Cloud to Local - Using Standalone 2.0¶
Case Scenario¶
Let's take a case scenario where we read data from the Pulsar and write it to the Local File System. After writing the data to the environment Pulsar, we also want to run some Scala commands to verify whether our data is written and has the appropriate schema.
You can check out the Standalone YAML configuration section for other inputs and outputs data sources.
But before diving right into the programming stuff, let's ensure you have the required prerequisites.
Pre-Requisites¶
Install/Update DataOS CLI with the latest version¶
DataOS CLI should be installed on your system with the latest version. To get the details of the CLI version, run the command after logging into DataOS
Note: Ensure you are logged into DataOS before executing the above command. If you haven't logged in, run the
dataos-ctl logincommand in the terminal.
If CLI is not updated to the latest version, navigate to the below page
Get the Pulsar-admin tag¶
Since we would be dealing with environment Pulsar format, you will need the pulsar-admin tag to read the data from the environment Pulsar. To check the available tags that you have, execute the command:
dataos-ctl user get
# Output
NAME | ID | TYPE | EMAIL | TAGS
---------------|-------------|--------|----------------------|---------------------------------
IamGroot | iamgroot | person | iamgroot@tmdc.io | roles:direct:collated,
| | | | roles:id:data-dev,
| | | | roles:id:depot-manager,
| | | | roles:id:depot-reader,
| | | | **roles:id:pulsar-admin**, # this is the required Pulsar-admin tag
| | | | roles:id:system-dev,
| | | | roles:id:user,
| | | | users:id:iamgroot
Operationalize Docker if you want to Read/Write IO Locally¶
Docker should be installed and running on the system. If Docker is installed on your system, move to the next step. In case it's not installed, visit the official Docker installation page for the same by clicking the link
Basics of Scala Programming¶
Flare Standalone uses Scala Programming Language. In case you don't know about Scala, no worries. We have covered you with some basic commands to help you make the most of Standalone.
Let's Begin¶
Download and Unzip Sample Data¶
- Download the
flare-standalone.zipfolder provided below
- Extract the downloaded
flare-standalone.zipfile. It contains only one folder by the namestandalone. Next, you can open the code editor inside theflare-standalonefolder. - Now the scenario looks like the image below, where you have opened the code editor inside the
flare-standalonefolder, which contains thestandalonefolder which further includes one folder by the namedataoutand another file by the nameconfig.yaml
Adding details to the Flare Standalone Workflow YAML¶
- Open the
config.yamlfile using the code editor. The YAML looks like the one given below
version: v1 # Manifest Version
name: standalone-read-pulsar # Workflow Name
type: workflow # Resource/primitive (here its workflow)
tags: # Tags
- standalone
- read
- pulsar
description: Sample job # Description
workflow: # Workflow Section
dag: # Directed Acyclic Graph of Jobs (it has only one job at present can be more than one also)
- name: customer # Job Name
title: Sample Transaction Data Ingester # Title
description: The job ingests customer data from pulsar topic to file source # Job Description
spec: # Specs for the job
tags: # Tags
- standalone
- read
- pulsar
envs: # Environment Variables for Pulsar (Mandatory else job will fail)
PULSAR_SSL: true
ENABLE_PULSAR_AUTH: true
DATAOS_RUN_AS_APIKEY: <dataos-api-key> # Run `dataos-ctl user apikey get`
stack: flare:3.0 # Stack Version
compute: runnable-default # Compute Type
flare:
job:
explain: true
logLevel: INFO #logLevel for the Job
streaming: # Streaming Section
checkpointLocation: /tmp/checkpoints/pulsar #Checkpoint Location
forEachBatchMode: true
inputs: # Inputs Section
- name: transactions_connect # Name from which the input will be referred
inputType: pulsar # Datasource Input Type
pulsar: # Datasource input specific section
serviceUrl: pulsar+ssl://tcp.<dataos-context>:<port> # ServiceURL for Pulsar
adminUrl: https://tcp.<dataos-context>:<port> # AdminURl for Pulsar
tenant: public # Pulsar Tenant
namespace: default # Pulsar Namespace
topic: transactions12 # Topic Name, make sure the topic exists in the environment
# Use the command `dataos-ctl fastbase topic -n <tenant>/<namespace> list` to get list of topics
isBatch: true
outputs: # Output Data Source Section
- name: finalDf # Name of the output data source
outputType: file # Datasource output type (here's its file)
file: # Datasource outputs specific section
format: iceberg # file format
warehousePath: /data/examples/dataout/ # Output data source location
schemaName: default # Schema Name
tableName: sample # Table Name
options: # Additional Options
saveMode: append # Type of Save Mode
steps: # Transformation Steps Section
- sequence: # Sequence
- name: finalDf # Step Name
sql: SELECT * FROM transactions_connect # SQL
- Naming convention for local read/write IO
The paths given in the sample
config.yamlfor local write are the docker container paths where the data will be mounted. If you want to write the data inside the folderdataout, and you have opened the code editor inside thestandalonefolder, then the output YAML path will be/data/examples/dataout/But if you have opened the terminal outside thestandalonefolder, the path will be/data/examples/standalone/dataout/You can store the data and theconfig.yamlanywhere you want, you have to configure the paths accordingly. - You also require the DataOS
apikey, which you can get by executing the below command
If you don't have it, you can also create a new one
-
The last and final aspect that's missing is the
serviceUrlandadminUrl, for which you require two things<dataos-context>- The system administrator provides this in your organization<port>- The serviceUrl and AdminUrl ports are available in the Operations App. If you want to know more, you can go ahead and just navigate to the page below.
Running the Flare Workflow YAML¶
- You can use the below command to run the
config.yaml.
dataos-ctl develop start -s <flare-version> -i <custom-image> -f <path-of-config.yaml> -d <path-of-data-directory> -P <port-number>
Example
dataos-ctl develop start -s flare:3.0 -i rubiklabs/flare3:6.0.93 -f standalone/config.yaml -d standalone -P 14042
Note: The
config.yamland data directory path could be either absolute or relative. The port number by default is set at 14040, but if you have a job already running on 14040, you can configure it to a different port, e.g., 14042.
- Since we have exposed the Spark Web UI on port 14042, we can type localhost:14042 in any web browser to check the status of the job
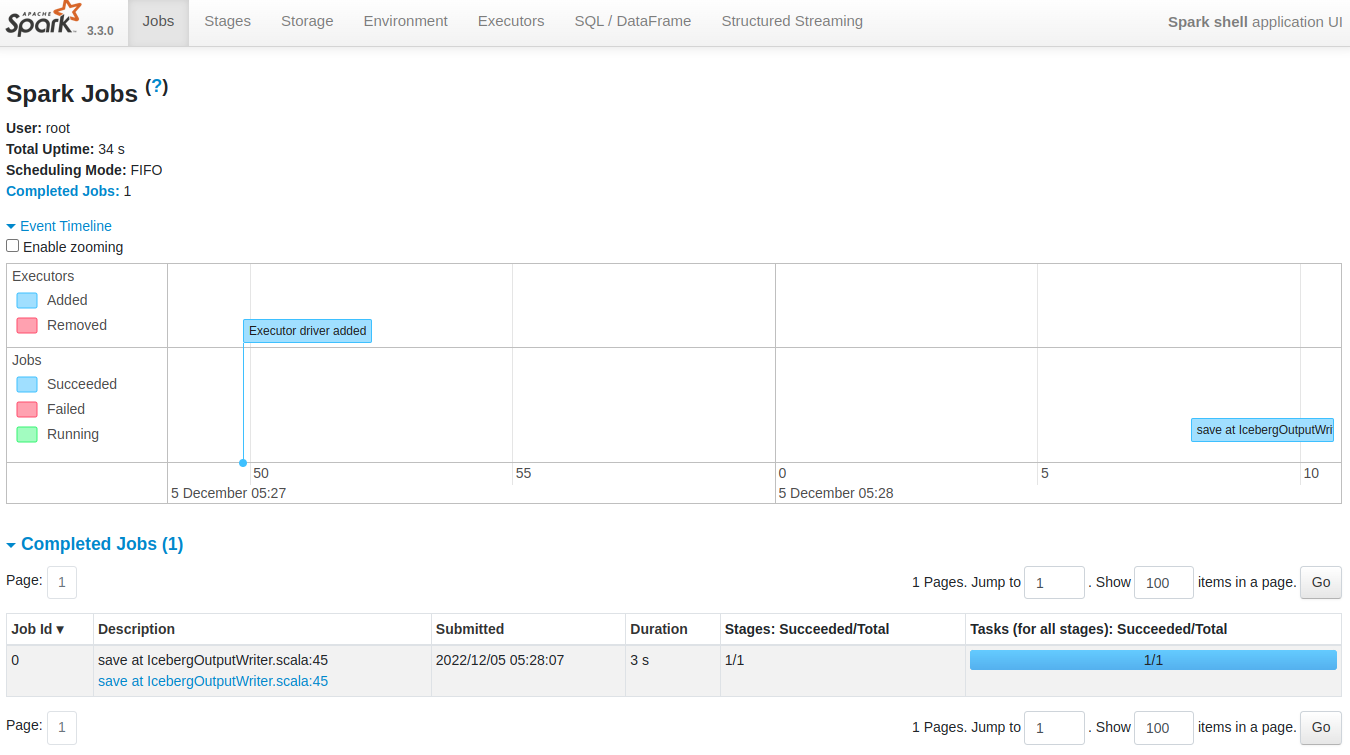
To know more about the various sections of the Spark UI and what each one of them signifies, navigate to the link
- On successful execution, the Scala command line shell will open as below:
2022-12-05 05:28:10,854 INFO [main] i.d.f.c.ProcessingContext: **run complete.
# When you see this run complete message, then only your job has successfully executed**
2022-12-05 05:28:10,865 INFO [dispatcher-BlockManagerMaster] o.a.s.s.BlockManagerInfo: Removed broadcast_1_piece0 on a1a833f1a4b1:38377 in memory (size: 38.9 KiB, free: 366.3 MiB)
Flare session is available as flare.
Welcome to
______ _
| ____| | |
| |__ | | __ _ _ __ ___
| __| | | / _` | | '__| / _ \
| | | | | (_| | | | | __/
|_| |_| \__,_| |_| \___| version 1.2.0
Powered by Apache Spark 3.3.0
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_262)
Type in expressions to have them evaluated.
Type :help for more information.
- You can check the
dataoutfolder under which the data read from Pulsar is written
Exploring Spark Commands in Scala Interactive Shell¶
After successful job execution, you can run various Spark commands in Scala interactive shell.
tablescommand will give you the list of all tables in the current directory. You should see thefinaldfandtransactions_connecttables listed, which are created after the given YAML is successfully run.
scala> tables
# Expected Output
+---------+--------------------+-----------+
|namespace|tableName |isTemporary|
+---------+--------------------+-----------+
| |finaldf |true |
| |transactions_connect|true |
+---------+--------------------+-----------+
You must debug your code if you still need to get the required output or find the above table empty.
- You can also run a Spark SQL query to verify the data, as follows:
- You can also run a Spark SQL query to print schema to verify the data, as follows:
scala> spark.sql("SELECT * FROM finaldf").printSchema
# Expected Output
root
|-- customer: struct (nullable = true)
| |-- customer_index: long (nullable = true)
| |-- email: string (nullable = true)
| |-- phone: string (nullable = true)
| |-- type: string (nullable = true)
|-- order: struct (nullable = true)
| |-- created_on: string (nullable = true)
| |-- id: string (nullable = true)
| |-- parent_order_id: string (nullable = true)
| |-- type: string (nullable = true)
|-- order_items: array (nullable = true)
| |-- element: struct (containsNull = true)
| | |-- id: long (nullable = true)
| | |-- pricing: struct (nullable = true)
| | | |-- actualprice: long (nullable = true)
| | | |-- listprice: long (nullable = true)
| | | |-- saleprice: long (nullable = true)
| | |-- promotion: struct (nullable = true)
| | | |-- amount: long (nullable = true)
| | | |-- percent: long (nullable = true)
| | | |-- type: string (nullable = true)
| | |-- quantity: long (nullable = true)
| | |-- sku_id: string (nullable = true)
| | |-- tax: struct (nullable = true)
| | | |-- amount: long (nullable = true)
| | | |-- percent: long (nullable = true)
|-- payments: struct (nullable = true)
| |-- amount: long (nullable = true)
| |-- credit_card_number: string (nullable = true)
|-- shipment: struct (nullable = true)
| |-- carrier: string (nullable = true)
| |-- charges: long (nullable = true)
| |-- city_id: string (nullable = true)
| |-- mailing_street: string (nullable = true)
|-- user_client: struct (nullable = true)
| |-- ip_address: string (nullable = true)
| |-- mac_address: string (nullable = true)
| |-- session_id: string (nullable = true)
| |-- type: string (nullable = true)
| |-- user_agent: string (nullable = true)
|-- __key: binary (nullable = true)
|-- __topic: string (nullable = true)
|-- __messageId: binary (nullable = true)
|-- __publishTime: timestamp (nullable = true)
|-- __eventTime: timestamp (nullable = true)
|-- __messageProperties: map (nullable = true)
| |-- key: string
| |-- value: string (valueContainsNull = true