Schema Evolution in Nilus¶
Nilus handles schema registration and evolution automatically when ingesting data from various sources. This document explains how schema registration, evolution, and data type management work in Nilus.
Nilus is a data movement stack that ingests data from source systems (APIs, databases, etc.) and writes it to destination systems. Along with this, schema registration happens automatically on-the-fly as data is ingested.
Automatic Schema Registration¶
When Nilus ingests data for the first time:
- It analyzes the incoming data structure.
- Automatically detects field names and data types.
- Creates corresponding columns in the target table.
- Registers the schema in the Metis catalog.
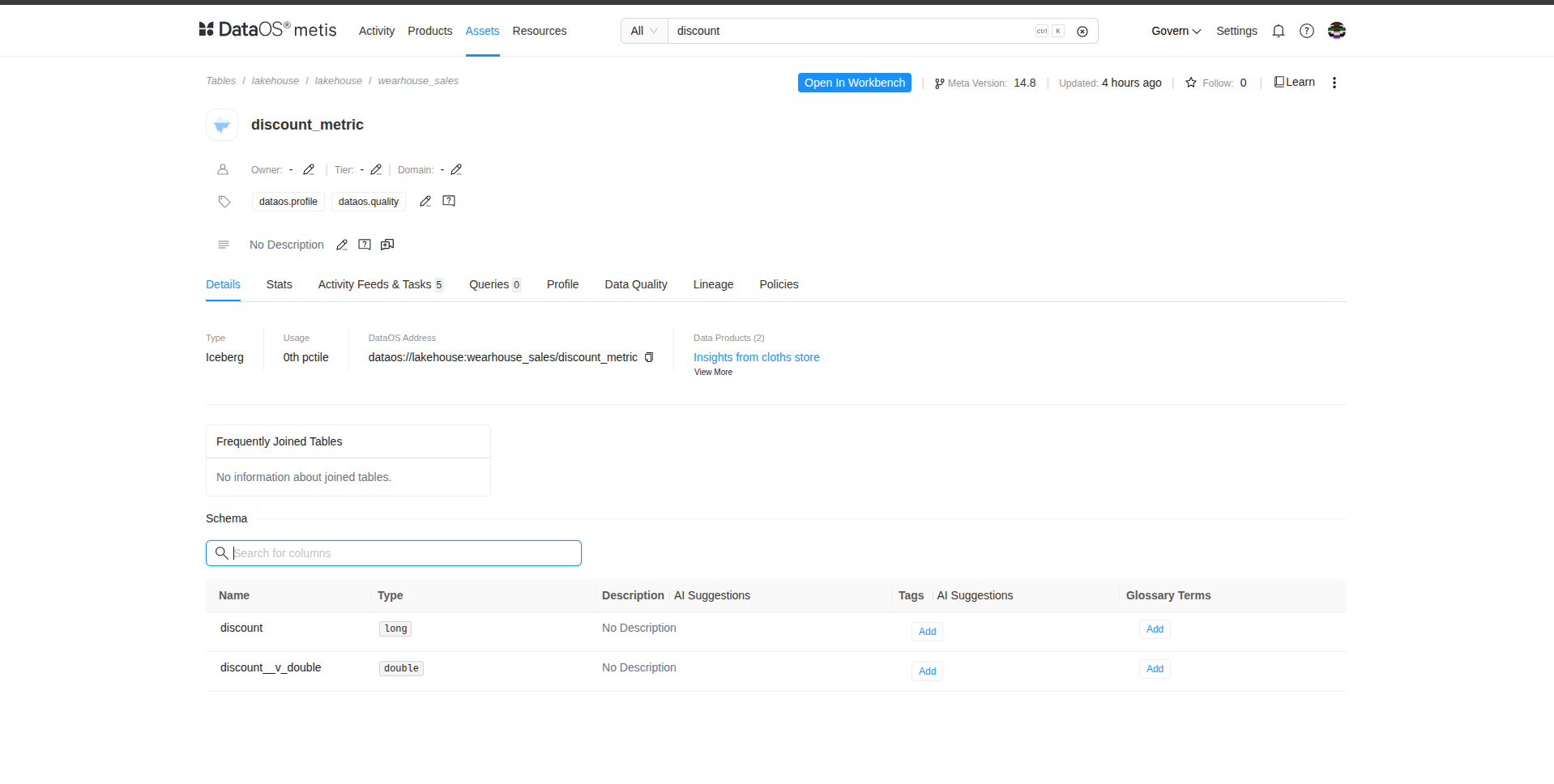
The schema is visible in Metis UI, showing all column names and their data types for the registered table.
Schema Evolution¶
Schema evolution in Nilus handles changes in source data structure across different ingestion runs. The behavior is deterministic and follows specific rules.
Data Type Changes¶
When the data type of a field changes between ingestion runs, Nilus creates a separate column rather than overwriting the existing one.
Example Scenario
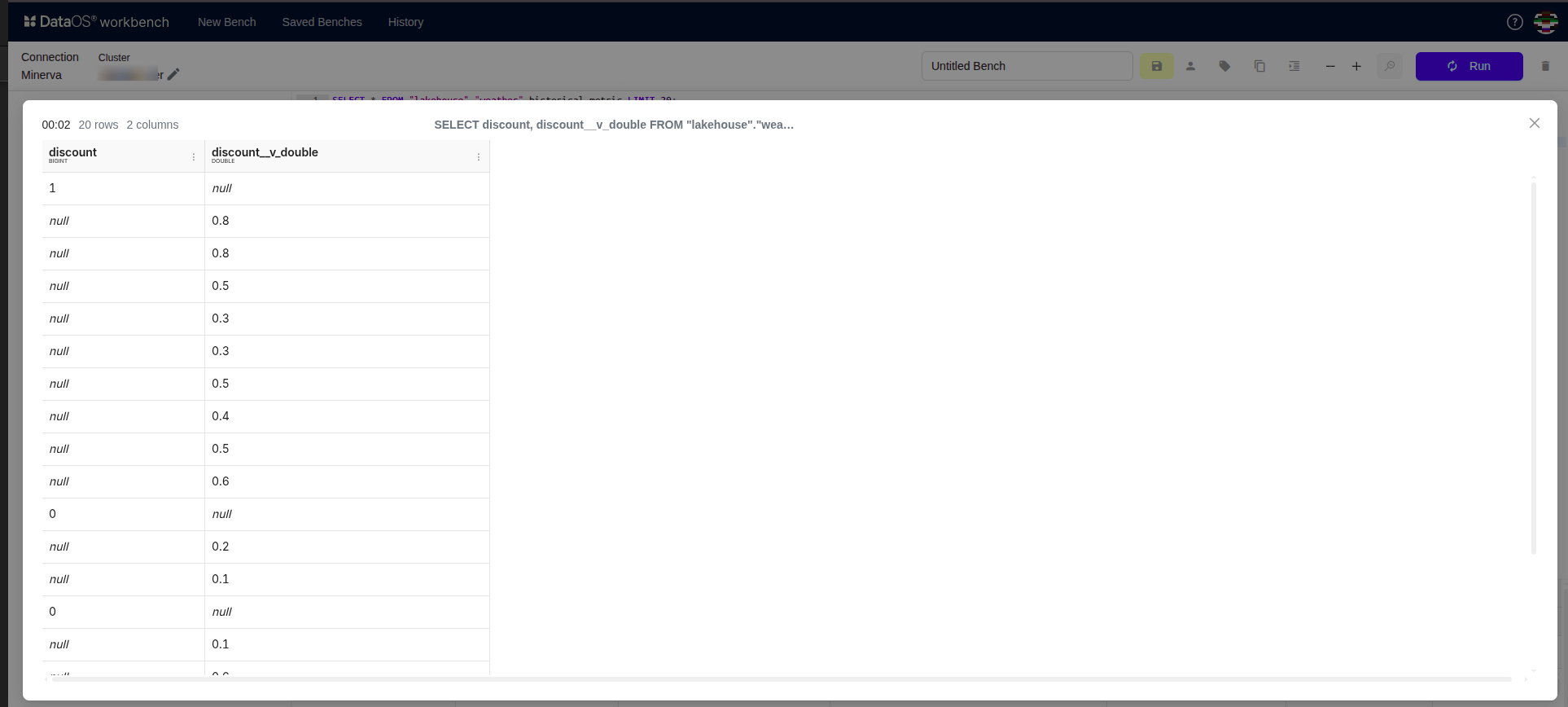
Consider a field called discount:
Run 1: discount comes as integer
- Nilus creates a column
discountwith data typebigint
Run 2: discount comes as double
- Nilus creates a new column with a different name (using a standard suffix, i.e.
<column_name>__v_<new_type>) - The original
discountcolumn remains unchanged - Data is written to the new column
Run 3: discount comes back as integer
- Nilus writes the data back to the original
discountcolumn. - No new column is created since a column with that data type already exists as shown in the below image:
Column Naming Convention¶
Nilus has a built-in schema inference and evolution engine powered by dlt. Schema evolution is supported out of the box:
- New columns → automatically added.
- Changed data types → non-coercible values go into a variant column (
<col>__v_<type>). - Removed columns → remain in schema; new rows contain NULLs for that column.
This mechanism enables multiple columns to represent the same logical field across varying data types, ensuring ingestion continues uninterrupted despite upstream schema changes.
Variant Columns¶
When a column’s data type changes and values can’t be coerced to the existing type, Nilus creates a variant column.
Pattern:
For example, when the discount column initially of type bigint receives values of type double, a new column named discount__v_double is created. These variant columns can be reconcile or promote values as needed by the downstream consumers.
Info
Nilus focuses on data movement. Schema management in downstream processing (merging columns, type resolution) should be handled by compute stacks like Spark or Flare when building Data Products.
Explicit Data Type Definition¶
While Nilus can automatically infer schema, you can explicitly define data types in the Nilus workflow YAML to ensure consistency and prevent unwanted schema evolution.
Using the type-hints Option¶
Define expected data types in the source.options section:
Warning
The columns parameter within source.options has been renamed to type-hints. It now accepts a list of column specifications, where each entry is a string in the format column_name:data_type. Please update your code to the latest version of Nilus accordingly.
Column Definition Syntax
Example:
source:
address: dataos://postgres
options:
source-table: "nilus.test_dataset"
type-hints:
income: text
salary: bigint
score: text
revenue: double
temperature: double
birth_date: text
registration_date: text
purchase_date: text
Benefits of Explicit Type Definition¶
- Prevents Schema Drift: Ensures consistent data types across ingestion runs.
- Data Validation: Invalid data types will be handled according to your error handling configuration.
- Performance: Eliminates need for type inference on every run.
- Predictability: Schema remains stable even if source data quality varies.
Best Practices¶
- Define Explicit Types: Use the
type-hintsoption in your workflow YAML when data types are known and stable. - Monitor Schema Changes: Regularly check Metis UI for unexpected new columns that indicate schema drift.
- Validate at Source: Ensure data quality at the source system to minimize schema evolution.
- Version Control: Keep your Nilus workflow YAMLs in version control to track schema definition changes.
Viewing Schema in Metis¶
After Nilus ingests data, view the registered schema in Metis:
- Navigate to Metis UI
- Search for your table by name or explore via Assets tab
- Navigate to the respective table
- View the Schema tab showing:
- All column names (including evolved columns with suffixes)
- Data types for each column
- Column descriptions and metadata