Lakesearch troubleshooting¶
After deploying the Lakesearch Service, if its runtime state remains unchanged for an extended period, it may have encountered an issue. Users can check the Service logs to identify potential errors and resolve them.
Below are some common errors and their respective solutions.
id is not present in the index_table¶
If you forget to add the additional column id while configuring the Lakesearch Service, the runtime status will remain pending, and the logs will display the following message:
dataos-ctl log -t service -n testingls -w public -r
INFO[0000] 📃 log(public)...
INFO[0001] 📃 log(public)...complete
NODE NAME │ CONTAINER NAME │ ERROR
────────────────────────────────────┼────────────────────────┼────────
testingls-eacp-d-7f4ccb75d8-rtflh │ testingls-eacp-indexer │
-------------------LOGS-------------------
10:42AM INF pkg/config/config.go:126 > Loading config... file:///etc/dataos/config/lakesearch.yaml [success]
10:42AM FTL pkg/config/lakesearch.go:227 > column `id` is not present in the index_table: newcity columns schema, mandatory column.
Steps to resolve:
-
In the Lakesearch Service manifest file, add an additional column in the
index_tables.columnssection as shown below.index_tables: - name: newcity description: "index for cities" tags: - cities properties: morphology: stem_en columns: - name: city_id type: keyword - name: zip_code type: bigint - name: id #added description: "mapped to row_num" tags: - identifier type: bigint - name: city_name type: keyword - name: county_name type: keyword - name: state_code type: keyword - name: state_name type: text - name: version type: text - name: ts_city type: timestamp -
Corresponding to this, add an additional column in which the primary key is identified as id in the indexer.base_sql section.
-
Reapply the Lakesearch Service by running the command below. It will update automatically, eliminating the need to delete the existing Service.
Expected output:
-
If no further issues are found, the Service runtime state will change to "running.”
dataos-ctl get -t service -n testingls -w public -r INFO[0000] 🔍 get... INFO[0000] 🔍 get...complete NAME | VERSION | TYPE | WORKSPACE | STATUS | RUNTIME | OWNER ------------|---------|---------|-----------|--------|-----------|-------------- testingls | v1 | service | public | active | running:1 | iamgroot
Depot type GCS not supported¶
If you deploy Lakesearch in a DataOS environment built on GCS, the Service will remain in a pending state, as Lakesearch is only supported in environments built on Azure or AWS.
Below is an example of the indexer logs when attempting to run a Lakesearch service in a GCS-based environment.
dataos-ctl log -t service -n ls-test-query-rewrite -w public -r
INFO[0000] 📃 log(public)...
INFO[0001] 📃 log(public)...complete
NODE NAME │ CONTAINER NAME │ ERROR
────────────────────────────────────────────────┼────────────────────────────────────┼────────
ls-test-query-rewrite-geh6-d-647487674f-7kgkk │ ls-test-query-rewrite-geh6-indexer │
-------------------LOGS-------------------
10:52AM INF pkg/config/config.go:126 > Loading config... file:///etc/dataos/config/lakesearch.yaml [success]
10:52AM INF cmd/main.go:390 > starting python gRPC server on :4090...
10:52AM WRN cmd/main.go:443 > Health check failed error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing: dial tcp 127.0.0.1:4090: connect: connection refused\""
10:52AM INF cmd/main.go:444 > Retrying... Waiting for Python gRPC server to be ready (1/100)
2025-03-06 10:52:43,434 - WARNING - No requirements file provided. Proceeding without installation.
2025-03-06 10:52:43,435 - INFO - Successfully imported ex_impl_query_rewriter
2025-03-06 10:52:43,435 - INFO - Server is running on address [::]:4090...
10:52AM INF cmd/main.go:440 > Python gRPC server is healthy and ready.
10:52AM DBG cmd/main.go:465 > embedder exists: false
10:52AM DBG cmd/main.go:481 > query rewriter exists: true
10:52AM INF pkg/source/connection.go:33 > Source setup... Source=datasets
10:52AM DBG pkg/source/connection.go:104 > [544.123225ms] << SET azure_transport_option_type = 'curl'; Source=datasets took=544.123225
10:52AM DBG pkg/source/connection.go:104 > [373.267µs] << SET extension_directory='/extensions'; Source=datasets took=0.373267
10:52AM DBG pkg/source/connection.go:104 > [3.798574ms] << LOAD httpfs; Source=datasets took=3.798574
10:52AM DBG pkg/source/connection.go:104 > [3.611732ms] << LOAD aws; Source=datasets took=3.611732
10:52AM DBG pkg/source/connection.go:104 > [242.912µs] << LOAD azure; Source=datasets took=0.242912
10:52AM DBG pkg/source/connection.go:104 > [3.136989ms] << LOAD iceberg; Source=datasets took=3.136989
10:52AM DBG pkg/source/connection.go:119 > [752.606µs] << SELECT extension_name FROM duckdb_extensions() WHERE loaded = true Source=datasets took=0.752606
10:52AM DBG pkg/source/duckdb.go:52 > aws
10:52AM DBG pkg/source/duckdb.go:52 > azure
10:52AM DBG pkg/source/duckdb.go:52 > httpfs
10:52AM DBG pkg/source/duckdb.go:52 > iceberg
10:52AM DBG pkg/source/duckdb.go:52 > jemalloc
10:52AM DBG pkg/source/duckdb.go:52 > json
10:52AM DBG pkg/source/duckdb.go:52 > parquet
10:52AM FTL pkg/source/duckdb.go:94 > depot type=gcs not supported
Unsupported Column¶
If the column used for filtering is mistakenly assigned a text data type, an error will occur when accessing the endpoint.
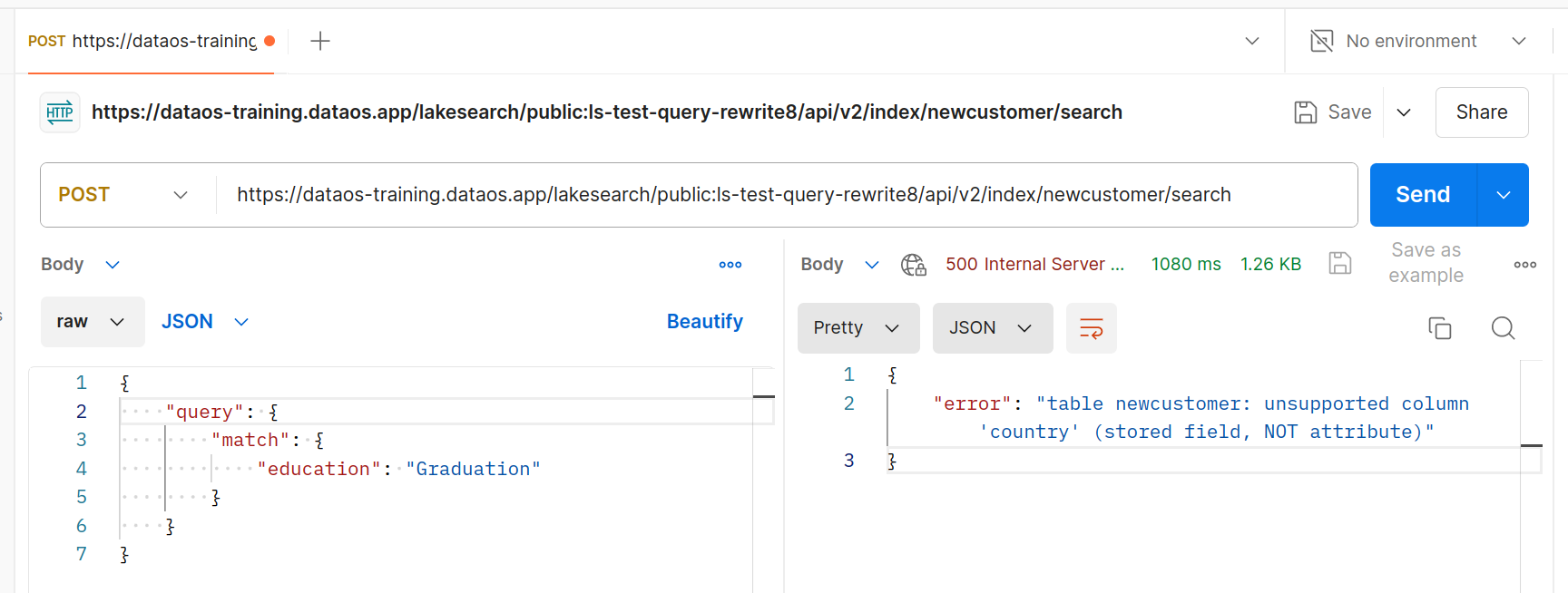
Steps to resolve
-
To fix this, delete that Service by executing the below command.
-
Update the data type.
columns: - name: customer_id type: bigint - name: birth_year type: bigint - name: id description: "mapped to customer_id" tags: - identifier type: bigint - name: education type: text - name: country # column by which data will be filtered type: keyword #updated data type - name: created_at type: timestamp -
Replace the
data_diranddirectorypaths with new ones. -
And re-apply the Service by executing the below command.
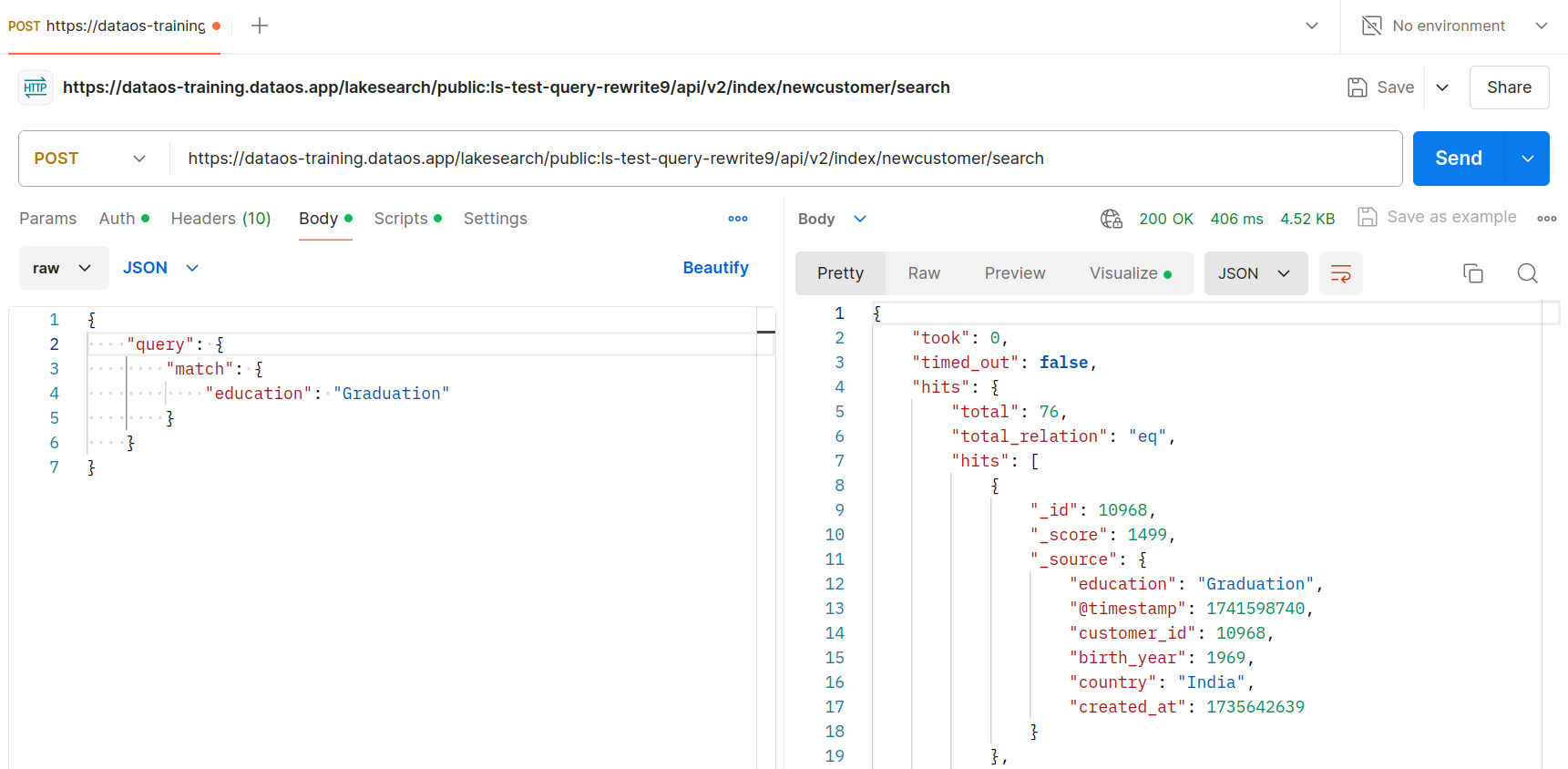
Now data can be filtered by "country":"India", as shown below.