}|[{null, 1624, 1, ...| 279| null| null| null| SKU577| 1| N| 279| 1| 33237|2020-10-12 02:50:...| 1624| 10000000003|Modern Company, C...| 225 Marina Drung| 27924| Colerain| Bertie County| NC|North Carolina| US|
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+--------------------+--------------------+-------------+----------+---------------+----------------+--------------+-------------+
only showing top 5 rows
- Join
productdata withstore_flatten_transactiondata frame and ‘drop’ theproduct_idcolumn. Provide the appropriate values for the placeholders.
- name: product_store_flatten_transaction
doc: Join product data with store_flatten_transaction data frame and '**drop'** the product_id column.
classpath: io.dataos.flare.step.codes.Joiner
params:
join: LEFT
inputs: "{left_df}, {right_df}" # replace {left_df} with left dataframe and {right_df} with right dataframe
joinExpr: "store_flatten_transaction.line_item_product_id=products.product_id"
functions:
- name: {function_name} # drop function name
columns:
- {column_to_drop} # replace this with column name
Expected Output
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+--------------------+--------------------+-------------+----------+---------------+----------------+--------------+-------------+--------------------+--------------------+----------+----------+---------------+--------------+--------------------+---------------+--------------------+
|customer_index| discount| tax| tender|line_item_extended_amount|line_item_original_sequence_number|line_item_original_timestamp|line_item_original_transaction_id|line_item_product_id|line_item_quantity|line_item_return_flag|line_item_sale_amount|line_item_sequence_number|store_id| timestamp|total_sales_amount|transaction_id| store_name| store_address|store_zipcode|store_city| store_county|store_state_code| store_state|store_country| product_name| product_description|list_price|sale_price| brand_name| size_name| size_description|department_name| category_name|
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+--------------------+--------------------+-------------+----------+---------------+----------------+--------------+-------------+--------------------+--------------------+----------+----------+---------------+--------------+--------------------+---------------+--------------------+
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...| 580| null| null| null| SKU1365| 2| N| 580| 1| 27626|2019-10-04 01:04:...| 1298| 10000000001|Modern Company, C...|648 Mabini Boulevard| 59217| Crane|Richland County| MT| Montana| US|Basics - Blank Ad...||Plain Blank T-sh...| 319| 290|Expression Tees| hoodielarge|clothing_size-hoo...| Women|Womens Sweatshirt...|
| 1971|[{null, null, 1, ...|{70, 5.7}|[{4278 7841 4775 ...| 648| null| null| null| SKU5268| 2| N| 648| 2| 27626|2019-10-04 01:04:...| 1298| 10000000001|Modern Company, C...|648 Mabini Boulevard| 59217| Crane|Richland County| MT| Montana| US|Edwards Garment W...|Edwards Garment W...| 377| 324| Edwards| 230| clothing_size-230| Women|Womens Pants & Le...|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...| 297| null| null| null| SKU3108| 1| N| 252| 1| 06112|2020-05-19 20:29:...| 561| 10000000002|Modern Company, M...|561 Frank Norris ...| 80543| Milliken| Weld County| CO| Colorado| US|Maevn PURE Women'...| Top: ? Curved V-...| 345| 297| Maevn|3xlargeregular|clothing_size-3xl...| Women| Womens Activewear|
| 1516|[{45, 15, 1, 15% ...|{30, 5.7}|[{5109 4106 8067 ...| 279| null| null| null| SKU1736| 1| N| 279| 2| 06112|2020-05-19 20:29:...| 561| 10000000002|Modern Company, M...|561 Frank Norris ...| 80543| Milliken| Weld County| CO| Colorado| US|New Way 075 - Men...||Our Tank-Tops ar...| 324| 279| New Way| 2xlarge| size-2xlarge| Men|Mens T-Shirts & T...|
| 1374|[{null, null, 1, ...|{88, 5.7}|[{null, 1624, 1, ...| 279| null| null| null| SKU577| 1| N| 279| 1| 33237|2020-10-12 02:50:...| 1624| 10000000003|Modern Company, C...| 225 Marina Drung| 27924| Colerain| Bertie County| NC|North Carolina| US|Women's Aerosoles...|Sporty and classi...| 307| 279| Aerosoles| 7| shoe_size-7| Shoes| Womens Shoes|
+--------------+--------------------+---------+--------------------+-------------------------+----------------------------------+----------------------------+---------------------------------+--------------------+------------------+---------------------+---------------------+-------------------------+--------+--------------------+------------------+--------------+--------------------+--------------------+-------------+----------+---------------+----------------+--------------+-------------+--------------------+--------------------+----------+----------+---------------+--------------+--------------------+---------------+--------------------+
only showing top 5 rows
- For each
customer_index, calculatetotal_order_value,total_order_count,avg_order_valueandlast_transaction_tsfrom the tableproduct_store_flatten_transactiondata frame.
- name: customer_360_use_case
doc: For each customer_index, calculate total_order_value, total_order_count, avg_order_value and last_transaction_ts from the table product_store_flatten_transaction data frame.
# replace {SQL_statement} with sql statement
sql: |
{SQL_statement}
Expected Output
+--------------+-----------------+-----------------+---------------+--------------------+
|customer_index|total_order_value|total_order_count|avg_order_value| last_transaction_ts|
+--------------+-----------------+-----------------+---------------+--------------------+
| 1| 9720| 12| 810.0|2020-11-01 22:07:...|
| 2| 11590| 7| 1655.71|2020-11-17 21:17:...|
| 3| 2809| 2| 1404.5|2020-12-24 09:47:...|
| 4| 3018| 5| 603.6|2020-01-31 12:38:...|
| 5| 2605| 3| 868.33|2019-12-24 03:57:...|
+--------------+-----------------+-----------------+---------------+--------------------+
only showing top 5 rows
- Join the
customer_citydata frame withcustomer_360_use_casedata frame (created in the last step) and dropcust_indexcolumn. Then, provide the appropriate values for the placeholders.
- name: customer_360
doc: join customer_city data frame with customer_360_use_case data frame (created in the last step) and drop cust_index column.
classpath: io.dataos.flare.step.codes.Joiner
params:
join: LEFT
inputs: "{left_df}, {right_df}" # replace {left_df} with left dataframe and {right_df} with right dataframe
joinExpr: "{joinExpr}" # replace {joinExpr} with join expression
functions:
- name: drop
columns:
- cust_index
Expected Output
+--------------+-----------------+-----------------+---------------+--------------------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+--------+---------+----------------+----------+-------------+
|customer_index|total_order_value|total_order_count|avg_order_value| last_transaction_ts| Id|salutation|first_name|last_name|gender| phone_number| email_id| birthdate|age| education_level| marital_status|number_of_children| occupation|annual_income| employment_status| hobbies|home_ownership|degree_of_loyalty|benefits_sought| personality| user_status| social_class|lifestyle|customer_city_id| mailing_street|zip_code|city_name| county_name|state_code| state_name|
+--------------+-----------------+-----------------+---------------+--------------------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+--------+---------+----------------+----------+-------------+
| 1| 9720| 12| 810.0|2020-11-01 22:07:...|fa472f08-16a8-cd8...| Mrs.| Tatum| Norton|FEMALE| 895.368.6078|rushland2027@live...|1987-05-04| 33| Associate's Degree| Divorced| 4|Choreographer| $35k-$50k|Employed Part-Time| Juggling| own| Switchers| Functionality| Easygoing| Potential Users| Middle Class| Explorer| CITY36885| 511 Recycle Run| 45853| Kalida| Putnam County| OH| Ohio|
| 2| 11590| 7| 1655.71|2020-11-17 21:17:...|8b5ce542-270c-4d1...| B.E.| Hyman| Riley| MALE| 1-493-661-9142|boutade2068@gmail...|1969-05-01| 51|Postgraduate Degree|Domestic Partner| 5| Fruiterer| $150k-$200k| Self-Employed|Handicraft| own| Switchers| Functionality|Determined and Am...|First-Time Users| Middle Class|Succeeder| CITY29232| 703 Leese Townline| 3233| Elkins|Merrimack County| NH|New Hampshire|
| 3| 2809| 2| 1404.5|2020-12-24 09:47:...|3525d90e-8a7c-6e1...| Ms.| Robbyn| Blair|FEMALE|+1-(543)-288-7392|differences1851@l...|1993-03-17| 27| Associate's Degree| Unknown| 4| Polisher| <$15k|Seeking Employment| Excercise| own| Hard Core Loyals| Cost Advantage|Determined and Am...| Potential Users|Working Class| Reformer| CITY10442| 83 Northwood Trace| 83338| Jerome| Gooding County| ID| Idaho|
| 4| 3018| 5| 603.6|2020-01-31 12:38:...|89df6007-9a82-4b6...| Miss| Tracy| Webster| OTHER| (738) 757-4620|whitier2026@proto...|1991-11-23| 28|High School Diploma| Separated| 1| Rent Offcer| $150k-$200k|Employed Full-Time| Cycling| own| Soft Core Loyals| Cost Advantage| Easygoing| Ex-Users| Middle Class| Explorer| CITY9608| 369 Royal Crescent| 39837| Colquitt| Miller County| GA| Georgia|
| 5| 2605| 3| 868.33|2019-12-24 03:57:...|09773ce4-d931-74c...| Mr.| Claud| Mcneil| MALE| 792.521.1724|alligators1863@pr...|1977-02-05| 43| Graduate Degree| Unknown| 5| Childminder| $25k-$35k| Self-Employed| Writing| rent| Switchers|Self-Expression|Determined and Am...| Non-Users|Working Class| Reformer| CITY45320|792 De Forest Gar...| 76524| Eddy| Falls County| TX| Texas|
+--------------+-----------------+-----------------+---------------+--------------------+--------------------+----------+----------+---------+------+-----------------+--------------------+----------+---+-------------------+----------------+------------------+-------------+-------------+------------------+----------+--------------+-----------------+---------------+--------------------+----------------+-------------+---------+----------------+--------------------+--------+---------+----------------+----------+-------------+
only showing top 5 rows
Note: To exit the Scala SQL shell, press
Ctrl+c.
Run Transformations¶
After completing the tasks given in the previous section, you will be able to run these transformations and create the final Customer 360.
Note: Before renaming files, create a backup of the files.
- Flare standalone only runs config.yaml file. ****You must rename
config_template.yamltoconfig.yaml. This is to run the transformations you wrote to create thecustomer_360table.- Open the terminal and navigate to the assignment directory and use the following command to run config.yaml
docker run --rm -it \
-v $PWD/flareconfig:/etc/standalone \
-v $PWD:/datadir \
-v $PWD/dataout:/dataout \
-e DATAOS_WORKSPACE=public \
-e DATAOS_RUN_AS_USER=tmdc \
rubiklabs/flare2:5.9.2 start
Note: Refer to the additional flag for your docker command if you use an M1 Mac machine.
- Using Spark query
tables, you can see the final Customer_360 table created.
Expected Output
+---------+-----------------------------------------------+-----------+
|namespace|tableName |isTemporary|
+---------+-----------------------------------------------+-----------+
| |customer_360 |true |
| |customer_360_1667804433693 |true |
| |customer_360_use_case |true |
| |customer_city |true |
| |customers |true |
| |flatten_transaction |true |
| |input_cities |true |
| |input_customer |true |
| |input_stores |true |
| |input_transactions |true |
| |product_store_flatten_transaction |true |
| |product_store_flatten_transaction_1667804433477|true |
| |products |true |
| |store_flatten_transaction |true |
| |store_flatten_transaction_1667804433352 |true |
| |stores |true |
| |transaction_explode_lineitem |true |
+---------+-----------------------------------------------+-----------+
Validate the Outcome¶
The final output of the above steps can be checked with the config_solution.yaml.
Follow the below steps to run this file.
- Please make sure to take a backup of your current
config.yaml. This is the file where you have inserted the required SQL statements. - Rename
config_solution.yamlasconfig.yaml - Run the file using Flare or Docker command, as explained earlier, here.
- Run the Spark SQL commands to see the final table Customer_360 and its data.
Resources¶
config.yaml
version: v1 #version
name: enrich-trans-pro-city-store # This defines the name of the workflow which you want to run. Rules for Workflow name: 64 alphanumeric characters and a special character '-' allowed. [a-z,0-9,-]
type: workflow
tags:
- Rio
- Offline Sales
- Enriched
- Evolution
description: This job is enriching offline sales data with store, city and product and customer data to create customer360 #This is the text describing the workflow.
workflow:
dag:
- name: txn-enrich-product-city-store
title: Offline Sales Data Enricher
description: This job is enriching offline sales data with store, city, and product
spec:
tags:
- Rio
- Offline Sales
- Enriched
- Evolution
stack: flare:3.0 #Here, you define the Flare stack version to run the workflow.
flare:
driver:
coreLimit: 2400m
cores: 2
memory: 3072M
executor:
coreLimit: 2400m
cores: 2
instances: 2
memory: 6000M
job:
explain: true
inputs: # data sources to read from
- name: input_cities
format: csv # data format
dataset: /datadir/data/city.csv # city data
schemaPath: /datadir/schema/city.avsc # city Schema
- name: products
format: csv
dataset: /datadir/data/product.csv
schemaPath: /datadir/schema/product.avsc
- name: input_stores
format: csv
dataset: /datadir/data/store.csv
schemaPath: /datadir/schema/store.avsc
- name: input_transactions
format: json
dataset: /datadir/data/pos_transactions.json
- name: input_customer
format: csv
dataset: /datadir/data/customer.csv
schemaPath: /datadir/schema/customer.avsc
logLevel: ERROR
outputs: # reference and location of the output
- name: output01
depot: /dataout
steps: # transformation steps
- sequence: # series of data processing sql statements
- name: stores
doc: select all columns from input_stores
sql: select * from input_stores # select all columns form input_stores, replace {SQL_statement} with sql statement
sparkConf: # Spark configuration
- spark.serializer: org.apache.spark.serializer.KryoSerializer
- spark.sql.legacy.timeParserPolicy: LEGACY
- spark.sql.shuffle.partitions: "50"
config_template.yaml
version: v1 #version
name: enrich-trans-pro-city-store # This defines the name of the workflow which you want to run. Rules for Workflow name: 64 alphanumeric characters and a special character '-' allowed. [a-z,0-9,-]
type: workflow
tags:
- Rio
- Offline Sales
- Enriched
- Evolution
description: This job is enriching offline sales data with store, city, product, and customer data to create customer360 #This is the text describing the workflow.
workflow:
dag:
- name: txn-enrich-product-city-store
title: Offline Sales Data Enricher
description: This job is enriching offline sales data with store, city, and product
spec:
tags:
- Rio
- Offline Sales
- Enriched
- Evolution
stack: flare:3.0 #Here, you define the Flare stack version to run the workflow.
flare:
driver:
coreLimit: 2400m
cores: 2
memory: 3072M
executor:
coreLimit: 2400m
cores: 2
instances: 2
memory: 6000M
job:
explain: true
inputs: **# data sources to read from**
- name: input_cities
format: csv # data format
dataset: /datadir/data/city.csv # city data
schemaPath: /datadir/schema/city.avsc # city Schema
- name: products
format: csv
dataset: /datadir/data/product.csv
schemaPath: /datadir/schema/product.avsc
- name: input_stores
format: csv
dataset: /datadir/data/store.csv
schemaPath: /datadir/schema/store.avsc
- name: input_transactions
format: json
dataset: /datadir/data/pos_transactions.json
- name: input_customer
format: csv
dataset: /datadir/data/customer.csv
schemaPath: /datadir/schema/customer.avsc
logLevel: ERROR
outputs: **# reference and location of the output**
- name: output01
depot: /dataout
steps: **# transformation steps**
- sink: **# output dataset details and additional options
-** sequenceName: customer_360
datasetName: customer_360
outputName: output01
outputType: Iceberg
outputOptions:
saveMode: overwrite
sort:
mode: partition
columns:
- name: last_transaction_ts
order: desc
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
partitionSpec:
- type: month
column: last_transaction_ts
name: month
sequence: **# series of data processing sql statements**
- name: stores
doc: Select all columns from input_stores data frame, and rename store_id column to s_id
sql: select * from input_stores # select all columns form input_stores, replace {SQL_statement} with sql statement
functions:
- name: rename_all # this function renames a column
columns:
store_id: s_id
- name: customers
doc: Select all columns from the input_customer data frame and rename customer_index to cust_index
sql: {SQL_statement} # select all columns form input_customer, replace {SQL_statement} with sql statement
functions:
- name: rename_all
columns:
{old_column_name}: {new_column_name} #Replace {old_column_name} and {new_column_name} eg: customer_index: cust_index
- name: customer_city
doc: Add city information to the customer's data frame and drop the city_id column.
sql: select * from customers left join input_cities on customers.customer_city_id = input_cities.city_id
functions:
- name: drop # this function drop columns a column
columns:
- city_id # Columns to drop
- name: transaction_explode_lineitem
doc: Use the Spark SQL function 'Explode' for the transaction_line_item column in the input_transactions table as line_items to extract the line item information.
sql: {SQL_statement} # replace {SQL_statement} with sql statement
functions:
- name: drop
columns:
- {column_to_drop} # replace this with column name
- name: flatten_transaction
doc: Extract all columns from line_items and transaction_header columns from transaction_explode_lineitem and drop both columns from the new data frame.
sql: select * from transaction_explode_lineitem
functions:
- name: unfurl # function to extract columns
expression: "line_items.*"
- name: unfurl
expression: "transaction_header.*"
- name: drop
columns: # multiple columns can be dropped
- line_items
- transaction_header
- name: store_flatten_transaction
doc: Join stores data with the flatten_transaction data frame created in the last operation and ‘drop’ the s_id column.
classpath: io.dataos.flare.step.codes.Joiner # flare declarative way of performing join
params:
join: LEFT
inputs: "flatten_transaction, stores" # left and right dataframe
joinExpr: "flatten_transaction.store_id=stores.s_id" # join expression
functions:
- name: {function_name} # drop function name
columns:
- {column_to_drop} # replace this with column name
- name: product_store_flatten_transaction
doc: Join product data with store_flatten_transaction data frame and 'drop' the product_id column.
classpath: io.dataos.flare.step.codes.Joiner
params:
join: LEFT
inputs: "{left_df}, {right_df}" # replace {left_df} with left dataframe and {right_df} with right dataframe
joinExpr: "store_flatten_transaction.line_item_product_id=products.product_id"
functions:
- name: {function_name} # drop function name
columns:
- {column_to_drop} # replace this with column name
- name: customer_360_use_case
doc: For each customer_index, calculate total_order_value, total_order_count, avg_order_value and last_transaction_ts from the table product_store_flatten_transaction data frame.
# replace {SQL_statement} with sql statement
sql: |
{SQL_statement}
- name: customer_360
doc: join customer_city data frame with customer_360_use_case data frame (created in the last step) and drop cust_index column.
classpath: io.dataos.flare.step.codes.Joiner
params:
join: LEFT
inputs: "{left_df}, {right_df}" # replace {left_df} with left dataframe and {right_df} with right dataframe
joinExpr: "{joinExpr}" # replace {joinExpr} with join expression
functions:
- name: drop
columns:
- cust_index
sparkConf: # Spark configuration
- spark.serializer: org.apache.spark.serializer.KryoSerializer
- spark.sql.legacy.timeParserPolicy: LEGACY
- spark.sql.shuffle.partitions: "50"
config_solutions.yaml
version: v1
name: enrich-trans-pro-city-store
type: workflow
tags:
- Rio
- Offline Sales
- Enriched
- Evolution
description: This job is enriching offline sales data with store, city, and product
workflow:
dag:
- name: txn-enrich-product-city-store
title: Offline Sales Data Enricher
description: This job is enriching offline sales data with store, city, and product
spec:
tags:
- Rio
- Offline Sales
- Enriched
- Evolution
stack: flare:3.0
flare:
driver:
coreLimit: 2400m
cores: 2
memory: 3072M
executor:
coreLimit: 2400m
cores: 2
instances: 2
memory: 6000M
job:
explain: true
inputs:
- name: input_cities
format: csv
dataset: /datadir/data/city.csv
schemaPath: /datadir/schema/city.avsc
- name: products
format: csv
dataset: /datadir/data/product.csv
schemaPath: /datadir/schema/product.avsc
- name: input_stores
format: csv
dataset: /datadir/data/store.csv
schemaPath: /datadir/schema/store.avsc
- name: input_transactions
format: json
dataset: /datadir/data/pos_transactions.json
- name: input_customer
format: csv
dataset: /datadir/data/customer.csv
schemaPath: /datadir/schema/customer.avsc
logLevel: ERROR
outputs:
- name: output01
depot: /dataout
steps:
- sink:
- sequenceName: customer_360
datasetName: customer_360
outputName: output01
outputType: Iceberg
outputOptions:
saveMode: overwrite
sort:
mode: partition
columns:
- name: last_transaction_ts
order: desc
iceberg:
properties:
write.format.default: parquet
write.metadata.compression-codec: gzip
partitionSpec:
- type: month
column: last_transaction_ts
name: month
sequence:
- name: stores
doc: Rename store_id column to s_id in input_stores
sql:
SELECT * FROM input_stores
functions:
- name: rename_all
columns:
store_id: s_id
- name: customers
doc: Rename customer_index to cust_index in input_customer
sql: select * from input_customer
functions:
- name: rename_all
columns:
customer_index: cust_index
city_id: customer_city_id
- name: customer_city
doc: add city information to customer data
sql: select * from customers left join input_cities on customers.customer_city_id = input_cities.city_id
functions:
- name: drop
columns:
- city_id
- name: transaction_explode_lineitem
doc: Explode transaction line item column to extract line item information
sql: select *, explode(transaction_line_item) as line_items from input_transactions
functions:
- name: drop
columns:
- transaction_line_item
- name: flatten_transaction
doc: Extract all columns from line_items and transaction_header columns from the last frame and drop both columns.
sql: select * from transaction_explode_lineitem
functions:
- name: unfurl
expression: "line_items.*"
- name: unfurl
expression: "transaction_header.*"
- name: drop
columns:
- line_items
- transaction_header
- name: store_flatten_transaction
doc: Join store data to flatten_transaction data frame and drop s_id column
classpath: io.dataos.flare.step.codes.Joiner
params:
join: LEFT
inputs: "flatten_transaction, stores"
joinExpr: "flatten_transaction.store_id=stores.s_id"
functions:
- name: drop
columns:
- s_id
- name: product_store_flatten_transaction
doc: Join product data to store_flatten_transaction data frame and drop product column
classpath: io.dataos.flare.step.codes.Joiner
params:
join: LEFT
inputs: "store_flatten_transaction, products"
joinExpr: "store_flatten_transaction.line_item_product_id=products.product_id"
functions:
- name: drop
columns:
- product_id
- name: customer_360_use_case
doc: calculate The average order value and The total order count. The total order value
sql: |
SELECT customer_index,
Sum(line_item_extended_amount) total_order_value,
Count(DISTINCT transaction_id) total_order_count,
Round(Sum(line_item_extended_amount) / Count(DISTINCT transaction_id), 2) avg_order_value,
to_timestamp(max(timestamp)) last_transaction_ts
FROM product_store_flatten_transaction
GROUP BY customer_index
- name: customer_360
doc: join customer_city frame with customer_360_use_case frame
classpath: io.dataos.flare.step.codes.Joiner
params:
join: LEFT
inputs: "customer_360_use_case, customer_city"
joinExpr: "customer_360_use_case.customer_index = customer_city.cust_index"
functions:
- name: drop
columns:
- cust_index
sparkConf:
- spark.serializer: org.apache.spark.serializer.KryoSerializer
- spark.sql.legacy.timeParserPolicy: LEGACY
- spark.sql.shuffle.partitions: "50"